






容器技术到底解决了什么问题
先说结论:容器技术使应用软件具有可移植的能力
在应用容器化之前,当我们需要部署一个应用时,首先我们需要运维人员在部署环境中安装好应用依赖的所有软件、以及创建好应用需要的文件目录等。当我们需要给应用扩容时,运维人员也需要做同样的事情。另外当部署环境有多套时,比如同一个应用的实例可能一部分部署到了物理机上,一部分部署到了虚拟机上,一部分部署到了云服务上时,则需要运维人员一个个的进行环境的配置,可知这会耗用运维人员大量的精力。
另外更常见的是在微服务大行其道的今天,当你需要搭建一个业务服务时,其背后可能存在N多个应用,并且这些应用之间存在复杂的依赖调用关系,这时要想业务服务能正常部署,就需要运维人员耗费大量的人力来梳理各个应用之间的关系,以及配置各个应用的部署环境,这会导致运维人员是相当的苦逼。
而容器技术的出现,则彻底解放了运维人员,比如Docker可以将任何应用及其依赖打包成一个轻量级、可移植、自包含的docker容器镜像。由于docker镜像里面包含了应用所需要的所有依赖的软件,以及文件目录(因为在编写镜像的dockerfile时我们把应用所需要的所有依赖都定义好了,所以构建完镜像后镜像里面就已经存在了应用所需要的所有依赖),所以只要部署环境中安装了docker,那么该镜像可以在任何的部署环境(物理机、虚拟机、云服务)上无差别的进行一键部署。
有了容器技术之后,运维人员只需要创建一个包含应用和应用所需的依赖的容器镜像,然后再各个部署环境中安装好容器的运行时即可,最后就可以在各个部署环境中一键拉取容器镜像并启动容器,再也不需要每个环境都进行繁琐环境配置了。
容器VS虚拟机
容器是一种轻量级、可移植、自包含的软件打包技术,使应用程序可以在几乎任何地方运行。比如我们在自己本地的电脑上开发好应用后,把应用打包到容器内。然后就可以在不做任何改动的情况下在生产系统的虚拟机、物理服务器、云主机上运行。
容器不光指我们熟悉的Docker容器,还包含CoreOS的rkt等容器。为了保证容器生态的健康发展,保证不同容器之间能够兼容,包含Docker、CoreOS、Google在内的若干公司共同成立了一个叫Open Container Initiative(OCI)的组织,其目的是制定开放的容器规范。因为多种容器都是基于规范进行实现的,所以开发者可以无缝在各种容器实现之间的换,比如我之前使用的是Docker容器,但是后面如果切换到rkt容器,是很容易的事情。
虚拟化是云计算的基础。其使得在一台物理的服务器上可以跑多台虚拟机,虚拟机共享物理机的CPU、内存、IO硬件资源,但逻辑上虚拟机之间是相互隔离的。物理机我们一般称为宿主机(Host),宿主机上面的虚拟机称为客户机(Guest)。
容器由两部分组成:
(1)应用程序本身;比如我们发布一个web应用,那么这里指web应用程序本身
(2)应用的依赖: 比如应用程序需要的库(比如web应用依赖的配置文件以及依赖的jar包等)或其他软件容器在Host操作系统的用户空间中运行,与操作系统的其他进程隔离
