







目录
MTEB 排行榜:https://huggingface.co/spaces/mteb/leaderboard
引言
万物皆可 Embedding。Embedding 用一个多维稠密向量来表示事物的多维特征,从而在一个连续的向量空间中刻画事物之间的相似性和差异性。这种表示方式不仅提高了计算效率,还增强了模型对数据内在结构和关系的理解能力。
向量模型在 RAG 系统中的作用
1. 对 query 和 私域知识 进行向量化表示
2. 动态更新知识库
3. 数据隐私和安全
Embedding 在 RAG 系统中扮演着至关重要的角色:如果 Embedding 模型在对私域知识进行向量化表示的过程中表现不佳,那么即使 RAG 系统在其他方面设计得当,最终效果也难以达到预期水平 。
为了让私域知识能在问答中被检索到,我们可以基于倒排和基于向量的方式构建知识库索引。倒排索引是一种基于关键词的精确性检索,但语义理解能力弱,而向量索引是基于文本向量的语义检索,可以捕捉文本的语义信息。一般情况下,我们会同时使用这两种检索方式。
有哪些性能不错的向量模型
OpenAI Embedding
JinaAI Embedding
https://huggingface.co/jinaai/jina-embeddings-v2-base-zh
BAAI/bge Embedding
https://huggingface.co/BAAI/bge-large-zh-v1.5
模型评测
面对这么多向量模型,我们如何衡量一种 Embedding 模型相对于其他模型的有效性呢?Hugging Face 推出了 MTEB(Massive Text Embedding Benchmark 大规模文本嵌入基准)测试框架,旨在评估文本 Embedding 模型在多种任务上的性能。它覆盖了 8 类任务和 58 个数据集,涉及 112 种语言,是目前最全面的文本嵌入评估基准之一。MTEB 提供了一个公开的排行榜,用于展示各个模型在不同任务上的表现。
MTEB 排行榜:https://huggingface.co/spaces/mteb/leaderboard
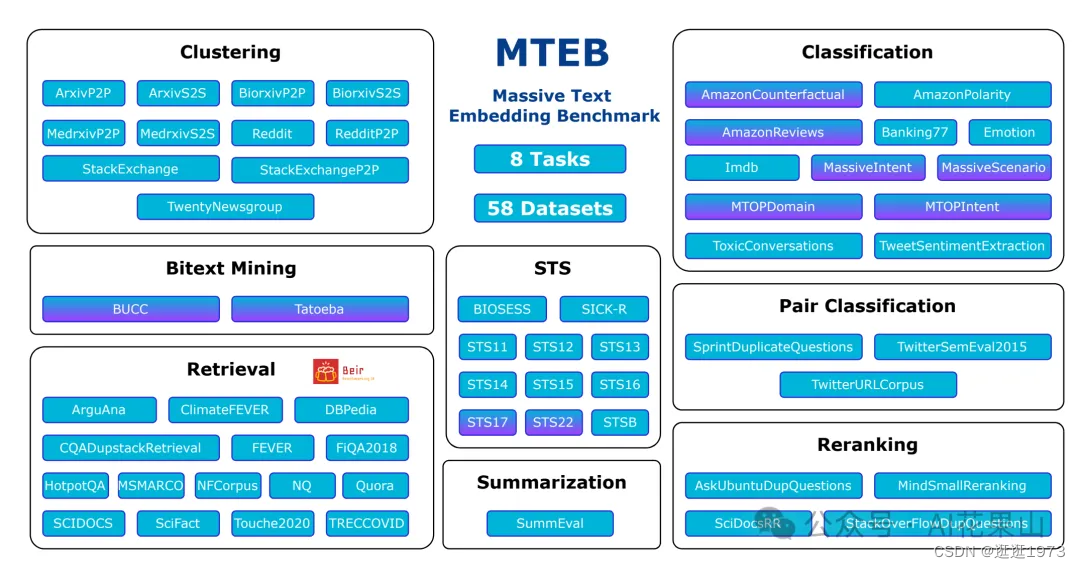
MTEB 包含以下任务类别,每个类别对应不同的评估指标和数据集:
-
1. 文本分类(Classification):如情感分析、意图分类等。
-
2. 聚类(Clustering):如将相似文本分为同一类。
-
3. 成对分类(Pair Classification):判断两个文本是否重复或具有相似含义。
-
4. 重排序(Reranking):根据查询重新排序相关和不相关的参考文本。
-
5. 检索(Retrieval):从大量文档中找到与查询相关的文档。
-
6. 语义文本相似性(STS):评估句子对之间的相似性。
-
7. 摘要(Summarization):评估机器生成摘要的质量。
如何 Finetune 向量模型
在特定领域,对向量模型进行 Finetune 的主要目标是提高 Recall@N (前 N 个检索结果中包含相关文档的比例)的准确率和优化正例与负例的 similarity 值域分布。
下面,我以 BAAI/bge-large-zh-v1.5 为例,看看如何基于私有领域数据进行 Finetune。
1. 安装 FlagEmbedding
首先,安装 FlagEmbedding 库:
pip install -U FlagEmbedding2. 数据准备
训练数据是一个 json 文件,其中每一行都是一个独立的 json 对象,如下所示:
{"query": "如何提高机器学习模型的准确性?", "pos": ["通过交叉验证和调参可以提高模型准确性。"], "neg": ["机器学习是人工智能的一个分支。"]}
{"query": "什么是深度学习?", "pos": ["深度学习是机器学习的一个子领域,涉及多层神经网络。"], "neg": ["数据科学是一门交叉学科。"]}其中,query 是问题,pos 是正样本列表,neg 是负样本列表,如果没有现成的负样本,可以考虑从整个语料库中随机抽取一些文本作为 neg。
将数据保存为 jsonl 文件,例如 finetune_data.jsonl 。
3. Hard Negatives 挖掘(可选)
