







文章目录
在计算广告和推荐系统中,CTR预估(click-through rate)是非常重要的一个环节,以根据CTR预估的点击率判断是否推荐。
在进行CTR预估时,除了单特征外,往往要对特征进行组合。FM算法就是特征组合的常用做法之一。
FM
问题描述:如何解决利用多阶特征中遇到的稀疏矩阵问题
论文:Rendle S. Factorization machines[C]//2010 IEEE International conference on data mining. IEEE, 2010: 995-1000.
背景
以广告分类问题为例,根据用户与广告位的一些特征,来预测用户是否会点击广告:
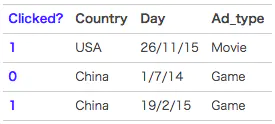
clicked是分类值,表明用户有没有点击该广告。1表示点击,0表示未点击。而country,day,ad_type则是对应的特征。对于这种categorical特征,一般都是进行one-hot编码处理。
将上面的数据进行one-hot编码以后,就变成了下面这样 :

Feature fields:Country=USA和Country=China是Feature field1,Day=26/11/15、Day=1/7/14和Day=19/2/15是Feature field2,Ad_type=Movie和Ad_type=Game是Feature field3。
因为是categorical特征,所以经过one-hot编码以后,不可避免的样本的数据就变得很稀疏。由此可见,数据的稀疏性,是我们在实际应用场景中面临的一个非常常见的挑战与问题。
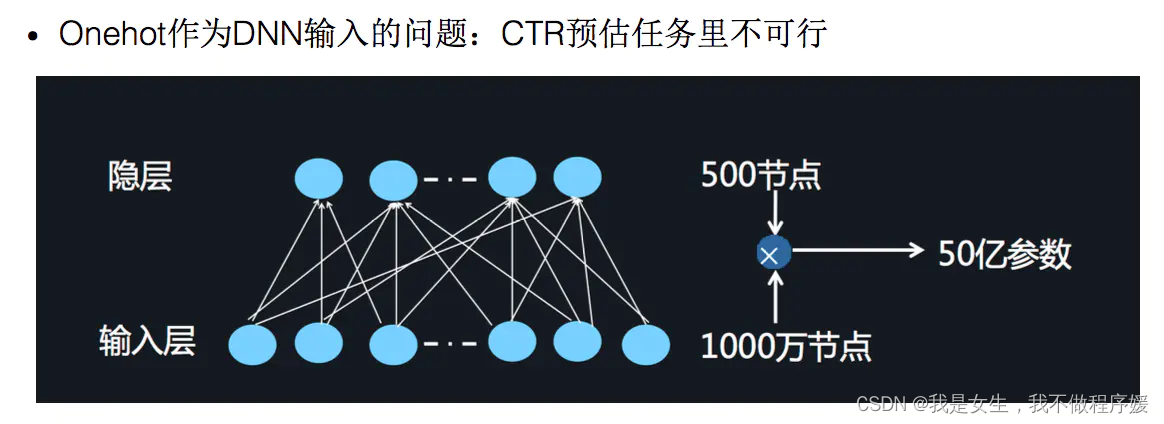
再看一个典型的电影评分的例子,为了预测不同用户对不同电影的评分,我们使用以下5种(5-filled)特征
- 当前用户信息,可以理解为用户ID,如下图蓝框所示。
- 当前预测电影的评分信息,可以理解为电影ID。
- 当前用户对其他电影的评分特征。
- 时间,对应评分的日期
- 用户最近评分过的一步电影
特征组合
普通的线性模型,我们都是将各个特征独立考虑的,并没有考虑到特征与特征之间的相互关系。但实际上,大量的特征之间是有关联的。最简单的以电商为例,一般女性用户看化妆品服装之类的广告比较多,而男性更青睐各种球类装备。那很明显,女性这个特征与化妆品类服装类商品有很大的关联性,男性这个特征与球类装备的关联性更为密切。如果我们能将这些有关联的特征找出来,显然是很有意义的。

与线性模型相比,FM的模型就多了后面特征组合的部分。
Challenge&解决方案
由于特征过于稀疏,满足
x
i
,
x
j
x_i,x_j
xi,xj同时不为0的情况很少,导致
w
i
j
w_{ij}
wij无法通过训练得出。
为了求出
w
i
j
w_{ij}
wij,对每一个特征分量
x
i
x_i
xi引入辅助向量
v
i
=
(
v
i
1
,
v
i
2
.
.
.
v
i
k
)
v_i=(v_{i1},v_{i2}...v_{ik})
vi=(vi1,vi2...vik),其维度k<<n。然后用
v
i
v
j
T
v_iv_j^T
vivjT对
w
i
j
w_{ij}
wij进行求解。



