







系列文章目录
第一章 Pandas 学习入门之pandas数据读取
第二章 Pandas 学习入门之pandas数据结构
第三章 Pandas 学习入门之pandas数据查询
第四章 Pandas 学习入门之pandas新增数据列
第五章 Pandas 学习入门之pandas数据统计函数
第六章 Pandas 学习入门之pandas处理缺失值
第七章 Pandas 学习入门之pandas数据排序
第八章 Pandas 学习入门之pandas字符串操作
第九章 Pandas 学习入门之pandas重要参数axis
第十章 Pandas 学习入门之pandas索引index用途
第十一章 Pandas 学习入门之pandas实现DataFrame的Merge
第十二章 Pandas 学习入门之pandas实现数据合并Concat
第十三章 Pandas 学习入门之pandas批量拆分Excel与合并Excel
第十四章 Pandas 学习入门之pandas分组聚合统计groupby
第十五章 Pandas 学习入门之pandas分层索引MultiIndex
第十六章 Pandas 学习入门之pandas数据转换函数map、apply、applymap
第十七章 Pandas 学习入门之pandas对每个分组应用apply函数
第十八章 Pandas 学习入门之pandas通过stack和pivot实现数据透视
随着人工智能的不断发展,数据分析这门技术也越来越重要,很多人都开启了学习数据分析,本文就介绍了pandas学习的基础内容。本章简单介绍了pandas通过stack和pivot实现数据透视,其中pivot方法相当于对df使用set_index创建分层索引,然后调用unstack。
前言
本章简单介绍了pandas通过stack和pivot实现数据透视,其中pivot方法相当于对df使用set_index创建分层索引,然后调用unstack。
提示:以下是本篇文章正文内容,下面案例可供参考
一、pandas实现数据透视

