






《基于机器学习的雷达辐射源分选与识别技术研究》论文解读
Data:2023-2-04
Ref: 李雪琼, “基于机器学习的雷达辐射源分选与识别技术研究,” PhD Thesis, 国防科技大学, 2020.
文章目录
这篇文章我主要关注他的第三、四章。第三章主要描述了基于已知信号的雷达分选技术,第四章主要描述了基于未知信号的雷达分选技术。
背景
在雷达侦察中,雷达接收机会接收到许多信号,其中包括同一个辐射源在不同时间发射出来的雷达信号,也包括不同辐射源发射出来的信号,如下图所示。雷达分选的目标就是对接收到的信号进行分析,分析出来雷达辐射源的数量、方位、个体等信息。
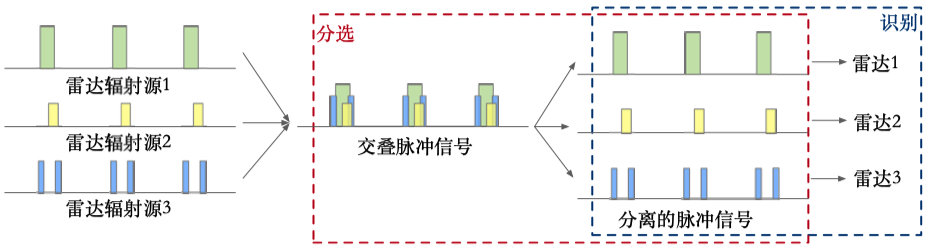
雷达接收机在接收到雷达信号后,经过测量会返回脉冲描述字(Pulse Descriptive Word,PDW)给处理系统。处理系统首先需要对数据进行分选,即将雷达信号划分为一个个的辐射源以便进一步分析;然后需要对分选后的来自单个辐射源的信号进行参数分析;获取到辐射源的参数后需要进行辐射源识别,识别出来辐射源的型号和个体等信息最后输出。处理流程如图1所示。我们关注的是流程中的分选部分。

如下图所示,雷达脉冲描述字一般包含一下几个参数:
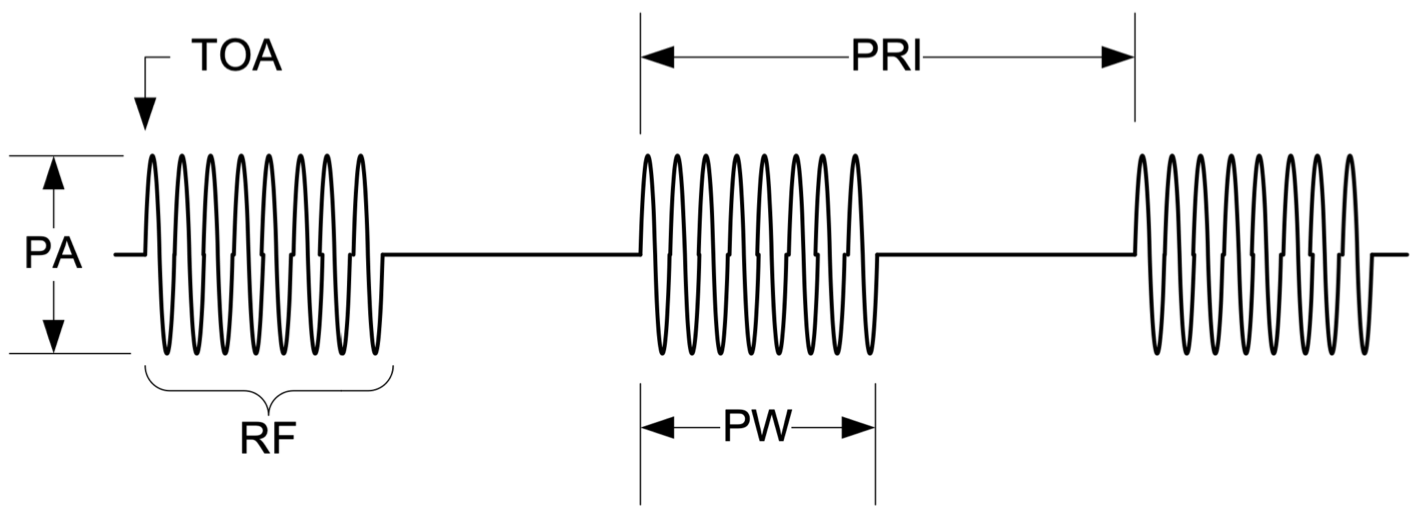
- 信号到达方向(DOA),即雷达辐射源与雷达侦察机之间的方位角;
- 载波频率(RF),我的理解是雷达信号的频率,但是频率不一定是固定的有多种变换模式;
- 脉冲宽度(PW),即信号脉冲到达时间和结束时间之间的时间宽度;
- 脉冲幅度(PA),到达信号的电压电平,与环境有关不够稳定;
- 信号到达时间(TOA),即脉冲前沿被侦查器接收到的时间。单个辐射源的信号到达时间的差值称为脉冲重复周期(Pulse Repetitive Interval,PRI),也称为重频。例如,一个辐射源的信号分别在
0us,200us,400us,600us....被接收到,那么这就是一个固定重频类型,重频值为200us.