通过化简,可以使用SGD对参数进行求解。
-
为什么拆分成 v i v_i vi有效?
-
从数据量上来说原来是 n ∗ n n*n n∗n的参数量,现在是 n ∗ k n*k n∗k的参数量,k<<n。时间复杂度可以化简为O(kn)(k是自己设定的,如16、32);
-
特征之间可以相互影响,即使之间没有直接组合的例子,也可以通过迭代优化寻找潜在的关系。
例子: 以电影评分为例,我们要估计用户A和电影ST的关系w(A&ST)以更好地预测y,但从已有的训练样本来看,这两者并没有共现,因此学习出来的w(A&ST)=0。而实际上,A和ST应该是存在某种联系的,从用户角度来看,A和B都看过SW,而B还看过ST,说明A也可能喜欢ST。而通过向量v来表示用户和电影,任意两两之间的交互都会影响v的更新,从前面举的例子就可以看过,A和B看过SW,这样的交互关系就会导致v(ST)的学习更新。即,参数因子化使得 x h x i x_h x_i xhxi的参数和 x h x j x_hx_j xhxj 的参数不再相互独立,因为有了 x h x_h xh特征关联。因此我们可以在样本系数的情况下相对合理地估计FM的二次项参数。 -
V和W之间的关系?=>分解机的由来
-
-
多阶特征交叉

由于三重特征的交叉往往没有意义,而且会过于稀疏,因此我们一般情况下只会使用d=2的情况。
Wide&Deep Model
问题描述:在推荐系统中如何确保命中的准确性和泛化性
论文:Wide & Deep Learning for Recommender Systems
背景
- wide模型(以LR为代表)以高维特征(一阶原始特征+二阶叉乘特征等)作为输入,利用交叉特征可以高效的实现记忆能力(即“记忆” 历史数据中曾共同出现过的特征对),达到精准的目的。但是容易过拟合,无法捕捉训练数据中没有出现过的特征对,模型泛化能力较差。
- DNN通过将高维特征embedding到低维特征,确保了模型的泛化能力(在损失一定表达能力的前提下),但会推荐出很多无关内容,准确性不能得到保证。
Challenge:如何满足既要又要的问题?
解决方案
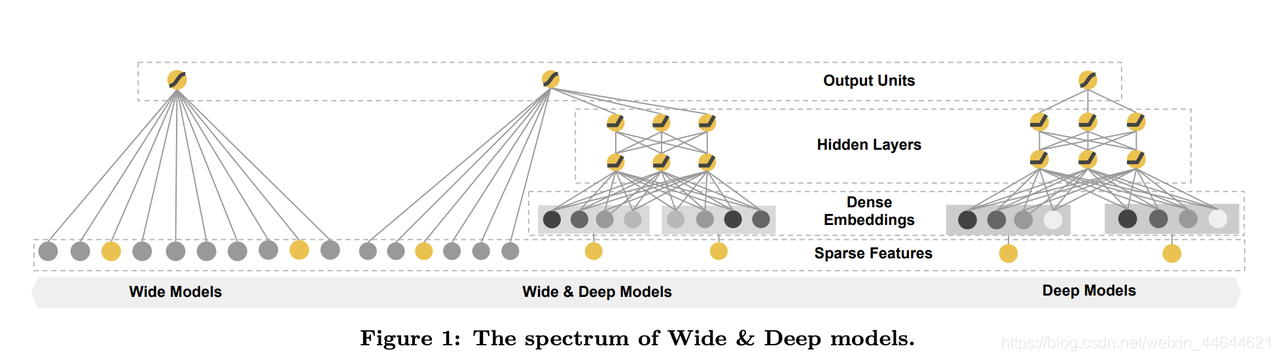
Wide部分
基础的线性模型,表示为
y
=
w
T
[
x
,
ϕ
(
x
)
]
+
b
y=w^T[x,\phi(x) ]+b
y=wT[x,ϕ(x)]+b。x和
ϕ
(
x
)
\phi(x)
ϕ(x)表示sparse基础特征和叉乘特征(只采用sparse特征,如果dense特征要参与叉乘可以进行分桶离散化操作)。交叉特征可以捕捉到特征间的交互,起到添加非线性的作用。交叉特征可表示为:

Deep部分
前馈网络模型。sparse特征(如ID)首先转换为低维稠密向量(维度通常O(10)~O(100)),然后和dense特征一起作为网络输入。
向量随机初始化,经过最小化损失函数训练模型。激活函数采用Relu。前馈部分表示如下:

其中,Deep部分包含一个Embedding Layer:由于用于CTR的输入一般是极其稀疏的。因此需要重新设计网络结构。具体实现中为,在第一层隐含层之前,引入一个嵌入层来完成将高维稀疏向量压缩到低维稠密向量。

假设我们的k=5,首先,对于输入的一条记录,同一个field 只有一个位置是1,那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层该神经元相连的五条线的权重,即vi1,vi2,vi3,vi4,vi5。这五个值组合起来就是我们在FM中所提到的Vi。在FM部分和DNN部分,这一块是共享权重的,对同一个特征来说,得到的Vi是相同的。
联合模型
Wide和Deep部分的输出通过加权方式合并到一起,并通过logistic loss function进行最终输出。

*联合训练vs集成训练:
- 联合训练时模型误差会同时反馈到wide和deep部分,同时进行参数更新; 集成训练是每个模型单独训练,在infer阶段将结果汇合;
- 集成训练的每个模型都足够好才有利于后面的汇合,会因此每个模型的model;
- size相对较大;而联合训练的wide只需要做一小部分特征叉乘弥补deep的不足,而不需要一个full-size的wide model。
损失函数
logistic loss:
L
=
−
1
N
∑
(
y
~
,
y
)
∈
D
(
y
l
o
g
y
^
+
(
1
−
y
)
l
o
g
(
1
−
y
^
)
)
L = -\frac{1}{N}\sum_{(\tilde{y},y)\in D}(ylog\hat{y}+(1-y)log(1-\hat{y}))
L=−N1(y~,y)∈D∑(ylogy^+(1−y)log(1−y^))
实验结果
实验场景:Google play商店的APP推荐,这里的wide&deep对应精排模型。

- dense特征被CDF归一到[0,1]
- sparse特征会有一个过滤阈值,至少在训练集中出现m词才会被加入
- sparse特征被映射到32维Embedding,和原始dense特征共1200为作为NN输入
- wide部分只用了一组叉乘特征,即被推荐的APP×用户下载的APP
- 模型线上更新时采用“热启动”,即使用上次的Embedding和模型参数进行初始化。
实验结果:

DeepFM
问题描述:如何根据原始数据进行自动的融合低阶和高阶的特征
论文:DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
背景
- Wide&Deep 模型需要手工的设计wide部分的特征来确保模型的准确性,我们能否通过机器自动的学习这部分特征=>FM
- 在上述的基础上,我们可以使得FM Layer和我们的DNN部分共享相同的特征输入
解决方案

FM部分的详细结构如下:
数值型特征不参与特征交叉。因为特征交叉的操作是在两个embedding向量间进行的。但如果通过分桶操作把连续性特征离散化再加入embedding层,就可以参与交叉。

FM的输出公式:

Deep部分:

优点:
- DeepFM模型包含FM和DNN两部分,FM模型可以抽取low-order特征,DNN可以抽取high-order特征。无需Wide&Deep模型人工特征工程。
- 由于输入仅为原始特征,而且FM和DNN共享输入向量特征,DeepFM模型训练速度很快。
- 不同field特征长度不同,但dense embedding的输出维度相同;
- 利用FM模型的隐特征向量V作为DNN网络权重初始化来获得子网络输出向量;
DeepCross
问题描述:如果利用特征bit之间的高阶叉乘特征
论文:Deep & Cross Network for Ad Click Predictions
背景
Wide&Deep 仍然需要人工地设计特征叉乘。面对高维稀疏的特征空间、大量的可组合方式,基于人工先验知识虽然可以缓解一部分压力,但仍需要不小的人力和尝试成本,并且很有可能遗漏一些重要的交叉特征。FM可以自动组合特征,但也仅限于二阶叉乘。能否告别人工组合特征,并且自动学习高阶的特征组合呢?Deep & Cross 即是对此的一个尝试。
解决方案
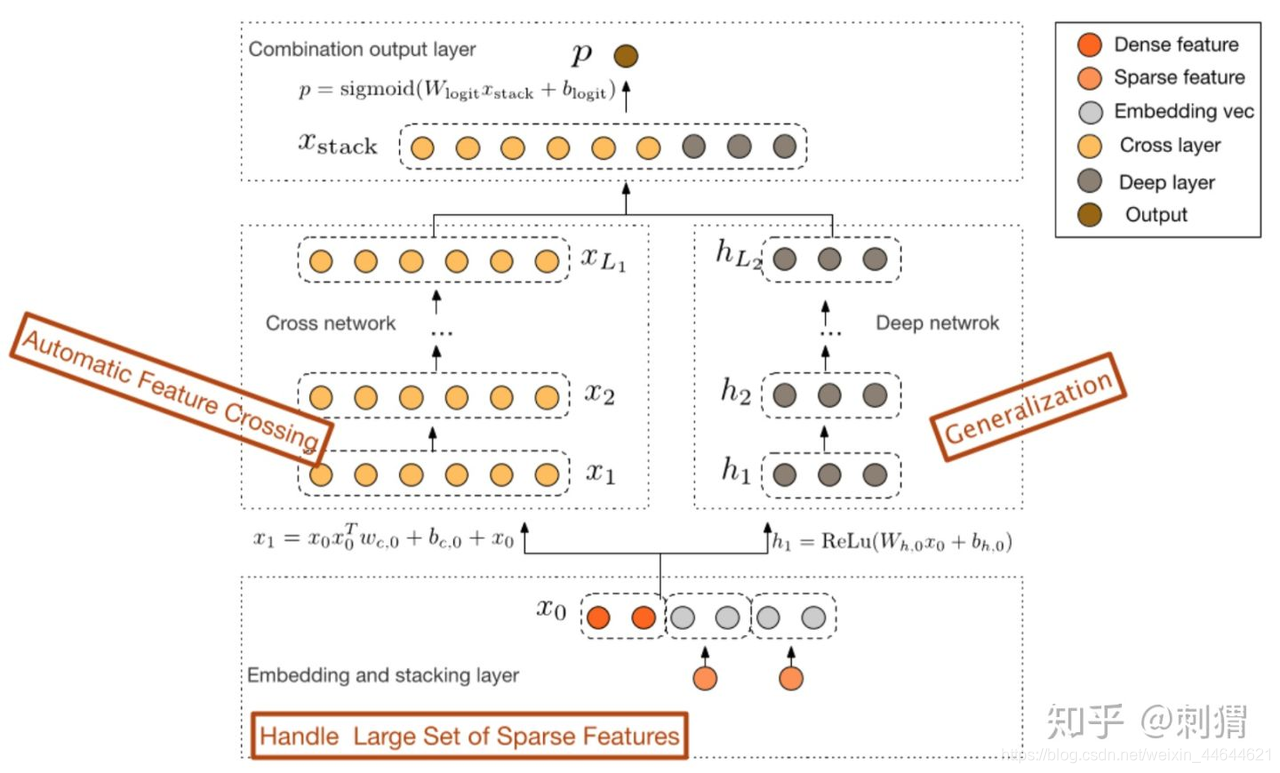
cross:

(reference: 向量点乘、叉乘与矩阵点乘、叉乘)
三维向量叉乘公式:

- 有限高阶:叉乘阶数由网络深度决定 L c = > L c + 1 L_c=>L_c+1 Lc=>Lc+1
- 自动叉乘:Cross输出包含了原始特征从一阶(即本身)到 L c + 1 L_c+1 Lc+1阶的所有叉乘组合,而模型参数量仅仅随输入维度呈线性增长 2 ∗ d ∗ L c 2*d*L_c 2∗d∗Lc
- 参数共享:不同叉乘项对应的权重不同,但并非每个叉乘组合对应独立的权重(指数数量级), 通过参数共享,Cross有效降低了参数量。此外,参数共享还使得模型有更强的泛化性和鲁棒性。例如,如果独立训练权重,当训练集中 x i ≠ 0 & x j ≠ 0 x_i \neq 0 \& x_j \neq 0 xi=0&xj=0这个叉乘特征没有出现 ,对应权重肯定是零,而参数共享则不会,类似地,数据集中的一些噪声可以由大部分正常样本来纠正权重参数的学习。类似于FM中V的设计。
xDeepFM
问题描述:如何利用特征field之间的高阶叉乘特征
论文:xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
背景
- Deep Cross最大的问题在于他没有field的概念,实际我们操作特征融合可能更关心的是field级别的融合和叉乘。
- 在DeepFM中,我们都将每个field映射到了相同的维度,在这篇文章中也一样。
解决方案
xDeepFM=Linear+CIN+Plain DNN

Field Embedding:
If the field is univalent, the feature embedding is used as the field embedding. Take the above instance as an example, the embedding of feature male is taken as the embedding of field gender. If the field is multivalent, the sum of feature embedding is used as the field embedding.
推荐领域主要关注sparse特征,通常用one-hot表示。
如果某field只有一个特征,则直接用该特征的embedding表示;
如果某field有多个特征,则用这些特征的embedding之和表示field embedding。
CIN:Compressed Interaction Network

