







 本周的机器学习练习重点是正则化的线性回归,包括理解并实现正则化线性回归的代价函数、梯度以及找到最佳参数。同时,通过学习曲线探讨了模型的偏差和方差问题。此外,还涉及了多项式回归的实践,以及如何通过调整正则化和使用交叉验证集来优化模型性能。
本周的机器学习练习重点是正则化的线性回归,包括理解并实现正则化线性回归的代价函数、梯度以及找到最佳参数。同时,通过学习曲线探讨了模型的偏差和方差问题。此外,还涉及了多项式回归的实践,以及如何通过调整正则化和使用交叉验证集来优化模型性能。
本周的练习题是关于正则化的线性回归和偏差方差问题。
一、正则化的线性回归
前半部分的练习,你会使用线性回归来通过水坝的水位预测大坝的流水量。后半部分,通过诊断法来调试学习算法并且检查方差和偏差的影响。
(1)可视化数据集
x:表示水位变化,y:表示大坝水流量
数据集被分成三部分:训练集(X,y),用来决定正则化参数的交叉验证集(Xval,yval),用来评判性能的未见过的案例的测试集(Xtest,ytest)。
代码如下(ex5.m里面):
% Load from ex5data1:
% You will have X, y, Xval, yval, Xtest, ytest in your environment
load ('ex5data1.mat');
% m = Number of examples
m = size(X, 1);
% Plot training data
plot(X, y, 'rx', 'MarkerSize', 10, 'LineWidth', 1.5);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');(2)正则化线性回归的代价函数(只要涉及代价的求解函数,就必须再给函数供参数的时候添加上全1列,不可少)
现在你需要完成正则化的线性回归的代价函数的代码,在linearRegCostFuncion.m(注意给他提供参数的时候X要添加全1列)文件里面填写:
假设函数:

代价函数:

代码:
J=1/(2*m)*sum((X*theta-y).^2)+lambda/(2*m)*sum(theta(2:end,:).^2);(3)正则化线性回归的梯度
公式如下:


由于正则化是不对
 的,这一点需要注意!
的,这一点需要注意!
的,这一点需要注意!
代码如下:
grad_tmp=X'*(X*theta-y)/m;%这个是没有考虑正则化的时候,那么正则化后的梯度就是现在求得梯度的第一个元素,接着剩下的元素加上正则化项
grad=[grad_tmp(1:1);grad_tmp(2:end)+lambda/m*theta(2:end)];(4)找到最佳的线性回归-trainLinearReg.m函数来计算出最佳的参数
完成对代价函数和梯度的计算,现在我们需要完成对正则化的线性回归模型进行优化找到最佳的参数,使用的是fmincg函数。这一节我们将正则化参数
 设置为0,因为我们现在尝试找到最佳的二维参数
设置为0,因为我们现在尝试找到最佳的二维参数
 ,正则化对低维的参数
,正则化对低维的参数
 作用不大。再后来我们会使用到带正则化的多项式回归模型。最后执行的代码会绘制出最佳匹配线,但是很显然看图并不是最佳匹配的,虽然这个图形很显然的看出我们的模型并不是最佳的,但是就如前面的博客所说的,并不是所有的模型都可以通过画图来看出模型的好坏,还需要通过绘制学习曲线来帮助你看出你的模型哪里不对劲!!
作用不大。再后来我们会使用到带正则化的多项式回归模型。最后执行的代码会绘制出最佳匹配线,但是很显然看图并不是最佳匹配的,虽然这个图形很显然的看出我们的模型并不是最佳的,但是就如前面的博客所说的,并不是所有的模型都可以通过画图来看出模型的好坏,还需要通过绘制学习曲线来帮助你看出你的模型哪里不对劲!!
设置为0,因为我们现在尝试找到最佳的二维参数
,正则化对低维的参数
作用不大。再后来我们会使用到带正则化的多项式回归模型。最后执行的代码会绘制出最佳匹配线,但是很显然看图并不是最佳匹配的,虽然这个图形很显然的看出我们的模型并不是最佳的,但是就如前面的博客所说的,并不是所有的模型都可以通过画图来看出模型的好坏,还需要通过绘制学习曲线来帮助你看出你的模型哪里不对劲!!
(无需我们填写)
function [theta] = trainLinearReg(X, y, lambda)
%TRAINLINEARREG Trains linear regression given a dataset (X, y) and a
%regularization parameter lambda
% [theta] = TRAINLINEARREG (X, y, lambda) trains linear regression using
% the dataset (X, y) and regularization parameter lambda. Returns the
% trained parameters theta.
%
% Initialize Theta
initial_theta = zeros(size(X, 2), 1);
% Create "short hand" for the cost function to be minimized
costFunction = @(t) linearRegCostFunction(X, y, t, lambda);
% Now, costFunction is a function that takes in only one argument
options = optimset('MaxIter', 200, 'GradObj', 'on');
% Minimize using fmincg
theta = fmincg(costFunction, initial_theta, options);
end
二、偏差/方差
高偏差-欠拟合,高方差-过拟合
(1)学习曲线(绘制训练集误差和交叉验证集误差关于训练集数目m的图像-完成learningCurve.m函数)
为了绘制这个曲线,我们需要得到对于不同大小的训练集训练出来的模型的训练误差和交叉验证集误差,为了得到不同的训练集,你需要得到不同的X的子集。当训练集的大小为i的时候,你使用的是X(1:i,:)和y(1:i),你可以使用函数trainLinearReg.m这个函数来找到最佳的参数
 ,当你学的这个参数的时候,必须计算出训练集误差和交叉验证集误差,这里不在复习训练集误差和交叉验证集误差公式,前面博客都有。
,当你学的这个参数的时候,必须计算出训练集误差和交叉验证集误差,这里不在复习训练集误差和交叉验证集误差公式,前面博客都有。
,当你学的这个参数的时候,必须计算出训练集误差和交叉验证集误差,这里不在复习训练集误差和交叉验证集误差公式,前面博客都有。
几点提醒:训练集误差,交叉验证集误差不包括正则项,所以你在使用costFunction的时候,需要将 设置成0(易错点!!!);还有在计算训练集误差的时候,注意使用的不是整个X,y集,而是他们的子集X(1:i,:)和y(1:i);但是在训练交叉验证集的误差的时候使用的是
整个交叉验证集。最后的误差存在error_train和error_val里面。
设置成0(易错点!!!);还有在计算训练集误差的时候,注意使用的不是整个X,y集,而是他们的子集X(1:i,:)和y(1:i);但是在训练交叉验证集的误差的时候使用的是
整个交叉验证集。最后的误差存在error_train和error_val里面。
设置成0(易错点!!!);还有在计算训练集误差的时候,注意使用的不是整个X,y集,而是他们的子集X(1:i,:)和y(1:i);但是在训练交叉验证集的误差的时候使用的是
整个交叉验证集。最后的误差存在error_train和error_val里面。
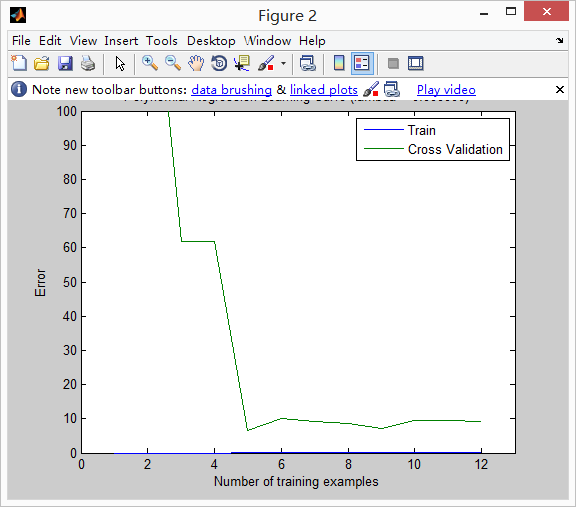
得到结果如下:(发现:训练集误差和交叉验证集误差都非常的大,且距离很近,所有是高偏差-欠拟合,在所有我们下面使用的是多项式回归)

在代码里面我有个疑问,我没有在这个代码里面嵌入求解代价函数的linearRegCostFunction函数,而是自己写出了cost的表达式,发现得到的结果图如下,跟给的答案不一样,后来我又使用函数的方法,发现得到上面的结果是对的!