Hard Negatives 是指那些在向量空间中与查询较为接近但实际上并不相关的样本。挖掘这些样本可以提高模型的辨别能力,提供 Embedding 质量。具体方法可以参考以下代码:
python -m FlagEmbedding.baai_general_embedding.finetune.hn_mine \
--model_name_or_path BAAI/bge-large-zh-v1.5 \
--input_file finetune_data.jsonl \
--output_file finetune_data_minedHN.jsonl \
--range_for_sampling 2-200 \
--negative_number 15其中,range_for_sampling 表示从哪些文档采样,例如 2-200 表示从 top2-top200 文档中采样 negative_number 个负样本 。
4. 训练
微调 Embedding 模型的命令如下:
torchrun --nproc_per_node {number of gpus} \
-m FlagEmbedding.baai_general_embedding.finetune.run \
--output_dir {path to save model} \
--model_name_or_path BAAI/bge-large-zh-v1.5 \
--train_data ./finetune_data.jsonl \
--learning_rate 1e-5 \
--fp16 \
--num_train_epochs 5 \
--per_device_train_batch_size {large batch size; set 1 for toy data} \
--dataloader_drop_last True \
--normlized True \
--temperature 0.02 \
--query_max_len 64 \
--passage_max_len 256 \
--train_group_size 2 \
--negatives_cross_device \
--logging_steps 10 \
--save_steps 1000 \
--query_instruction_for_retrieval "" 以上命令指定了训练参数,包括学习率、批次大小、训练轮次等,需要根据实际情况进行调整。
5. 模型合并(可选)
对通用模型进行微调可以提高其在目标任务上的性能,但可能会导致模型在目标域之外的一般能力退化。通过合并微调模型和通用模型,不仅可以提高下游任务的性能,同时保持其他不相关任务的性能。
为了将微调后的模型和原来的 bge 模型进行合并,我们需要先安装 LM_Cocktail,如下所示:
pip install -U LM_Cocktail合并代码参考如下:
from LM_Cocktail import mix_models, mix_models_with_data
# Mix fine-tuned model and base model; then save it to output_path: ./mixed_model_1
model = mix_models(
model_names_or_paths=["BAAI/bge-large-zh-v1.5", "your_fine-tuned_model"],
model_type='encoder',
weights=[0.5, 0.5], # you can change the weights to get a better trade-off.
output_path='./mixed_embedding_model')拓展阅读
• https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune
• https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail















 4598
4598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