本文的方法都是以PRI为参数进行分析的,因此接下来着重介绍一下重频。
重频(PRI)
来自同一辐射源的TOA可以表示为
T
=
{
t
1
,
t
2
,
t
3
.
.
.
t
n
}
T=\{t_1,t_2,t_3...t_n\}
T={t1,t2,t3...tn},其中
t
i
t_i
ti表示第
i
i
i个脉冲到达的时间,
n
n
n表示脉冲总数。那么重频可以表示为:
P
=
{
p
1
,
p
2
,
p
3
.
.
.
p
n
−
1
}
,
p
i
=
t
i
+
1
−
t
i
P=\{p_1,p_2,p_3...p_{n-1}\},p_i=t_{i+1}-t_i
P={p1,p2,p3...pn−1},pi=ti+1−ti
重频有多种类型,主要区别是重频的变化规律,例如重频值固定不变的固定重频、在多个重频值之间定时切换的参差重频。重频的主要类型如下表所示。每种重频类型的具体特性请参考论文(章节2.2.2.2)。
基于已知信号的雷达分选技术
经过长时间的雷达观测,针对一些已知的重点目标的雷达辐射源已经分析得到了其信号参数。因此可以先将这部分已知信息的辐射源信号分选出来进行处理,同时也可以减少混合信号中的信号数量、降低后续处理的噪声。
信号分选本质上是一种去噪操作,将信号中的噪声去除后获得消除误差的信号,以便进行进一步处理。误差主要包含以下几种类型:
-
丢失脉冲,即本来应该检测到但是没有被捕获到的信号。
-
虚假脉冲,即捕获到了不存在的脉冲。
-
测量误差,指测量时的误差,成因为雷达辐射源本身器件或接收机工作状态不稳定。例如信号是在200us时到达的但是雷达接收机测量出错测量的到达时间为220us。测量误差一般符合正态分布:
p n = P n − μ σ p_n=\frac{P_n-\mu}{\sigma} pn=σPn−μ
其中, p n p_n pn为第 n n n个PRI值(即公式(1))所示), μ \mu μ为整个PRI序列的均值, σ \sigma σ为标准差。
自编码器
本文采用了一种自编码器对信号进行处理。自编码器可以自动的从无标注数据中学习到数据的表示方法。由于只提取出来这个信号的特征,因此可以滤除掉无关的信号数据。
如下图所示,自编码器的结构分为2部分,编码器和解码器。自编码器的输入和输出维度相同,首先编码器将样本映射到特征空间得到每个样本的编码,然后利用解码器将每个样本的编码重构出原始的样本。

本文采用的自编码器的结构如下图所示,编码器和解码器均为三层全连接层,其神经元个数分别设置为 128,64,32 和 32,64,128。每一层全连接层后都跟随 ReLU 以确保非线性处理。

并行降噪自编码器