代码如下:
function [error_train, error_val] = ...
learningCurve(X, y, Xval, yval, lambda)
%LEARNINGCURVE Generates the train and cross validation set errors needed
%to plot a learning curve
% [error_train, error_val] = ...
% LEARNINGCURVE(X, y, Xval, yval, lambda) returns the train and
% cross validation set errors for a learning curve. In particular,
% it returns two vectors of the same length - error_train and
% error_val. Then, error_train(i) contains the training error for
% i examples (and similarly for error_val(i)).
%
% In this function, you will compute the train and test errors for
% dataset sizes from 1 up to m. In practice, when working with larger
% datasets, you might want to do this in larger intervals.
%
% Number of training examples
m = size(X, 1);
% You need to return these values correctly
error_train = zeros(m, 1);
error_val = zeros(m, 1);
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return training errors in
% error_train and the cross validation errors in error_val.
% i.e., error_train(i) and
% error_val(i) should give you the errors
% obtained after training on i examples.
%
% Note: You should evaluate the training error on the first i training
% examples (i.e., X(1:i, :) and y(1:i)).
%
% For the cross-validation error, you should instead evaluate on
% the _entire_ cross validation set (Xval and yval).
%
% Note: If you are using your cost function (linearRegCostFunction)
% to compute the training and cross validation error, you should
% call the function with the lambda argument set to 0.
% Do note that you will still need to use lambda when running
% the training to obtain the theta parameters.
%
% Hint: You can loop over the examples with the following:
%
% for i = 1:m
% % Compute train/cross validation errors using training examples
% % X(1:i, :) and y(1:i), storing the result in
% % error_train(i) and error_val(i)
% ....
%
% end
%
% ---------------------- Sample Solution ----------------------
for i=1:m
theta = trainLinearReg(X(1:i,:), y(1:i), lambda);%通过fmincg来完成
%error_train(i)=1/(2*m)*sum(( X( 1:i,:)*theta-y(1:i)).^2);
% error_val(i)=1/(2*m)*sum((Xval*theta-yval).^2);%这样就是错误的图出来。。。why?
error_train(i) = linearRegCostFunction(X(1:i, :), y(1:i), theta, 0);
error_val(i) = linearRegCostFunction(Xval, yval, theta, 0);
end
% -------------------------------------------------------------
% =========================================================================
end
三、多项式回归
由于线性回归太简单了,使得我们的模型欠拟合了,所以我们使用多项式回归,给之前的问题添加了更多的特征。我们的假设函数的形式如下:
 ,可以很显然的看出来,我们的每一个特征,都是由waterlevel的次方得到的。我们需要完成polyFeatures.m里面的代码实现扩展原来的X,一个m*1维的X训练集会转成一个m*p维的矩阵X_poly。第一列是原来的X,第二列是X.^2,第三列的是X.^3等等。你无须计算0次方的列。(我们不仅需要对训练集进行扩展,同样的测试集和交叉验证集也需要都在ex5.m函数里面)
,可以很显然的看出来,我们的每一个特征,都是由waterlevel的次方得到的。我们需要完成polyFeatures.m里面的代码实现扩展原来的X,一个m*1维的X训练集会转成一个m*p维的矩阵X_poly。第一列是原来的X,第二列是X.^2,第三列的是X.^3等等。你无须计算0次方的列。(我们不仅需要对训练集进行扩展,同样的测试集和交叉验证集也需要都在ex5.m函数里面)
ployFeatures.m代码:
function [X_poly] = polyFeatures(X, p)
%POLYFEATURES Maps X (1D vector) into the p-th power
% [X_poly] = POLYFEATURES(X, p) takes a data matrix X (size m x 1) and
% maps each example into its polynomial features where
% X_poly(i, :) = [X(i) X(i).^2 X(i).^3 ... X(i).^p];
%
% You need to return the following variables correctly.
X_poly = zeros(numel(X), p);
% ====================== YOUR CODE HERE ======================
% Instructions: Given a vector X, return a matrix X_poly where the p-th
% column of X contains the values of X to the p-th power.
%
for i=1:p
X_poly(:,i)=X.^i;
end
% =========================================================================
end
在完成特征的扩展之后,特征之间的跨度就大了,一个数的8次方就很大了,我们需要做
特征归一化的操作,在函数featureNormalize.m中(学习一个matlab的新的函数
bsxfun):
function [X_norm, mu, sigma] = featureNormalize(X)
%FEATURENORMALIZE Normalizes the features in X
% FEATURENORMALIZE(X) returns a normalized version of X where
% the mean value of each feature is 0 and the standard deviation
% is 1. This is often a good preprocessing step to do when
% working with learning algorithms.
mu = mean(X);%求平均
X_norm = bsxfun(@minus, X, mu);%bsxfun(fun,A,B),fun表示的是操作,实现的是A和B之间的元素对元素的操作
sigma = std(X_norm);%标准差
X_norm = bsxfun(@rdivide, X_norm, sigma);%除以右边的
% ============================================================
end
(1)学习多项式回归
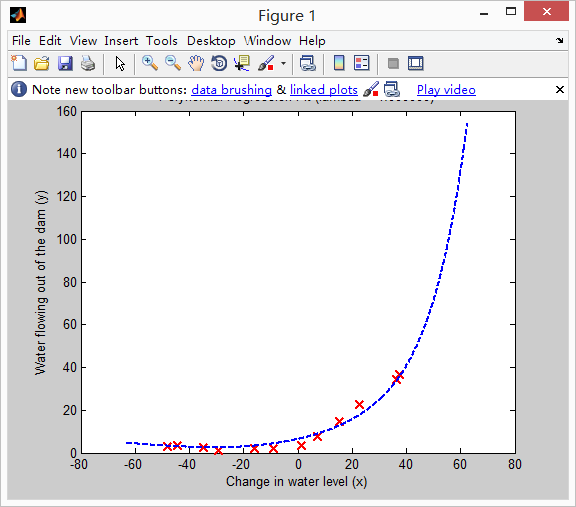
注意尽管我们扩展了特征,但是他还是一个线性回归问题,所以我们还是可以使用之前的代价函数,梯度,优化函数等,在我们学习模型的参数,我们先进行featureNormalize函数进行归一化,当我们学习完参数,你会看到两个图( =0)
=0)
下图你会发现,你的模型匹配很好,所以会产生较低训练误差,导致过拟合。