其中,
X
0
∈
R
m
∗
d
X^0∈R^{m*d}
X0∈Rm∗d,表示m个field,每个向量d维;
X
l
∈
R
H
l
∗
d
X^l∈R^{H_l*d}
Xl∈RHl∗d,表示第l层有
H
l
H_l
Hl个向量,每个d维。
具体实现可参考下面的这个公式,CIN第k层的输出有
H
k
H_k
Hk个维度为D的特征向量。每个特征向量表示前k-1层和第0层向量两两之间的Hadamard乘积加权求和。
(Hadamard积:<a1,b1,c1>·<a2,b2,c2>=<a1a2,b1b2,c1c2>)
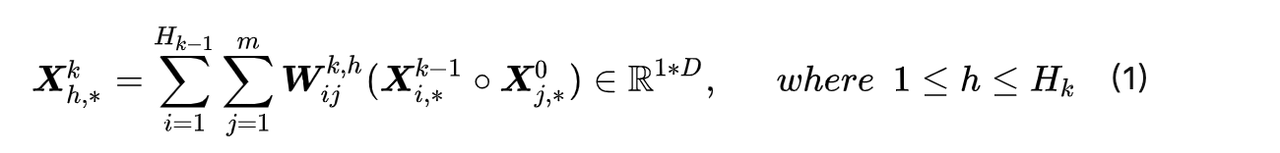
上式的X均为一行,即 l 层第一行与0层第一行, l 层第一行与0层第二行… l 层第
H
l
H_l
Hl行与0层第m行加权求和,求出l+1层的某一行。
优势是什么?CIN与DCN中Cross层的设计动机是相似的,Cross层的input也是前一层与输出层。至于为什么这么搞,CIN 保持了DCN的优点:有限高阶、自动叉乘、参数共享。
CIN和DCN的区别:
- Cross是bit-wise的,而CIN 是vector-wise的;
- CIN将每一阶的特征都作为了输出
DeepFEFM
论文:https://arxiv.org/abs/2009.09931
背景
FM模型的feature interactions
=
v
i
T
v
j
x
i
x
j
=v_i^Tv_jx_ix_j
=viTvjxixj,其中
v
i
、
v
j
v_i、v_j
vi、vj对应于feature
x
i
、
x
j
x_i、x_j
xi、xj,而没有利用field信息;
FFM(Field-Awared Factorization Machine)加入了field的考量,feature interactions
=
v
i
,
F
(
j
)
T
v
j
,
F
(
i
)
x
i
x
j
=v^T_{i,F(j)}v_{j,F(i)}x_ix_j
=vi,F(j)Tvj,F(i)xixj,但造成了参数量巨大,complexity过高的缺点。
解决方案
DeepFEFM(Field-Embedded Factorization Machine)构造feature interaction= v i T W F ( i ) , F ( j ) v j x i x j v^T_i W_{F(i),F(j)}v_jx_ix_j viTWF(i),F(j)vjxixj,其中 W F ( i ) , F ( j ) W_{F(i),F(j)} WF(i),F(j)是一个对称矩阵,学习field i、j之间的关系。
其模型结构与DeepFM基本类似,主要区别在于DeepFM的feature interaction= v i T v j x i x j v^T_i v_jx_ix_j viTvjxixj,其中i、j直接表示field维度;另外DeepFM的DNN输入只使用了单个feature embedding,而DeepFEFM将feature interaction也加入DNN的input,从而提高模型表现。原文内容是:
The DNN part of DeepFM takes input only the input feature embeddings, but we additionally also input FEFM generated interaction embeddings. Our ablation studies in Section 4 show that these FEFM interaction embeddings are key to the lift in performance achieved by DeepFEFM.