一个自编码器只能针对某一个已知的辐射源的参数进行训练,在实践中需要对多个辐射信号源进行处理时,可以将多个自编码器并联起来工作,如下图所示。
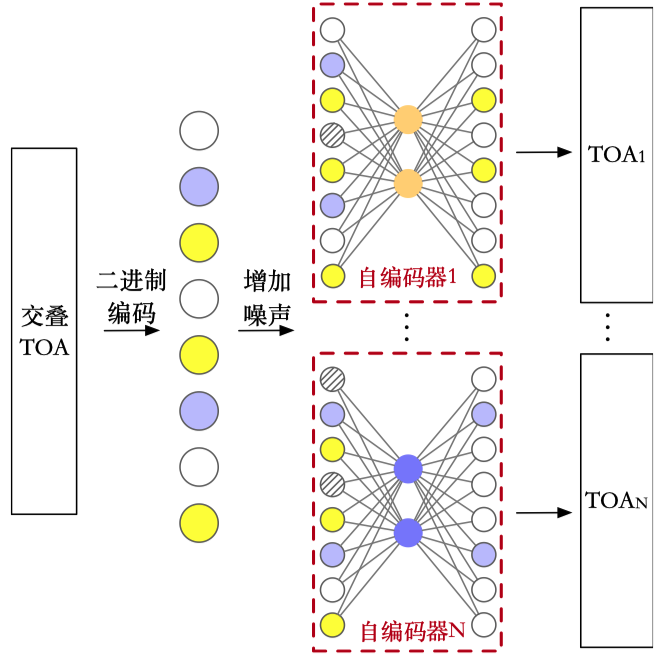
在并行处理的过程中,多个基于自编码器的分选网络同时工作,这些网络可以根据已知辐射源目标的 PRI 规律挑选出相应脉冲并进行验证,最终完成分选任务。
数据预处理
如前文所述,这个模型只利用TOA作为输入进行分析。TOA是到达时间的绝对值,因此是一个不断增长的时间序列,雷达每秒接收的脉冲可以达到百万甚至千万次,因此TOA的大小可以很大,并且绝对值也不利于分析操作不能直观的观察出规律。因此本文采用了一种简单的数据预处理的方法,将TOA按照时间窗口编码为由1和0组成的二进制向量,如下图所示:
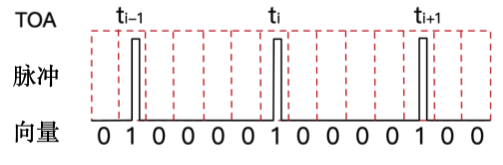
在一个时间窗口内,有信号到达则编码为1,没有则为0。例如时间窗口为 50 u s 50us 50us,对四种不同的重频类型进行编码的结果如下表所示。经过转化的编码便于机器学习算法学习特征,并且可以初步消除测量误差,不过会丢失某些特征。

实验评估
-
测试数据集
这篇文章的实验采用了4种不同模式的TOA序列,并且在一定比例内随机添加了虚假脉冲、丢失脉冲和测量误差。测量误差的添加方式没有看到明确的添加方式,虚假脉冲就是将TOA转换成二进制向量后随机选择1位将其由0反转为1,丢失脉冲则相反。

-
实验结果
这里只放于其他算法进行对比的部分。对比的算法分别是两种基于后续步骤脉冲搜索算法(DIF)的CDIF和SDIF,以及一个基于循环神经网络(RNN)的算法,实验结果如下图所示。实验测试只测试了不同算法对滑变重频的分选效果对比,在不同脉冲丢失率和滑变重频值个数的情况下进行实验。
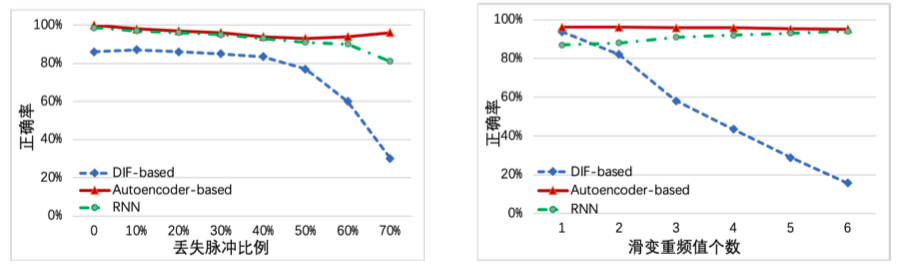
在左图中,基于 DIF 的方法的分选性能随着丢失脉冲比率的增加而急剧下降,而降噪自编码器方法仅具有轻微的振动,始终保持 90%以上的分选正确率。这是因为序列搜索方法是按照时间规律依次寻找目标脉冲,而在有脉冲丢失的情况下,无法将缺失脉冲的后续脉冲也判断为目标脉冲。而 RNN 模型在丢脉冲率较低的情况下也保持了良好的分选性能。
在右图中,随着滑变重频值个数的增加,基于 DIF 的方法无法对过多个数的重频值进行搜索识别,这是由于重频值的增多使 TOA 序列更加复杂,从而导致难以使用常规序列搜索方法挑选正确的脉冲。而降噪自编码器模型在重频值变化范围内仍保持鲁棒性。但是RNN 的分选开销相对降噪自编码器模型而言较高(没有开销分析)。
基于未知信号的雷达分选技术