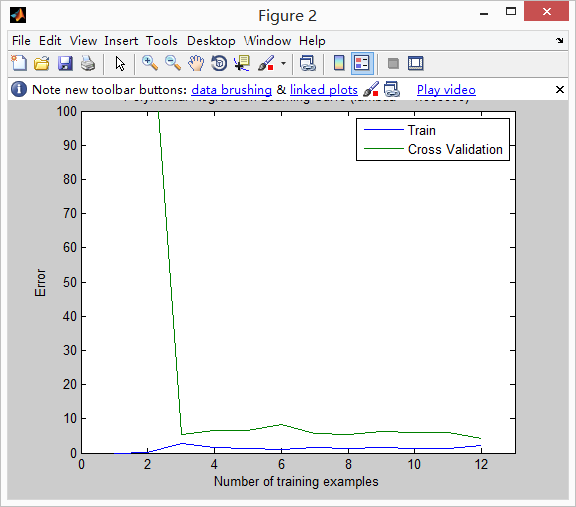
学习曲线如下:
 ,你看到学习曲线的训练集误差十分的低,交叉验证集误差十分高-->两个曲线之间的空格表示了是一个高方差问题!!!
,你看到学习曲线的训练集误差十分的低,交叉验证集误差十分高-->两个曲线之间的空格表示了是一个高方差问题!!!
,你看到学习曲线的训练集误差十分的低,交叉验证集误差十分高-->两个曲线之间的空格表示了是一个高方差问题!!!
那么我们如何克服这个高方差/过拟合的问题呢,其中一种方法就是正则化,下一节你将使用不同的
 来看看怎么形成更好的模型?
来看看怎么形成更好的模型?
来看看怎么形成更好的模型?
(2)调整正则化(附加题)
在这部分,我们将观察正则化的参数是如何影响正则化的多项式回归的偏差和方差的,你可以修改
 的值,
的值,
 ,每一个
的值都会产生一个多项式的用来拟合数据的和一个学习曲线。
,每一个
的值都会产生一个多项式的用来拟合数据的和一个学习曲线。
 ,你会发现结果如下图:你会发现你的拟合曲线适配的非常好,学习曲线上交叉验证集误差和训练集误差都会聚到相对低的值,所以说
,你会发现结果如下图:你会发现你的拟合曲线适配的非常好,学习曲线上交叉验证集误差和训练集误差都会聚到相对低的值,所以说
 的时候多项式回归模型没有高偏差也没有高方差。
的时候多项式回归模型没有高偏差也没有高方差。
的值,
,每一个
的值都会产生一个多项式的用来拟合数据的和一个学习曲线。
,你会发现结果如下图:你会发现你的拟合曲线适配的非常好,学习曲线上交叉验证集误差和训练集误差都会聚到相对低的值,所以说
的时候多项式回归模型没有高偏差也没有高方差。
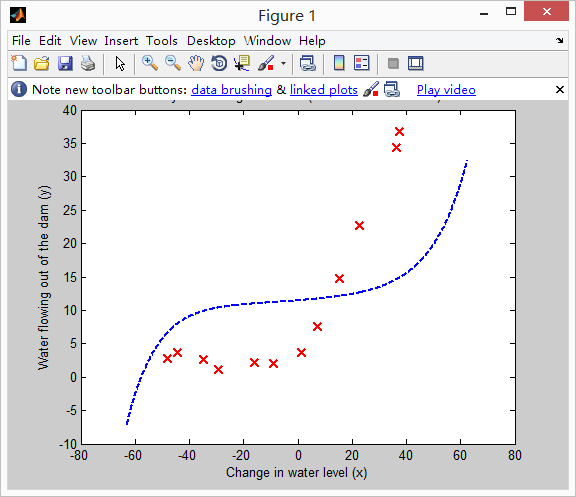
对
 你可以看到下面的结果就没有拟合的很好,因为加入了过大的正则项
你可以看到下面的结果就没有拟合的很好,因为加入了过大的正则项
你可以看到下面的结果就没有拟合的很好,因为加入了过大的正则项