- 经过统计得到多维度指标数据
- 使用unstack实现数据二维透视
- 使用pivot简化透视
- stack、unstack、pivot的语法
二、经过统计得到多维度指标数据
非常常见的统计场景,指定多个维度,计算聚合后的指标。
以下是一个实例演示:
统计得到“电影评分数据集”,每个月份的每个分数被评分多少次:(月份、分数1~5、次数)
1.引入库
import pandas as pd
import numpy as np
%matplotlib inline2.读取数据
df = pd.read_csv("./ratings.dat")
df.head()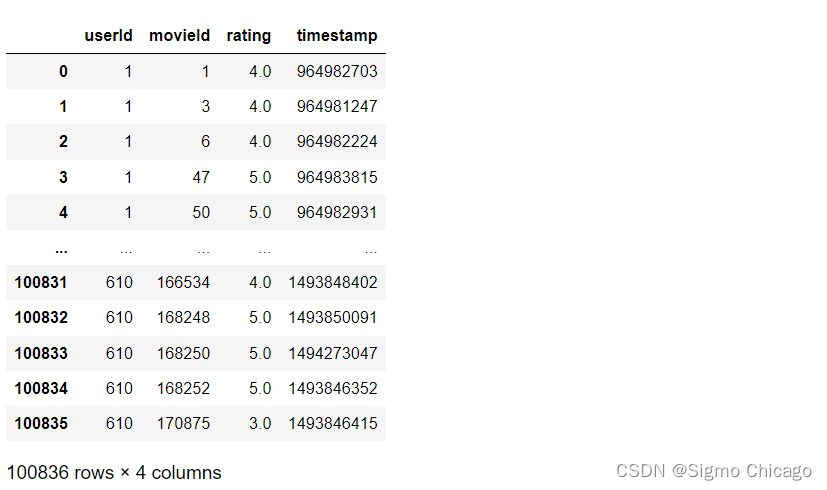
3.数据预处理
df["pdate"] = pd.to_datetime(df["timestamp"], unit='s')
df
pd.to_datetime()函数将 Unix 时间戳(以秒为单位)转换为日期时间对象。参数unit='s'指定了时间戳的单位为秒。将结果存储到 "pdate" 列中,可以方便地在 DataFrame 中处理日期时间相关的操作,比如分析时间序列数据、进行日期时间索引等。
df.dtypesuserId int64 movieId int64 rating float64 timestamp int64 pdate datetime64[ns] dtype: object
4.实现多维度数据统计
# 实现数据统计
df_group = df.groupby([df["pdate"].dt.month, "rating"])["userId"].agg(pv=np.size)
df_group.head(20)
代码详解:
- 使用
df["pdate"].dt.month获取日期时间列 "pdate" 中的月份,以及 "Rating" 列作为分组依据。- 使用
groupby()方法对上述两个列进行分组。- 对分组后的结果,使用
agg()方法进行聚合操作。- 在聚合操作中,针对 "UserID" 列,使用
np.size函数(numpy 库中的函数,用于计算数组的大小,即元素数量),并将结果存储到名为 "pv" 的新列中,表示用户数量。- 最终,
df_group将包含按月份和评分等级分组后的用户数量统计信息。
三、使用unstack实现数据二维透视
目的:想要画图对比按照月份的不同评分的数量趋势
df_stack = df_group.unstack()
df_stack
df_stack.plot()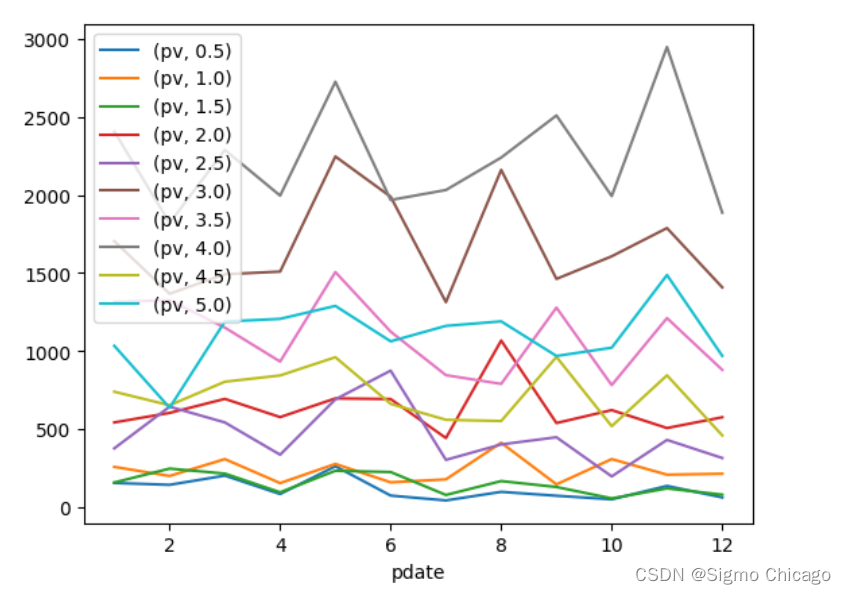
# unstack和stack是互逆操作
df_stack.stack().head(20)