经过上一步筛选出了已知的雷达信号后,可以在原始信号中将已知的雷达信号删除降低信噪比,然后进行下一步的常规分选。常规分选是指将接收到的雷达信号分离成来自不同辐射源的脉冲子序列。
这篇文章的总体思路是采用一维卷积网络对信号进行特征提取,然后利用一个全连接网络进行分类。但是在这个过程中存在2个关键问题:
- 信号的数量未知,因此网络输出的信号数量并不确定。本文提出了一种迭代算法模块,每次推理只输出一种类型的信号,输出后在输入信号中删除这次的输出信号重新进行推理,直到信号为空或者达到最大迭代次数。
- 信号的输出顺序未知。理论上以任何顺序输出信号均可,但是在计算模型损失的时候若输出的顺序和目标顺序不符,即便输出的结果是正确的也会导致损失函数计算结果很大。本文提出了一种多目标训练方法,枚举所有可能的目标信号输出顺序并与当前的输出信号计算损失,取最小值即可。
卷积与分类器
卷积层的目的是针对输入的 TOA 序列进行局部特征的提取,每一层使用不同的卷积核分别提取输入数据的不同特征。但是这里有点没看懂的地方是前面说了是用一维卷积,但是怎么到了后面卷积核又是一个三维张量了。猜测是把一个信号reshape成了多维或者将多个信号叠加起来一起进行卷积。具体可以参考原文第62页查看详细的卷积方法。
在经过卷积和池化后,得到的输出特征经过分类器后得到每个脉冲对应的类别。分类器为一个全连接层+sigmod函数。假设脉冲序列中包含K个不同辐射源的子脉冲序列,那么就将推理结果对应的类型相应位置1,其余位置0。
本文所用的网络模型参数如下图所示。

迭代算法模块
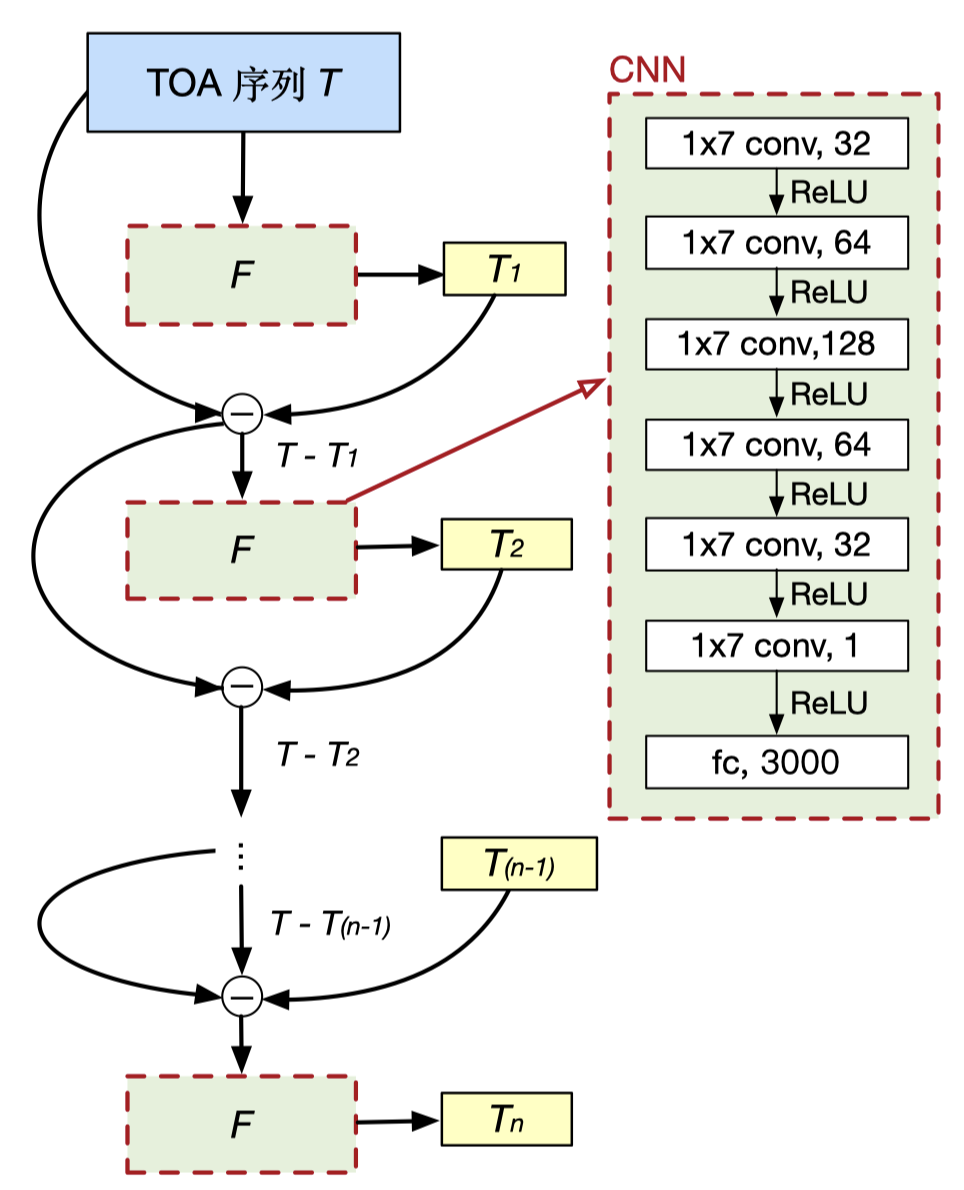
如前文所述,使用传统的CNN网络无法解决输出个数不确定的问题。因此本文设计了一种迭代输出的方法,思路是每次推理只输出一种类型的脉冲信号,然后用这次的输入信号减去输出的信号作为下一次的输入信号,迭代输出所有的信号类型。直到达到最大迭代次数或者信号为空后停止迭代。
如下图所示,图中的F为网络,上方指向每个F的箭头是网络的输入,F右侧的 T 1 , T 2 . . . T n T_1,T_2...T_n T1,T2...Tn为每次输出的结果。每当输出一次T后,用上次的输入减去这次的T,作为下一次的输入。
多目标训练方法
输出包含多个 TOA 子序列,这些子序列输出的顺序代表分选的先后次序,理论上不影响分选的结果。然而,在计算目标函数时,由于需要一对一比较子序列的正确识别率,所以需要保证输出子序列与目标序列的完全匹配性,因此子序列的输出顺序极大地影响了目标函数的计算,仅用普通方法计算目标函数值会带来巨大的歧义。
因此本文提出了一种多目标训练(Multi-target Training)方法来解决这个问题。该方法的基本思想是将输出子序列所有可能的组合顺序与目标序列分别进行比较并求取多个差异值,然后在所有差异值中选取最小的那个值作为整个输出与目标之间的差异值。