传统的虚拟化技术,比如VMWare、KVM、Xen,目标是创建完整的虚拟机。为了运行应用,除了部署应用本身及其依赖(通常几十MB),还得安装整个操作系统(几十GB)。
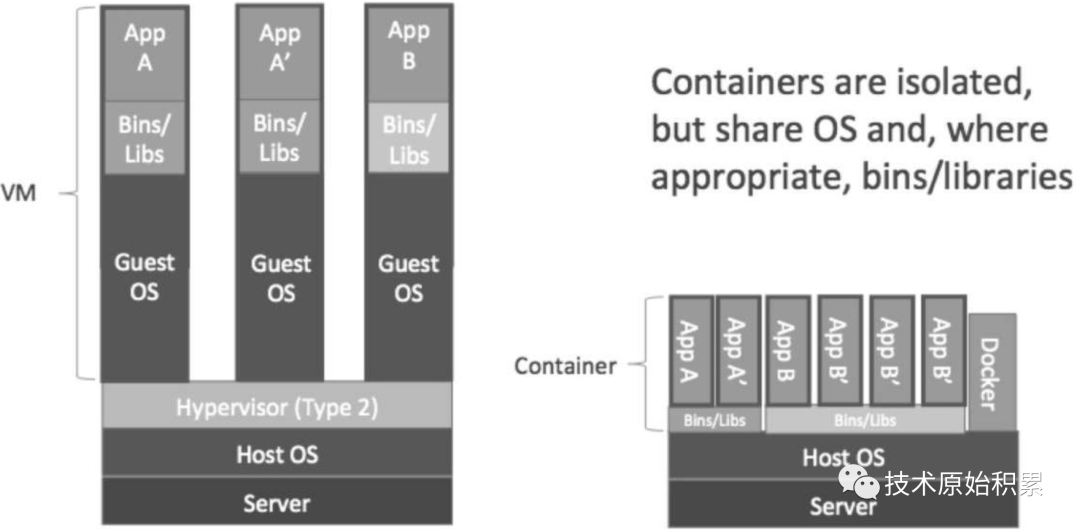
如上图可知:
所有的容器内包含各自独立的应用,但是所有容器共享同一个linux内核(备注:每个容器有自己的用户态的文件系统),这使得容器在体积上要比虚拟机小很多。另外启动容器不需要启动整个操作系统,所以容器部署和启动速度更快、开销更小,也更容易迁移。
所有的虚拟机包含各自独立的应用,但是每个虚拟机拥有自己的操作系统,所以相比容器其体积更大,并且启动虚拟机需要启动整个操作系统,所以部署和启动速度更慢。
Docker容器的本质
先说结论:Docker容器的本质是一个特殊的进程。
学过操作系统的大家应该知道进程其实是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。
比如我们电脑上运行的微信程序是一个进程,运行的开发工具(intellj idea)也是一个进程。其实在操作系统视角来看,处于运行时的Docker容器本身也是一个进程,只是这个进程比较特殊,下面我们就来说说他特殊在哪里
针对Linux容器来说,为了实现容器间资源隔离与限制,其对容器进程做了下面的处理
第一:其使用Linux提供的NameSpace技术来修改Docker容器运行时视图,实现每个容器有相互隔离的网络命名空间、进程空间等;比如你在Docker容器内查看进程列表,会发现容器自身是1号进程,其并看不到操作系统视角的其他进程,比如每个docker容器看到的都是各自独立的文件系统,相互之间不会影响。
第二:使用Linux提供的NameSpace技术仅仅解决了容器之间的隔离问题,但是还是没法控制每个容器对资源使用的限制问题,比如还是无法控制每个容器可以使用多少cpu和内存等资源。所以还需要使用Linux的Cgroup技术来实现容器对资源使用的限制。Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
总结:针对Linux内核的容器,比如Docker容器来说,其本质是一个特殊的进程。相比其他进程其特殊在基于NameSpace技术实现了进程的视图的隔离,基于Cgroup技术实现了资源使用的限制,从而实现了容器之间的资源隔离与限制。
Docker的架构设计
前面我们研究了Docker容器的本质是一个特殊的进程,那么这个特殊进程是如何创建、如何终止的那?也就是说是谁来管理这个容器进程的生命周期的那?
在mac操作系统中我们可以通过活动监视器来观察操作系统里面有哪些进程,以及通过活动监视器我们可以让指定的进程终止运行。活动监视器本身也是一个进程,其之所以可以管理进程,是因为其保存了所有进程的信息,比如进程的名称,进程PID等信息。
同理在Docker的设计中,也存在一个叫做Docker daemon的进程,Docker daemon运行在Docker host上,负责创建、运行、监控容器,以及负责构建、存储容器镜像。那么Docker daemon在Docker的设计中处于什么位置那?我们来看下Docker的架构:

如上图为Docker的架构图,可知其使用了Client/Server架构:
其中Docker daemon运行在Docker 主机上,负责创建、运行、监控容器,以及负责构建、存储容器镜像。
Docker客户端是为开发者提供的操作docker镜像和容器的客户端,比如我们最常使用的是docker 命令,使用docker build命令构建镜像,使用docker pull命令拉取镜像,使用docker run命令运行容器等。
Docker镜像本质为静态的文件,我们可以认为其是模板,基于其我们可以创建运行时的容器,关于Docker镜像里面包含了什么,我们在文章Docker镜像里到底是什么东西已经讲解过了。我们可以使用docker build来创建一个镜像,使用docker pull来拉取镜像
Docker 容器,即docker镜像在运行时的产物,我们可以使用docker run基于某个镜像启动一个容器运行,使用docker stop 命令来终止一个运行时的容器
Registry,存放docker镜像的仓库。
总结:
Docker采用了Client/Server架构,当我们启动Docker服务时,其实就启动一个daemon服务进程用来等待接受客户端的请求;当我们使用docker client的docker build命令构建一个镜像时,其实是把请求发送给了daemon服务,其收到请求后执行具体的镜像构建工作;当我们使用docker client的docker run命令启动一个容器时,其实是把请求发送给了daemon服务,其收到请求后获取对应的镜像内容,然后基于镜像启动一个对应的容器;
Docker daemon服务会负责维护每个容器进程的生命周期,会保存所有运行时容器的信息,以及容器进程标识等信息。所以当我们使用docker client启停容器时,其实是委托Docker daemon具体来执行容器进程的启停。
Docker镜像里到底有啥东西
Docker 容器的本质是一个特殊的进程,而 Docker 镜像则是容器运行所需的文件系统。可以说Docker容器是Docker镜像的实例,镜像是容器的模板。容器是在镜像的基础上运行的,当我们修改原镜像时,并不会对正在运行的容器产生影响。
那么Docker镜像里面到底包含哪些东西那?要想知道Docker镜像里面含有什么东西,我们需要先看看Docker镜像是怎么来的,最常见的构建Docker镜像的方式是通过编写Dockerfile。
FROM nginx
RUN echo '<h1>Hello, Docker!</h1>' > /usr/share/nginx/html/index.html如上是一个简单的Dockerfile文件,其中FROM指定基础镜像为 nginx
RUN命令执行shell命令向index.html 文件中写入Hello, Docker!
编写好Dockerfile后,我们可以执行命令:docker build -t nginx:v1 . 来构建镜像:
C02D9251MD6R :: ~/Downloads » docker build -t nginx:v1 . 1 ↵
[+] Building 9.3s (6/6) FINISHED
...
=> [internal] load metadata for docker.io/library/nginx:latest 3.8s
=> [1/2] FROM docker.io/library/nginx@sha256:b8f2383a95879e1ae064940d9a2 4.9s
...
=> [2/2] RUN echo '<h1>Hello, Docker!</h1>' > /usr/share/nginx/html/inde 0.4s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:e8b2a9dd1015eb395f7f18d3b4502050d9c4ab919d253 0.0s
=> => naming to docker.io/library/nginx:v1 0.0s如上可知,第一步是下载基础镜像nginx,第二步是执行echo命令修改ngnix镜像里面的index.html文件的内容
执行完毕build命令后,我们的docker镜像nginx:v1就在本地构建好嘞,我们可使用docker images查看:
C02D9251MD6R :: ~/Downloads » docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx v1 e8b2a9dd1015 9 minutes ago 142MB
httpd latest 6e794a483258 5 days ago 145MB
nginx latest a99a39d070bf 12 days ago 142MB如上可知 nginx v1的大小只有142MB,因为我们镜像里面只是修改了nginx镜像里面的内容,本身并没有新增任何大的东西,所以我们需要看看nginx镜像里面有什么,那我们可看看构建ngnix的Dockerfile(https://github.com/nginxinc/docker-nginx/blob/5ce65c3efd395ee2d82d32670f233140e92dba99/mainline/debian/Dockerfile)里面有什么:
#
# NOTE: THIS DOCKERFILE IS GENERATED VIA "update.sh"
#
# PLEASE DO NOT EDIT IT DIRECTLY.
#
FROM debian:bullseye-slim
LABEL maintainer="NGINX Docker Maintainers <docker-maint@nginx.com>"
ENV NGINX_VERSION 1.23.3
ENV NJS_VERSION 0.7.9
ENV PKG_RELEASE 1~bullseye
RUN set -x \
# create nginx user/group first, to be consistent throughout docker variants
&& addgroup --system --gid 101 nginx \