(3)选择使用交叉验证集
你发现前面一小节的内容是
 对于交叉验证集误差和训练集误差的影响,当
对于交叉验证集误差和训练集误差的影响,当
 的时候,很好地拟合数据但却无法很好地判断新的数据;
的时候,很好地拟合数据但却无法很好地判断新的数据;
 又加入太大的正则项,无法很好地拟合交叉验证集误差和测试集误差;
又加入太大的正则项,无法很好地拟合交叉验证集误差和测试集误差;
 相比较更加的好。这节我们将自动的选择
相比较更加的好。这节我们将自动的选择
 ,你会使用交叉验证集误差来判断
,你会使用交叉验证集误差来判断
 到底好不好,当你选择了
到底好不好,当你选择了
 之后,我们将测试在测试集上的误差,你需要完成validationCurve.m,你可以使用trainLinearReg函数来训练不同的模型,计算训练集误差和交叉验证集误差。你可以尝试的
之后,我们将测试在测试集上的误差,你需要完成validationCurve.m,你可以使用trainLinearReg函数来训练不同的模型,计算训练集误差和交叉验证集误差。你可以尝试的
 选择如下:{0,0.001,0.003,0.01,0.03,0.1,0.3,1,3,10}。当你完成代码之后,ex5.m会绘制出交叉验证集误差和
选择如下:{0,0.001,0.003,0.01,0.03,0.1,0.3,1,3,10}。当你完成代码之后,ex5.m会绘制出交叉验证集误差和
 之间的图像,你可以选出最好的那个
之间的图像,你可以选出最好的那个
 。最后最好的
。最后最好的
 应该为3
应该为3
对于交叉验证集误差和训练集误差的影响,当
的时候,很好地拟合数据但却无法很好地判断新的数据;
又加入太大的正则项,无法很好地拟合交叉验证集误差和测试集误差;
相比较更加的好。这节我们将自动的选择
,你会使用交叉验证集误差来判断
到底好不好,当你选择了
之后,我们将测试在测试集上的误差,你需要完成validationCurve.m,你可以使用trainLinearReg函数来训练不同的模型,计算训练集误差和交叉验证集误差。你可以尝试的
选择如下:{0,0.001,0.003,0.01,0.03,0.1,0.3,1,3,10}。当你完成代码之后,ex5.m会绘制出交叉验证集误差和
之间的图像,你可以选出最好的那个
。最后最好的
应该为3
虽然答案说最好的是3,但是我的结果就是0.3这样:(不知道错哪了???)
源代码validationCurve.m:
for i=1:length(lambda_vec)
lambda=lambda_vec(i);%可以先用trainLinearReg训练出模型传出参数theta,之后传给linearRegCostFunction计算代价
theta=trainLinearReg(X,y,lambda);
error_train(i)=linearRegCostFunction(X,y,theta,lambda);
error_val(i)=linearRegCostFunction(Xval,yval,theta,lambda);
end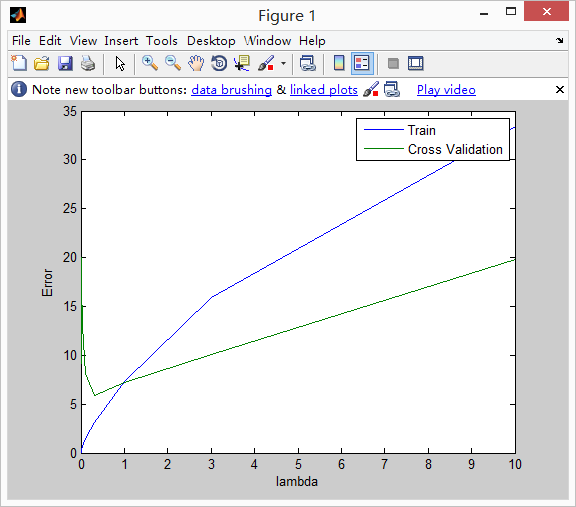
后来才发现自己的代码错在哪了:
原来我们说过计算交叉验证集误差和训练集误差是
不带上正则化的:
代码
修改如下:
function [lambda_vec, error_train, error_val] = ...
validationCurve(X, y, Xval, yval)
%VALIDATIONCURVE Generate the train and validation errors needed to
%plot a validation curve that we can use to select lambda
% [lambda_vec, error_train, error_val] = ...
% VALIDATIONCURVE(X, y, Xval, yval) returns the train
% and validation errors (in error_train, error_val)
% for different values of lambda. You are given the training set (X,
% y) and validation set (Xval, yval).
%
% Selected values of lambda (you should not change this)
lambda_vec = [0 0.001 0.003 0.01 0.03 0.1 0.3 1 3 10]';
% You need to return these variables correctly.
error_train = zeros(length(lambda_vec), 1);%针对不同的lambda存在不同的训练集误差和交叉验证集误差
error_val = zeros(length(lambda_vec), 1);
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return training errors in
% error_train and the validation errors in error_val. The
% vector lambda_vec contains the different lambda parameters
% to use for each calculation of the errors, i.e,
% error_train(i), and error_val(i) should give
% you the errors obtained after training with
% lambda = lambda_vec(i)
%
% Note: You can loop over lambda_vec with the following:
%
% for i = 1:length(lambda_vec)
% lambda = lambda_vec(i);
% % Compute train / val errors when training linear
% % regression with regularization parameter lambda
% % You should store the result in error_train(i)
% % and error_val(i)
% ....
%
% end
%
%
for i=1:length(lambda_vec)
lambda=lambda_vec(i);%可以先用trainLinearReg训练出模型传出参数theta,之后传给linearRegCostFunction计算代价
theta=trainLinearReg(X,y,lambda);
error_train(i)=linearRegCostFunction(X,y,theta,0);
error_val(i)=linearRegCostFunction(Xval,yval,theta,0);
end
% =========================================================================
end
结果如下:(最优的lambda=3)