AutoInt
论文:AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
背景
DeepFM,Deep cross network,xDeepFM等深度学习推荐算法旨在构造高阶交叉特征上,但是这些方法有一些缺陷:
- fully-connected neural networks 抽取的高阶特征在学习multiplicative feature interactions上是inefficient的;
- 隐式学习特征交叉的方式缺乏可解释性。
论文的贡献在于:
提出利用Multi-head Self-Attention 机制显式学习高维特征交叉的一种方法,提高了可解释性。
基于self-attentive neural network提出一种新的方法,可自动学习高维特征交叉,有效提升了CTR预估的准确率。
解决方案
模型结构
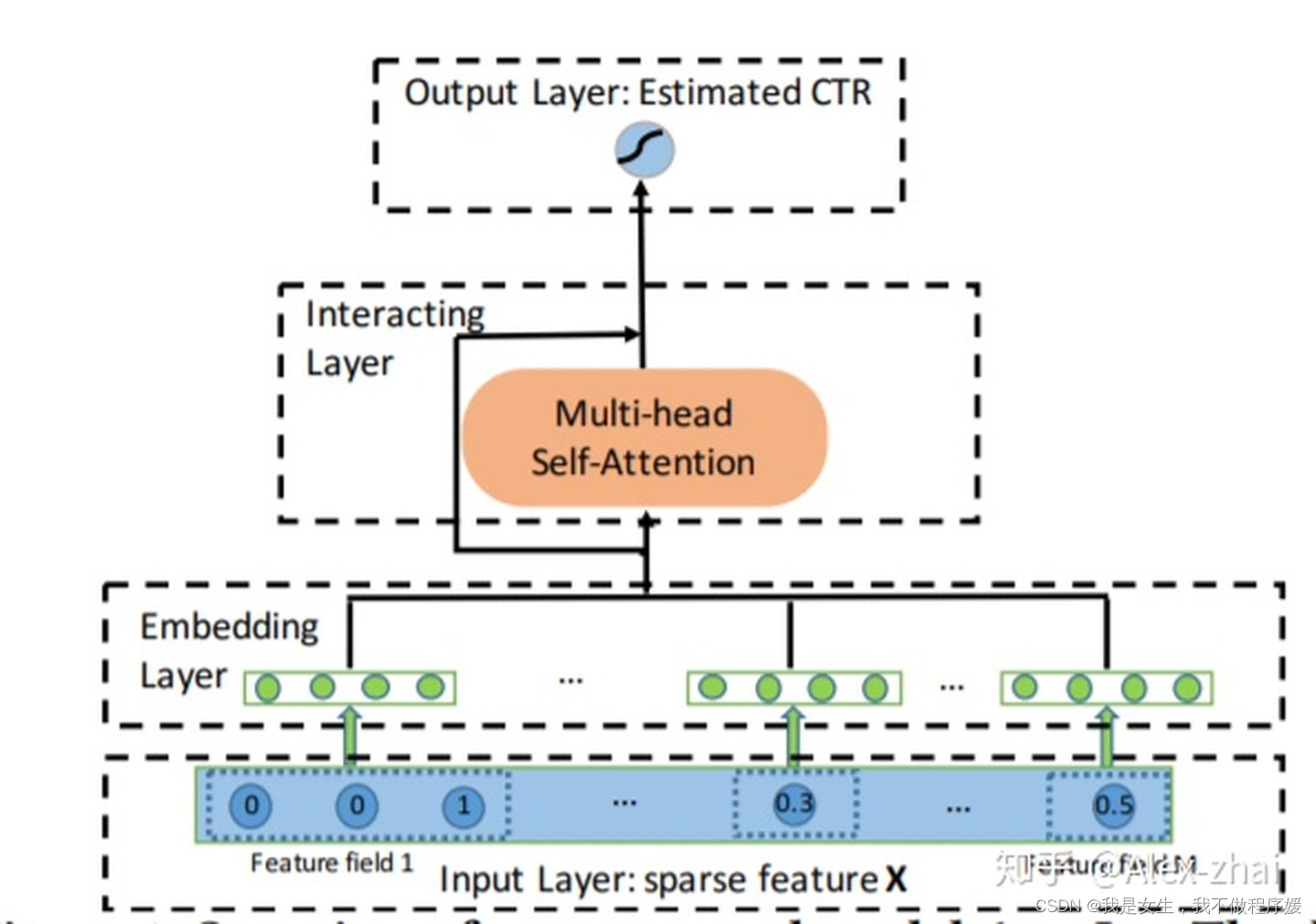
Input Layer
x = [x1; x2; …; xM],其中M表示总共的feature fields的数目,xi表示第i个特征。
如果xi是离散的,就是one-hot向量,如果是连续的,就是一个scalar。
Embedding
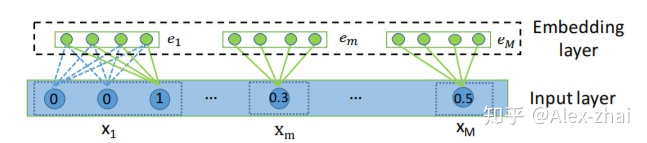
离散型特征的embedding是一个矩阵,而连续型特征的embedding是一个向量。
Interacting Layer
这一层使用了multi-head attention,
α
m
,
k
(
h
)
\alpha_{m,k}^{(h)}
αm,k(h)表示attention head h下,特征m和特征k的相似权重:

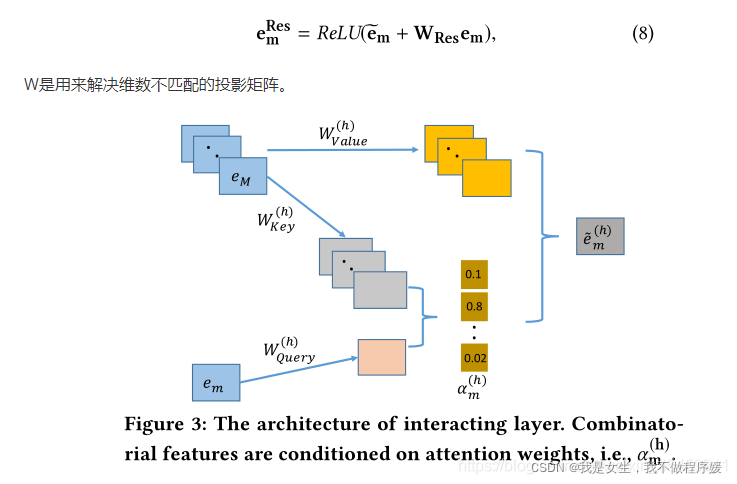
Output Layer
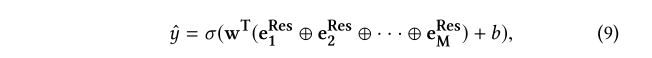
Training
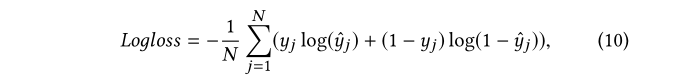
AutoDis
背景
ctr算法主要由两部分构成:feature embedding和feature interaction。目前为止,前几种算法的重点集中在了特征的interaction方面,本文重点对embedding方法进行了改进。
神经网络输入特征分为category型和numerical型,对category型特征,一般使用label coding(将类别映射为整数)后embedding look-up的方法(将稀疏的one-hot向量乘以矩阵转化为稠密向量);对于numerical特征,有如下几种方法:
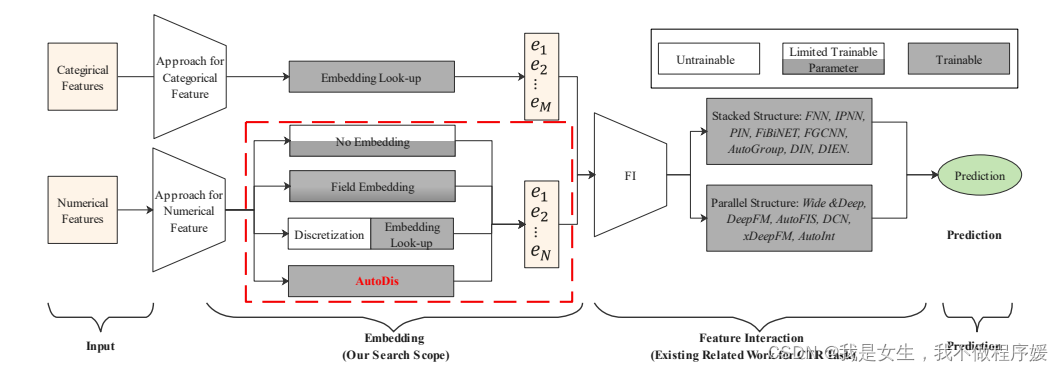
- no embedding:直接使用数值本身,问题:low capacity(文中的capacity可理解为每个特征最终被embedding出的维度);
- field embedding:对属于同一个field的多个数值型特征,使用同一个向量进行embedding,问题:intra-field feature线性相关,丢失部分表达力,也是low capacity的;
(On the contrary,一种naive思想是对同一个field中每个特征分别设置embedding向量,问题在于huge parameters and insufficient training for low-frequency features.) - discretization+embedding look-up:先使用其他方法(如分箱)对连续型特征离散化,再使用category型特征的embedding方法,问题:两部分割裂,不能保证离散方法对该问题的合理性;
- 本文提出的端到端的AutoDis方法:使用meta-embedding,使离散化结果可以根据训练目标调整,端到端训练。
解决方案
AutoDis可以分为三个模块:
一、训练meta-embedding
为每个field训练一个meta-embedding:
M
E
∈
R
H
×
d
ME\in{R^{H×d}}
ME∈RH×d,field内的所有feature共享该
M
E
ME
ME,
该field中特征可被离散化为
H
H
H个bucket,每行是一种embedding结果,最终目标为d维向量。
二、Automatic Discretization
首先使用automatic discretization函数
d
j
A
u
t
o
(
⋅
)
d_j^{Auto(·)}
djAuto(⋅)将x转化为
x
~
\tilde{x}
x~:

