






一、回归模型的评价指标
1、RMSE,
1)均方根误差(root mean squared error,RMSE)
2)是观测值与真值偏差的平方和与观测次数m比值的平方根
3)是用来衡量观测值同真值之间的偏差
4)RMSE相当于L2范数,次数越高,计算结果就越与较大的值有关,而忽略较小的值,所以这就是为什么RMSE针对异常值更敏感的原因(即有一个预测值与真实值相差很大,那么RMSE就会很大)
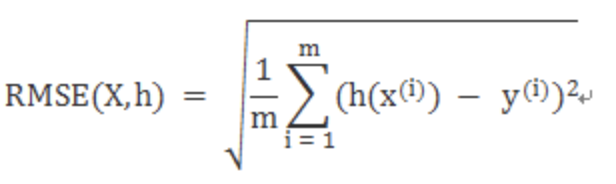
2、MSE
1)Mean Square Error 均方误差,公式:RMSE不开方即可
2) 真实值-预测值 然后平方之后求和平均
3)对比MAE,MSE可以放大预测偏差较大的值,可以比较不同预测模型的稳定性,应用场景相对多一点
3、MAE
1)平均绝对误差(mean absolute error,MAE)
2)是绝对误差的平均值
3)能更好地反映预测值误差的实际情况
4)MAE相当于L1范数
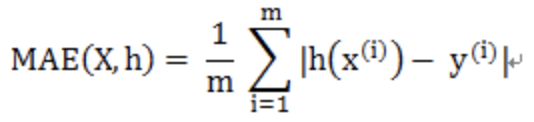
4、标准差
1)Standard Deviation,标准差
2)是方差的算数平方根
3)是用来衡量一组数自身的离散程度

scikit-learn中的各种衡量指标:
from sklearn.metrics import mean_squared_error #均方误差
from sklearn.metrics import mean_absolute_error #平方绝对误差
from sklearn.metrics import r2_score#R square
#调用
mean_squared_error(y_test,y_predict)
mean_absolute_error(y_test,y_predict)
r2_score(y_test,y_predict)
二、分类模型的评价指标
1、一般直接用损失函数(log_loss、 zero_one_loss、hinge_loss)就可以,但针对样本不均衡的情况,只用正确率不够,2、两类分类任务中更多评价指标:ROC/AUC、PR曲线、AP,3、多类分类(multi-class) and 多标签分类(mulit-label) and 多输出-多分类-多标签classification评价指标
1、损失函数
log_loss:负log似然损失 / logistic
zero_one_loss:错误率、正确率评价指标均与此有关
2、两类分类任务中更多评价指标
除常规的正确率(accuracy),错误率(error rate)外,还有经常使用的精度(PPV)、召回率(TPR)、需警率(FPR)

混淆矩阵(confusion matrix) 解析:
– TP:真正的正值(true positives)
– FP:假的正值(falsepositives)
– TN:真正的负值(true negatives)
– FN:假的负值(falsenegatives)
1)ROC曲线(纵坐标TPR 横坐标FPR),曲线越靠近左上角越好,AUC:曲线的面积,即越大越好。

2)PR曲线(纵坐标PPV 横坐标TPR),曲线越靠近又上角越好。
用于稀有事件检测,如目标检测、信息检索
负样本非常多,因此FPR很小,比较TPR和FPR不是很有信息(ROC曲线中只有左边很小一部分有意义),只讨论正样本时使用。

三、Scikit learn中评价指标的实现
Scikit learn 提供3 不同的 API,用于评估模型预测的性能:
1、 Estimatorscoremethod:模型自带的分数方法(score函数)提供一
个缺省的评估准则。
2、 Scoringparameter:采用交叉验证的模型评估工具
( model_selection.cross_val_score and model_selection.GridSearchCV、 以及一些xxxCV类 )有 scoring 参数(最佳参数为最大scoring模型 对应的参数)
3、Metricfunctions:metrics模块提供评价预测性能的功能 • Classificationmetrics,
• Multilabelrankingmetrics
• Regression metrics
• Clusteringmetrics
备注:
1、对分类模型,缺省的score函数返回的是正确率(Mean accuracy)
2、交叉验证中可设 置scoring参数, 规定模型性能的 评价指标
• 注意:scoring越 大的模型性能越好,所以如果采用损失/误差, 需要加neg,如 ‘neg_log_loss’

scoring可以自定义评价函数
当有些指标还需要额外的参数,而没有在scoring出现,或者某 个任务需要特殊的指标,scikit learn支持自定义scoring函数
eg1:
from sklearn.metrics import fbeta_score, make_scorer
ftwo_scorer = make_scorer(fbeta_score, beta=2) ##需要beta参数
from sklearn.model_selection import GridSearchCV
from sklearn.svm import LinearSVC
grid = GridSearchCV(LinearSVC(), param_grid={‘C’: [1, 10]}, scoring=ftwo_scorer)
eg2:
#定义特异性(specificity)计算函数
def specificity(y, y_hat): ##真值、预测值
#confusion matrix->a numpy.ndarray object
mc = metrics.confusion_matrix(y, y_hat) ##构造混淆矩阵
#’’negative’’ is the first row (index 0) of the matrix import numpy
res = mc[0,0]/numpy.sum(mc[0,:]) ##计算指标
return res
#将上述函数作为评价函数
specificite = metrics.make_scorer(specificity, greater_is_better = True)
#使用自定义的评价函数
#modele is the classifier fitted on the training set
sp = specificite(modele, X_test, y_test)
print (sp) # 0.915 = 184 / (184 + 17)
多类分类(multi-class) and 多标签分类(mulit-label) and 多输出-多分类-多标签classification评价指标 — 未完待续















 1508
1508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