&& adduser --system --disabled-login --ingroup nginx --no-create-home --home /nonexistent --gecos "nginx user" --shell /bin/false --uid 101 nginx \
&& apt-get update \
&& apt-get install --no-install-recommends --no-install-suggests -y gnupg1 ca-certificates \
&& \
NGINX_GPGKEY=573BFD6B3D8FBC641079A6ABABF5BD827BD9BF62; \
found=''; \
for server in \
hkp://keyserver.ubuntu.com:80 \
pgp.mit.edu \
; do \
echo "Fetching GPG key $NGINX_GPGKEY from $server"; \
apt-key adv --keyserver "$server" --keyserver-options timeout=10 --recv-keys "$NGINX_GPGKEY" && found=yes && break; \
done; \
test -z "$found" && echo >&2 "error: failed to fetch GPG key $NGINX_GPGKEY" && exit 1; \
apt-get remove --purge --auto-remove -y gnupg1 && rm -rf /var/lib/apt/lists/* \
&& dpkgArch="$(dpkg --print-architecture)" \
&& nginxPackages=" \
nginx=${NGINX_VERSION}-${PKG_RELEASE} \
nginx-module-xslt=${NGINX_VERSION}-${PKG_RELEASE} \
nginx-module-geoip=${NGINX_VERSION}-${PKG_RELEASE} \
nginx-module-image-filter=${NGINX_VERSION}-${PKG_RELEASE} \
nginx-module-njs=${NGINX_VERSION}+${NJS_VERSION}-${PKG_RELEASE} \
" \
&& case "$dpkgArch" in \
amd64|arm64) \
# arches officialy built by upstream
echo "deb https://nginx.org/packages/mainline/debian/ bullseye nginx" >> /etc/apt/sources.list.d/nginx.list \
&& apt-get update \
;; \
*) \
# we're on an architecture upstream doesn't officially build for
# let's build binaries from the published source packages
echo "deb-src https://nginx.org/packages/mainline/debian/ bullseye nginx" >> /etc/apt/sources.list.d/nginx.list \
\
# new directory for storing sources and .deb files
&& tempDir="$(mktemp -d)" \
&& chmod 777 "$tempDir" \
# (777 to ensure APT's "_apt" user can access it too)
\
# save list of currently-installed packages so build dependencies can be cleanly removed later
&& savedAptMark="$(apt-mark showmanual)" \
\
# build .deb files from upstream's source packages (which are verified by apt-get)
&& apt-get update \
&& apt-get build-dep -y $nginxPackages \
&& ( \
cd "$tempDir" \
&& DEB_BUILD_OPTIONS="nocheck parallel=$(nproc)" \
apt-get source --compile $nginxPackages \
) \
# we don't remove APT lists here because they get re-downloaded and removed later
\
# reset apt-mark's "manual" list so that "purge --auto-remove" will remove all build dependencies
# (which is done after we install the built packages so we don't have to redownload any overlapping dependencies)
&& apt-mark showmanual | xargs apt-mark auto > /dev/null \
&& { [ -z "$savedAptMark" ] || apt-mark manual $savedAptMark; } \
\
# create a temporary local APT repo to install from (so that dependency resolution can be handled by APT, as it should be)
&& ls -lAFh "$tempDir" \
&& ( cd "$tempDir" && dpkg-scanpackages . > Packages ) \
&& grep '^Package: ' "$tempDir/Packages" \
&& echo "deb [ trusted=yes ] file://$tempDir ./" > /etc/apt/sources.list.d/temp.list \