再用softmax将
x
~
\tilde{x}
x~转化为
x
^
\hat{x}
x^,这里
x
^
h
\hat{x}^h
x^h表示x被离散化到第h个bucket的概率:

三、Aggregation function
可以选择max、top-k sum、weighted-average等方法,根据
x
^
\hat{x}
x^和
M
E
ME
ME对最终向量表示进行计算,如选择
x
^
h
\hat{x}^h
x^h最大值对应
M
E
ME
ME的行,或对top-k个行加权求和等。
效果对比
设一个field有m个feature,使用离散化方法可分为4个类别,目标向量d维。
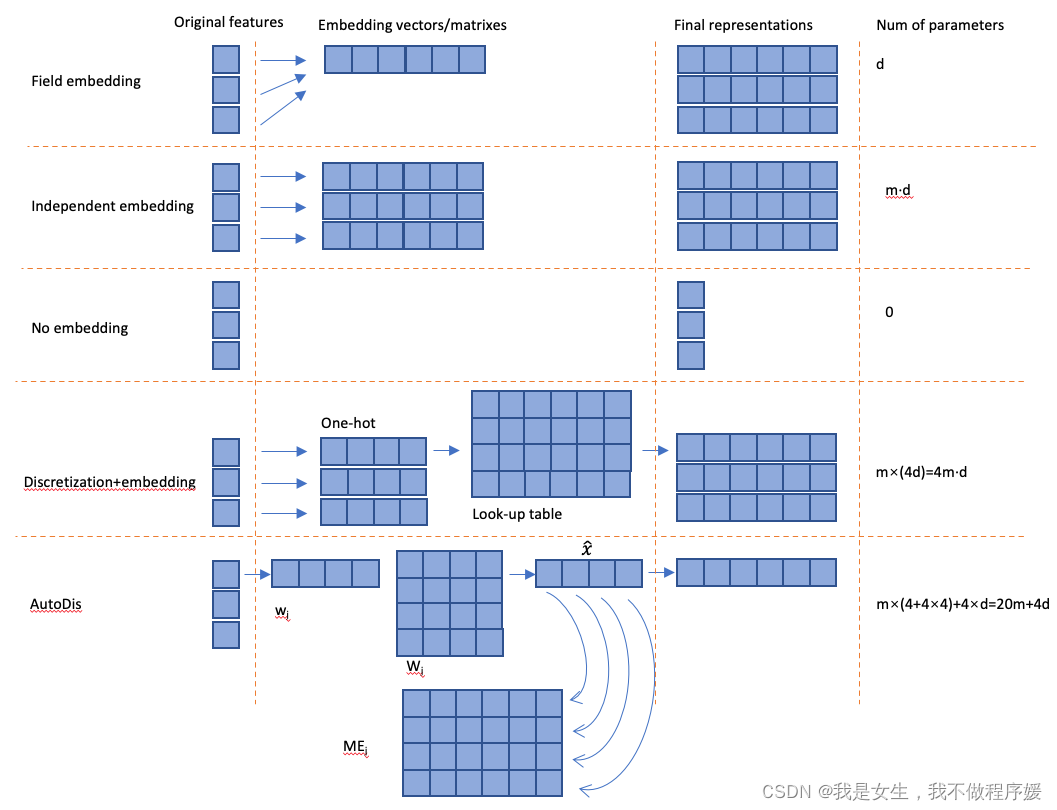
可以看出:
- field embedding和no embedding所需的参数最少,但capacity受限(表示的维度小,或field内部具有强相关性);
- independent embedding和discretization+embedding的参数成倍数级增长,而AutoDis由于整个field共享ME,不会因为过大feature数量和embedding维度而参数爆炸;
- discretization+embedding的离散化与DNN训练分离,不能保证离散化方法和结果对问题本身的合理性。
参考资料:
https://www.jianshu.com/p/152ae633fb00
https://www.jianshu.com/p/6f1c2643d31b
https://blog.csdn.net/weixin_45459911/article/details/106917001















 3342
3342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









