









目录
阿里巴巴一面
- 特征值怎么去除掉行业和市值的影响?去残差是什么意思?


- cnn的那个项目数据处理是怎么做的?
- 为什么用cnn来预测时序的模型?
- cnn这个项目里面有没有遇到什么困难?
- 讲一下q-learning的那个项目?
- 这个是预测一只股票的模型,能够用来预测多只股票吗?
- 讲一下随机森林的知识点?
- 随机森林的特征重要性怎么判断?
一个方法是计算不纯度,利用基尼指数或者信息增益分数的高低。第二个方法是计算袋外数据的得分情况。
利用随机森林对特征重要性进行评估 - xiezhen_zheng的..._CSDN博客
- 给定一个链表得到导数第k的结点
- 海量数据,无法存到内存中,怎么找到数据的中位数?
- 编程题:
- 字符串的全排列
- 能否不用递归的方法做出来?
阿里巴巴二面
oppo一面
- bagging 和 boosting的区别?
- grandient boosting一定在是在拟合残差吗?
gbdt 通过经验风险极小化来确定下一个弱分类器的参数。具体到损失函数本身的选择也就是L的选择,有平方损失函数,0-1损失函数,对数损失函数等等。如果我们选择平方损失函数,那么这个差值其实就是我们平常所说的残差。
这样说的话,如果损失函数不是平方损失函数的话就不是在拟合残差吗?
- GBDT的目标函数和损失函数?
- GBDT用的都是回归树,损失函数一般是平方损失函数。具体的计算过程可以看机器学习算法GBDT的面试要点总结-上篇
- lr的目标函数和损失函数?
- lr的目标函数和损失函数感觉是同一个呀,不知道面试官到底要我回答什么。。目标函数就是极大似然估计,加上log变换后我们能够得到累加的形式,再用梯度下降法来进行求解就好了。
- lr加上l1或者l2的正则化之后可以用SGD吗?
- 看面试官的意思好像l1是不能用SGD的,但是具体原因我不太知道。在网上找了点资料如下:不知道还有人可以解释的么
但对于这种带 L1 正则的最大熵模型,直接采用标准的随机梯度下降法(SGD)会出现效率不高和难以真正产生稀疏性等问题。

- 函数连续的定义,怎么判断一个函数是否可导?
首先判断函数在这个点x0是否有定义,即f(x0)是否存在;其次判断f(x0)是否连续,即f(x0-), f(x0+), f(x0)三者是否相等;再次判断函数在x0的左右导数是否存在且相等,即f‘(x0-)=f'(x0+),只有以上都满足了,则函数在x0处才可导。
- 词向量Word2Vec的原理
笨鸟科技
一面:
1.堆排序的实现
2.将数据排序,奇数在前,偶数在后
3.top k值
4.二叉树的深度广度遍历(核心算法有哪些)
5.最大堆是什么二叉树
6.决策树的分裂方法
7.熵的定义
8.TensorFlow怎么进行调试
9.batch-normalization的作用是什么?(除了过拟合)好像说从剃度的角度,加快收敛的角度答
最主要的作用时加快收敛,避免梯度消失,其次是防止过拟合。
10.cnn的核心点
11.word2vec的原理,霍夫曼树和层softmax的关系
深入学习二叉树(三) 霍夫曼树 - 简书
12.word2vec的整个流程
13.反向传播
京东二面:
- ctr和相关性的区别,用ctr来评判相关性是否合理
- SVM的核函数,满足什么条件才能作为核函数?多项式核函数和高斯核函数的具体原理
需要满足点积, 多项式核函数的公式为: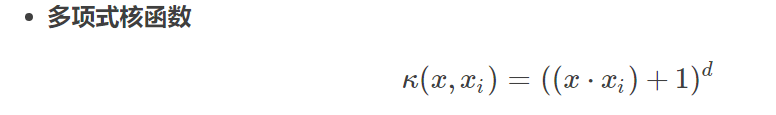 ,能够实现高维特征的扩展
,能够实现高维特征的扩展
- lstm可以避免梯度爆炸吗?一个用户的历史数据进行训练,可以用来评估另外一个用户吗?
- 防止梯度爆炸的方法?
- 预训练加微调 - 梯度剪切、权重正则(针对梯度爆炸) - 使用不同的激活函数 - 使用batchnorm - 使用残差结构 - 使用LSTM网络
这篇文章从梯度爆炸的原因一直讲到解决方法,总结的比较到位:https://blog.csdn.net/qq_25737169/article/details/78847691
- bn可以用来解决梯度爆炸的问题吗?
Batchnorm是深度学习发展以来提出的最重要的成果之一了,目前已经被广泛的应用到了各大网络中,具有加速网络收敛速度,提升训练稳定性的效果,Batchnorm本质上是解决反向传播过程中的梯度问题。batchnorm全名是batch normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化保证网络的稳定性。
具体的batchnorm原理非常复杂,在这里不做详细展开,此部分大概讲一下batchnorm解决梯度的问题上。具体来说就是反向传播中,经过每一层的梯度会乘以该层的权重,举个简单例子:
正向传播中f2=f1(wT∗x+b) f_2=f_1(w^T*x+b)f ,反向传播式子中有w ww的存在,所以w ww的大小影响了梯度的消失和爆炸,batchnorm就是通过对每一层的输出规范为均值和方差一致的方法,消除了w ww带来的放大缩小的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉倒了非饱和区。
http://blog.csdn.net/qq_25737169/article/details/79048516
- bn的原理,它的哪几种?bn在测试的时候怎么使用
常见normalization的方法:bn, LN, 关于LN和BN的区别请看https://zhuanlan.zhihu.com/p/54530247
在训练阶段,我们使用每个batch数据的统计信息(如:均值、标准差等)来对训练数据进行规范化,而在测试阶段,我们使用训练时得到的统计信息的滑动平均来对测试数据进行规范化。
- 协同过滤算法
- 协同过滤算法冷启动问题
- L1和L2正则化的公式以及作用?
L1正则化主要是产生稀疏性,L2正则化主要是防止过拟合,L1也可以防止过拟合, 能够使数值变小。
L1产生稀疏性的解释是他L1的投影和损失函数的交点在轴坐标上面。
算法题:
A, B有多少个相同的字串,最长字串是多少?
追一科技:
fasttext的原理?
bert的position embedding怎么生成?
transformer的注意力机制?
AUC的具体做法?
word2vec词太多,onehot之后的维度很高怎么办?
SVM的优化目标和限制条件是什么?
算法题
在一个排序数组中,找出给定target第一次出现的位置,如果没有出现则返回-1
这个题目最主要的考察点在于二分之后找到了这个点该怎么办?如果说找到这个点之后直接左移,那这样复杂度最坏是n/2, 这个时候应该再继续移动右指针,再进行二分。
如何防止softmax函数上溢出(overflow)和下溢出(underflow)














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