多目标训练的形式化表述如下:设输入信号
G
G
G来自
K
K
K个辐射源,那么
G
=
{
G
1
,
G
2
,
.
.
.
,
G
K
}
G=\{G_1,G_2,...,G_K\}
G={G1,G2,...,GK}。那么所有可能的顺序组合数量为
N
u
m
K
=
K
!
Num_K=K!
NumK=K!。因此对于模型第
i
i
i次输出的子序列
T
i
T_i
Ti,要分别与所有可能的排列
p
p
p中的第
i
i
i个子序列
G
p
i
G_{pi}
Gpi计算损失
l
i
p
l_i^p
lip,然后求和。因此计算某种可能组合与输出结果的损失的公式为:
l
p
=
∑
i
=
1
N
l
i
p
=
∑
i
=
1
N
B
C
E
L
o
s
s
(
T
i
,
G
p
i
)
l^p=\sum_{i=1}^N l_i^p=\sum_{i=1}^N BCELoss(T_i,G_{pi})
lp=i=1∑Nlip=i=1∑NBCELoss(Ti,Gpi)
式中BCELoss指二元交叉墒。
我认为原文公式有误,原文中的公式(4.14)中的 l i l_i li和(4.12)中的 l i l_i li并不是指的同一个值。4.12中的 l i l_i li指的是在某种输出组合 p p p下第 i i i项输出的损失,4.14中 l i l_i li指的是整个输出结果与某种组合 p p p的损失之和。因此我修改了一下,用 l p l^p lp来表示4.14中的 l i l_i li。
当计算出来模型的所有输出结果与每种结果组合的损失后,取最小值即可:
L
=
m
i
n
{
l
1
,
l
2
.
.
.
l
N
u
m
K
}
L=min\{l^1,l^2...l^{Num_K}\}
L=min{l1,l2...lNumK}
实验评估
实验从两方面进行了测试,一个是混合固定类型数量,但是参数未知的子序列以验证分选模型在重频具体值未知的混叠TOA序列中,将已知个数的辐射源分选出来的性能;其次是在一定范围内选取任意数量,但是参数固定的子序列进行组合,验证分选模型在重频数值确定的情况下,将未知辐射源数目的雷达脉冲分选出来的能力。
结果表明,在辐射源个数未知或重频类型未知的情况下均可以取得良好的分选性能,即便是在具有相同重频的交叠 TOA 序列中也能够将其分选出来。具体实验结果数据可以参考原文第71-73页。















 9439
9439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









