







系列文章目录
第一章 Pandas 学习入门之pandas数据读取
第二章 Pandas 学习入门之pandas数据结构
第三章 Pandas 学习入门之pandas数据查询
第四章 Pandas 学习入门之pandas新增数据列
第五章 Pandas 学习入门之pandas数据统计函数
第六章 Pandas 学习入门之pandas处理缺失值
第七章 Pandas 学习入门之pandas数据排序
随着人工智能的不断发展,数据分析这门技术也越来越重要,很多人都开启了学习数据分析,本文就介绍了pandas学习的基础内容。本章简单介绍了pandas数据排列,包括Series升序降序排列,和DataFrame单列多列排序。
前言
本章简单介绍了pandas数据排列,包括Series升序降序排列,和DataFrame单列多列排序。
提示:以下是本篇文章正文内容,下面案例可供参考
一、pandas数据排序
pandas数据排序包括Series和DataFrame排序两种,具体操作见下文。
二、引入库 & 数据准备
1.引入库
代码如下(示例):
import pandas as pd2.数据准备
fpath = "./beijing_tianqi_2018.csv"
df = pd.read_csv(fpath)
# 替换掉温度的后缀℃
df.loc[:, "bWendu"] = df["bWendu"].str.replace("℃", "").astype('int32')
df.loc[:, "yWendu"] = df["yWendu"].str.replace("℃", "").astype('int32')
df
三、Series排序
Series的排序:
Series.sort_value(ascending=Ture,inplace=Flase) 参数说明:
- ascending: 默认为True升序排序,为False降序排序
- inplace: 是否修改原始Series
inplace=False情况下,sort_values()方法不会修改原始DataFrame,而是返回一个排序后的新DataFrame。如果你想直接在原始DataFrame上进行排序,可以设置inplace=True。
1.升序排列
# 升序排序
df["aqi"].sort_values()271 21
281 21
249 22
272 22
301 22
...
317 266
71 287
91 287
72 293
86 387
Name: aqi, Length: 365, dtype: int64
按"aqi"列进行升序排列,并且返回这些值的Series对象 。
2.降序排列
# 降序排序
df["aqi"].sort_values(ascending=False)86 387
72 293
71 287
91 287
317 266
...
249 22
301 22
272 22
271 21
281 21
Name: aqi, Length: 365, dtype: int64
按"aqi"列进行降序排列,并且返回这些值的Series对象 。
3.字符串排序
df["tianqi"].sort_values()225 中雨~小雨
230 中雨~小雨
197 中雨~雷阵雨
196 中雨~雷阵雨
112 多云
...
191 雷阵雨~大雨
219 雷阵雨~阴
335 雾~多云
353 霾
348 霾
Name: tianqi, Length: 365, dtype: object
字符串排序:
当你对字符串类型的列进行排序时,
pandas默认按照字典顺序(即按照字符串的字母顺序)进行排序。
这意味着字符串会按照从A到Z的顺序进行升序排序,相应地,如果设置为降序排序,则是从Z到A的顺序。
区分大小写:默认情况下,排序是区分大小写的,大写字母会被排序在小写字母之前。例如,"Apple"会在"apple"之前。
处理空值:在排序时,默认情况下
NaN(空值)会被排序到最后,无论是升序还是降序排序。
四、DataFrame排序
DataFrame的排序:
DataFrame.sort_values(by,ascending=True,inplace=False) 参数说明:
- by: 字符串或者List<字符串>,单列排序或者多列排序
- ascending: bool或者list,升序还是降序,如果是list对应by的多列
- inplace: 是否修改原始DataFrame
1.单列排序
# 升序排序
df.sort_values(by="aqi")

# 降序排序
df.sort_values(by="aqi",ascending=False)
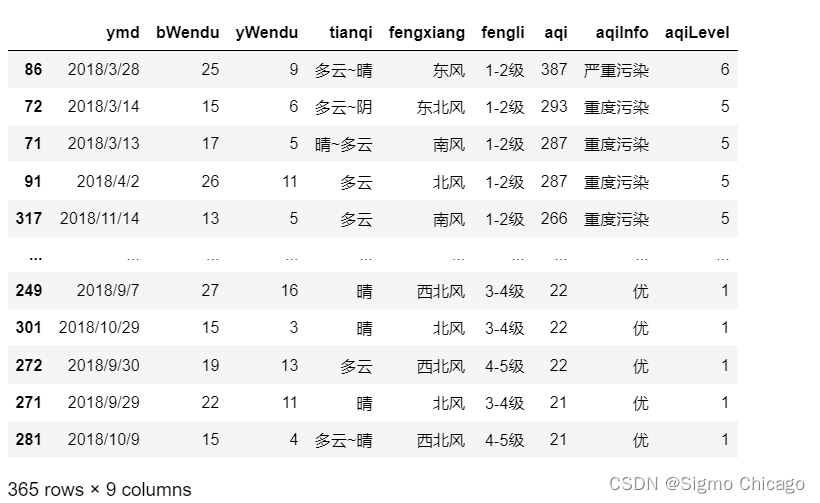
2.多列排序
# 按空气质量等级、最高温度排序,默认升序
df.sort_values(by=["aqiLevel", "bWendu"])

# 两个字段都是降序
df.sort_values(by=["aqiLevel", "bWendu"], ascending=False)
# 分别指定升序和降序
df.sort_values(by=["aqiLevel", "bWendu"], ascending=[True, False])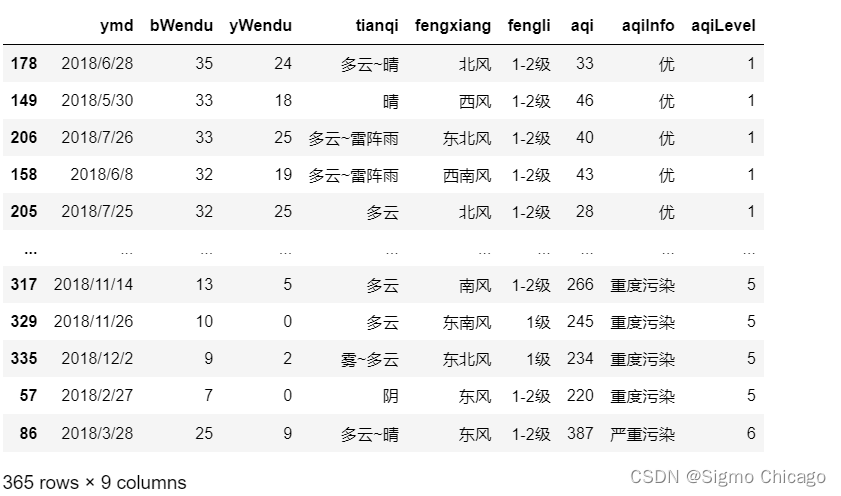
总结
提示:这里对文章进行总结:
随着人工智能的不断发展,数据分析这门技术也越来越重要,很多人都开启了学习数据分析,本文就介绍了pandas学习的基础内容。本章简单介绍了pandas数据排列,包括Series升序降序排列,和DataFrame单列多列排序。















 1592
1592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