# work around the following APT issue by using "Acquire::GzipIndexes=false" (overriding "/etc/apt/apt.conf.d/docker-gzip-indexes")
# Could not open file /var/lib/apt/lists/partial/_tmp_tmp.ODWljpQfkE_._Packages - open (13: Permission denied)
# ...
# E: Failed to fetch store:/var/lib/apt/lists/partial/_tmp_tmp.ODWljpQfkE_._Packages Could not open file /var/lib/apt/lists/partial/_tmp_tmp.ODWljpQfkE_._Packages - open (13: Permission denied)
&& apt-get -o Acquire::GzipIndexes=false update \
;; \
esac \
\
&& apt-get install --no-install-recommends --no-install-suggests -y \
$nginxPackages \
gettext-base \
curl \
&& apt-get remove --purge --auto-remove -y && rm -rf /var/lib/apt/lists/* /etc/apt/sources.list.d/nginx.list \
\
# if we have leftovers from building, let's purge them (including extra, unnecessary build deps)
&& if [ -n "$tempDir" ]; then \
apt-get purge -y --auto-remove \
&& rm -rf "$tempDir" /etc/apt/sources.list.d/temp.list; \
fi \
# forward request and error logs to docker log collector
&& ln -sf /dev/stdout /var/log/nginx/access.log \
&& ln -sf /dev/stderr /var/log/nginx/error.log \
# create a docker-entrypoint.d directory
&& mkdir /docker-entrypoint.d
COPY docker-entrypoint.sh /
COPY 10-listen-on-ipv6-by-default.sh /docker-entrypoint.d
COPY 20-envsubst-on-templates.sh /docker-entrypoint.d
COPY 30-tune-worker-processes.sh /docker-entrypoint.d
ENTRYPOINT ["/docker-entrypoint.sh"]
EXPOSE 80
STOPSIGNAL SIGQUIT
CMD ["nginx", "-g", "daemon off;"]如上可知nginx本身的构建基于基础镜像debian:bullseye-slim,nginx在基础镜像基础上大概新增了60M的内容,主要是拷贝的文件、创建临时目录、已经安装一些软件。
下面我么看看基础镜像debian:bullseye-slim(https://github.com/debuerreotype/docker-debian-artifacts/blob/64b13cf5860ac15c1d909abd7239516db9748fea/bullseye/slim/Dockerfile),其是比较常用的基础镜像,其Dockerfile如下:
FROM scratch
ADD rootfs.tar.xz /
CMD ["bash"]scratch是官方提供一个空镜像,其用来构建基础镜像比如(debian,busybox)或者体积超级小的镜像时候特别有用。
rootfs.tar.xz是用户空间的文件系统。
这里我们又必须要说下,Linux操作系统由内核空间和用户空间组成。Linux刚启动时会加载bootfs文件系统,之后bootfs会被卸载掉。用户空间的文件系统是rootfs,包含我们熟悉的 /dev、/proc、/bin等目录。对于基础镜像来说,底层复用用Host的kernel,镜像本身只需要包含rootfs就行了。而对于一个精简的OS, rootfs可以很小,只需要包括最基本的命令、工具和程序库就可以了。
所以Docker镜像里面其实并不包含linux内核文件,而仅仅是包含用户空间的文件系统rootfs,另外Docker镜像里面还包含开发者自己的应用文件,仅此而已。最后所有的Docker容器运行时是复用主机操作系统的内核的,但是每个Docker容器有自己独立的用户空间的文件系统。
Docker镜像的分层结构
类似面向对象技术中的继承特性,Docker允许我们基于现有镜像进行扩展,扩展出来的新镜像继承了原镜像里面的内容。
在前面docker镜像里面究竟包含了什么东西一文中我们说过docker镜像里面包含了用户态的文件系统和开发者的应用相关的文件。
其实用户态的文件系统rootfs是大多说应用都需要的,所以我们没必要在每个dockerfile里面都去添加它,我们可以把他放到基础镜像里面,然后所有应用只需要FROM这个基础镜像就可以了。
在docker中提供了镜像的分层结构,比如下面Dockfile文件:
FROM centos
RUN yum -y install wget
RUN yum -y install apache2
CMD ["bin/bash"]如上Dockerfile,FROM自centos基础镜像,centos里面只包含用户态的文件系统rootfs
然后再centos的基础上安装了 wget软件,以及apache2软件
最后容器启动时运行bash
那么上面Dockerfile构建出来的docker镜像长什么样那?如下图展示了构建后的分层结构的镜像:

如上可知新镜像是在base镜像centos上一层一层叠加生成的。每安装一个软件,就会在已有的镜像的基础上增加一层。
docker镜像之所以采用分层结构,主要是为了实现资源共享。比如我一个host上可能要运行多个docker化的应用,比如同时运行交易应用和商品应用,并且假设这些应用都是基于同一个基础镜像扩展而来。则基于镜像的分层结构,这个host上其实只需要存在一份基础镜像即可,不同的应用共享该基础镜像,从而也可以节省磁盘空间。
镜像分层可以让不同应用共享基础镜像,但是我们知道基础镜像里面包含了用户态的文件系统,那么如果某个容器修改了文件系统中的文件,那么会不会对其他容器造成影响那?
其实是不会的,上面我们讲解的docker镜像的分层结构其实是docker镜像静态文件的结构(我们成为镜像层)。如下图:其实在容器运行时又在docker镜像的分层结构上加了一个容器层的概念,每个容器共享docker镜像的镜像层,但是每个容器都自己独立的容器层,当某个容器需要对镜像层内容进行修改时是采用写时拷贝的策略把文件复制到自己的容器层进行修改。所以镜像层是只读的,容器层是可修改额。镜像层是多容器共享的,容器层是每个容器独占的

Docker容器与数据卷
由于每个容器都有自己用户态的文件系统,所以默认情况下当容器对自己的文件系统进行修改(比如新增文件,修改文件)时,其实修改的是自己容器自己的文件,而不是修改的宿主机的文件系统,所以当容器被删除后,在容器内增加或者修改的文件也就不见了。
为让容器内的数据可以被持久化到宿主机上,docker容器提供了数据卷的功能。当容器内需要持久化数据时,可以先在宿主机上创建一个卷(也就是一个文件目录),然后创建容器时把这个数据卷映射到容器内自己的文件系统目录内,这样当容器内添加文件时,其实是把文件添加到了宿主机上,由于卷是在宿主机上的,所以即使容器被删除了,容器创建的数据还是存在的。
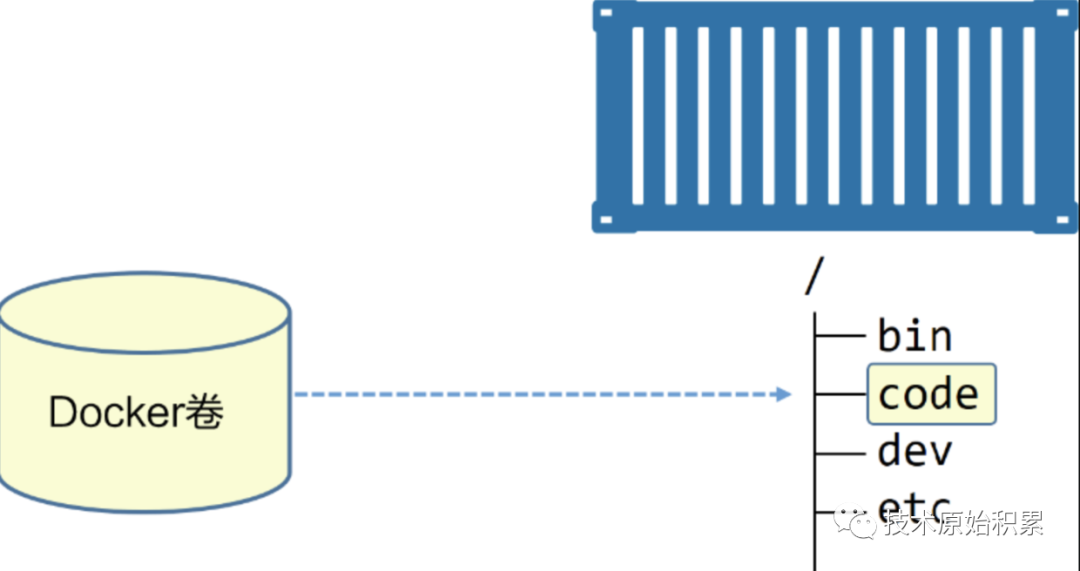
如上图,我们在宿主机上创建了一个docker卷,然后我们在创建容器时,就可以把这个数据卷映射到容器内文件系统的code目录。
我们可以使用下面命令,在宿主机上创建一个名为myvol的数据卷:
$ docker volume create myvol然后我们可以使用下面命令把myvol这个卷挂载到docker容器的code目录
$ docker container run -dit --name voltainer \
--mount source=myvol,target=/code \
alpine也就是说用户可以在宿主机上先创建卷,然后在创建容器时将卷挂载到容器上。数据卷会被挂载到容器文件系统的某个目录之下,任何写到该目录下的内容都会写到卷中。即使容器被删除,卷与其上面的数据仍然存在。
其实我们可以把卷到容器文件的映射比作实际的文件目录和软连接的之间的关系,当我们建立一个软连接后,我们可以通过软连接读写具体文件目录的内容,但是当我们删除软连接时,并不会删除实际的文件目录。也就是容器中的文件和卷各自拥有独立的生命周期,另外Docker不允许删除正在被容器使用的卷。
Docker网络
Docker网络主要解决下面几个问题:
同一个宿主机上的多个容器之间如何通信
容器与外部如何通信
跨主机容器如何通信
1.同一个宿主机上多容器之间的通信
同一个宿主机上多容器之间的网络可以分为下面几种网络:none网络、host网络、bridge网络、user-defined网络。其中前面三种网络,在安装docker时会自动创建,如下图我们可以通过命令docker network ls查看:

所谓none网络,其实就是没有网络。当一个容器挂在到该网络时,该容器只有用于本地LOOPBACK的网卡,没有其他可以与外部通讯的网卡。创建容器时时我们可以通过 --network=none指定使用none网络:docker run -it --newwork=none busybox

所谓host网络是指容器共享Docker 宿主机的网络栈。我们可以在创建容器时使用 --network=host指定使用host网络:docker run -it --network=host busybox

所谓bridge网络是指Docker安装时会创建的命名为docker0的Linux bridge。如果创建容器时不指定--network,则默认容器都会挂到docker0上。
所谓user-defined网络,是指用户可以根据业务需要创建user-defined网络,Docker提供三种user-defined网络驱动:bridge、overlay和macvlan。比如创建bridge网络示例:docker network create --driver bridge my_network

同一个宿主机上的多个容器容器要能通信,必须要有属于同一个网络的网卡。然后容器就可以通过IP交互了。具体做法是在容器创建时通过 --network指定同一个网络,或者通过docker network connect将现有容器加入到指定网络
2.容器与外部如何通信
首先我们先看在容器内是否可以访问外部网络,如下我们在容器内ping www.baidu.com可知是通的,其实这是通过NAT实现的

然后我们看外部如何访问容器网络,如下图我们启动了一个容器:

然后我们在浏览器里面访问http://localhost:8080/就可以看到容器内部启动的监听端口为80的服务。其实我们创建容器时,通过端口映射把宿主机上的8080端口映射到了容器内部的80端口,从而实现外部可以访问容器内部的服务。
3.跨主机容器通信
跨主机网络方案包括:
(1)docker原生的overlay和macvlan;
(2)第三方方案:常用的包括flannel、weave和calico
本文我们研究overlay,为支持容器跨主机通信,Docker提供了overlay driver,使用户可以创建基于VxLAN的overlay网络。VxLAN可将二层数据封装到UDP进行传输,VxLAN提供与VLAN相同的以太网二层服务,但是拥有更强的扩展性和灵活性
我们可以使用docker network create -d overlay my_overlay_network来创建一个overlay网络。一开始执行会报错如下:

这时我们需要执行下面命令,让当前节点成为管理节点,然后就可以创建覆盖网络:

然后我们就可以在创建容器时指定网络为该覆盖网络。
最后我们可以在另外一个机器2上执行下面命令让该机器成为机器1的管理节点:

然后再机器2也启动一个容器,并且指定网络为覆盖网络,则这两个容器就可以跨主机通信了。
戳下面阅读
👇
点亮再看哦👇














 733
733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