四、使用pivot简化透视
df_group.head(20)
df_reset = df_group.reset_index()
df_reset.head(20)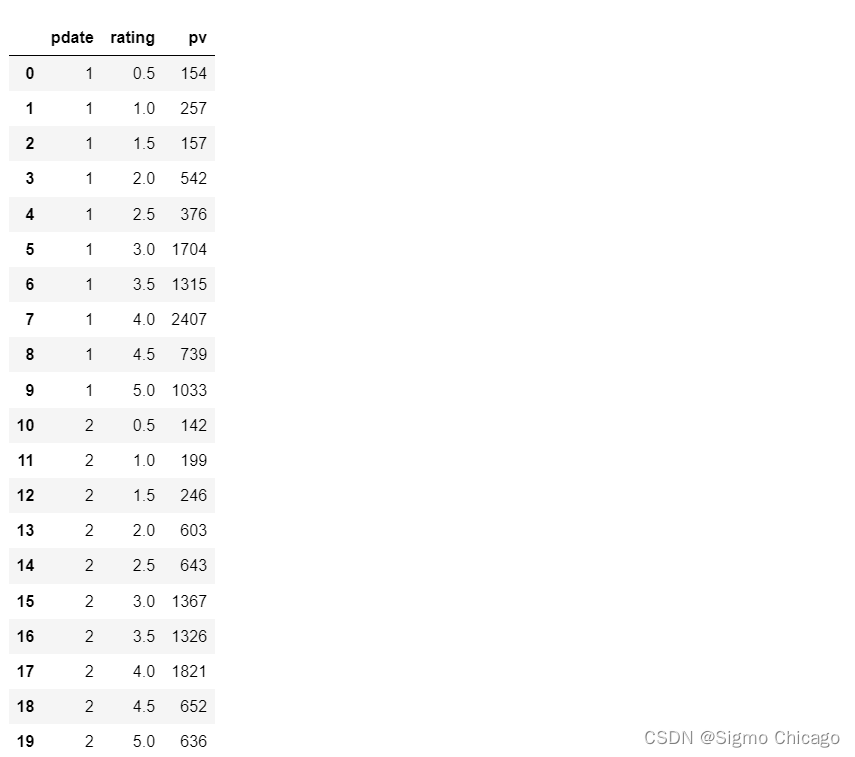
df_pivot = df_reset.pivot_table(index = "pdate",columns = "rating", values = "pv")
df_pivot.head(20)
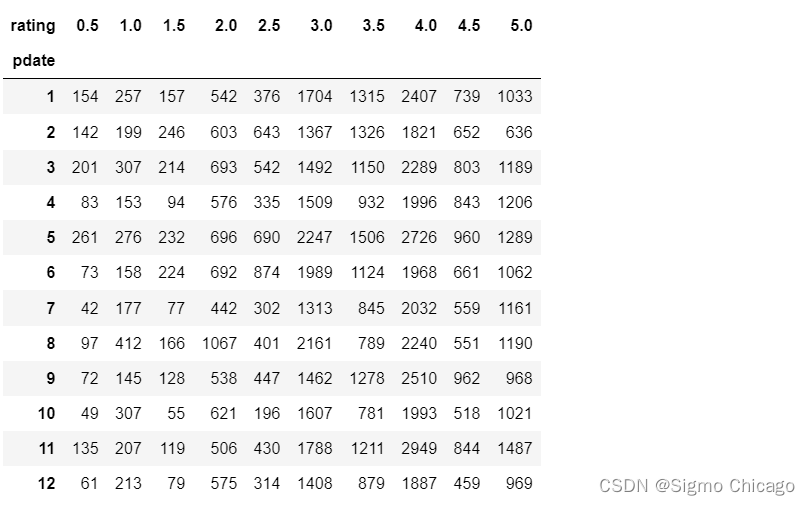
df_reset是原始的DataFrame;pivot_table(index = "pdate",columns = "rating", values = "pv")表示将原始DataFrame重新排列,其中:
"pdate"是指定要作为新DataFrame的行索引的列名,即Index;"rating"是指定要作为新DataFrame的列索引的列名,即column;"pv"是指定要填充新DataFrame的值的列名,即values。
df_pivot.plot()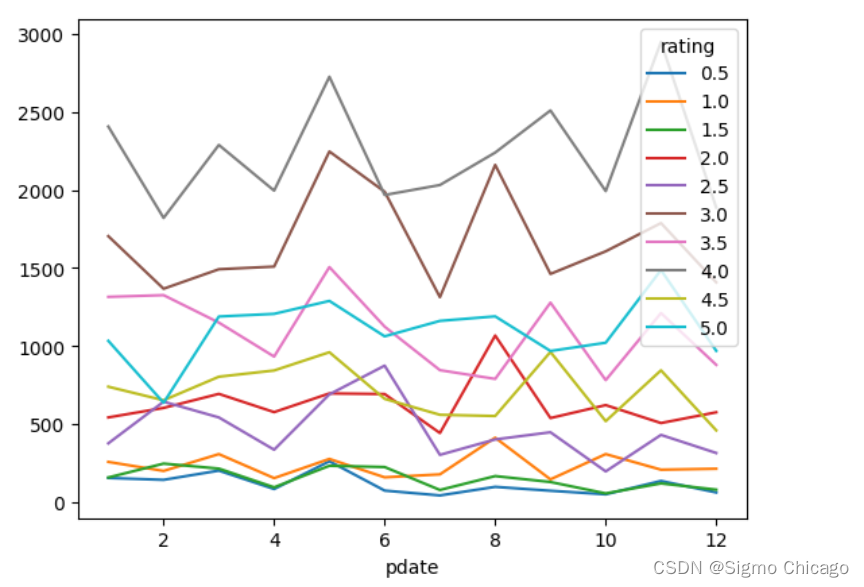
pivot方法相当于对df使用set_index创建分层索引,然后调用unstack
五、 stack、unstack、pivot的语法
1.stack

stack:DataFrame.stack(level=-1, dropna=True),将column变成index,类似把横放的书籍变成竖放
level=-1代表多层索引的最内层,可以通过==0、1、2指定多层索引的对应层
2.unstack

unstack:DataFrame.unstack(level=-1, fill_value=None),将index变成column,类似把竖放的书籍变成横放
3.pivot

pivot:DataFrame.pivot(index=None, columns=None, values=None),指定index、columns、values实现二维透视。
!! pivot方法相当于对df使用set_index创建分层索引,然后调用unstack !!
总结
提示:这里对文章进行总结:
随着人工智能的不断发展,数据分析这门技术也越来越重要,很多人都开启了学习数据分析,本文就介绍了pandas学习的基础内容。本章简单介绍了pandas通过stack和pivot实现数据透视,其中pivot方法相当于对df使用set_index创建分层索引,然后调用unstack。














 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