(4)计算测试集误差(附加题)
之前的代码完成的是交叉验证集和训练集的误差测试(最优的lambda=3),但是我们最好还是计算下测试集误差:
在计算测试集误差的时候,同样犯了
上面的错误就是传给linearRegCostFunction.m的时候传入了lambda,其实应该传入0的;
代码如下:(写在ex5.m中的part7里面补充下面的倒数四行代码)
lambda = 3;
[theta] = trainLinearReg(X_poly, y, lambda);%之前X_poly已经添加了全1列了,无需在添加了
error3_test=linearRegCostFunction(X_poly_test,ytest,theta,0);
fprintf('the test error is %f\n',error3_test);
fprintf('Program paused. Press enter to continue.\n');
pause;
答案如下:(与标准答案符合)

(4)绘制学习曲线(附加题)
对i个样例,我们在训练集和交叉验证集上随机选择i个样例,之后我们在绘制出曲线,重复50次这样。下图为
 的结果:
的结果:
的结果:

补充:在ex5.m的代码里面,有一个函数
plotFit
他表示的是在一个已经存在的图像上绘制一个学习得到的多项式回归拟合图像,也适用于线性回归!!!函数原型:plotFit(min_x,max_x,mu,sigma,theta,p)绘制的是习得的多项式拟合图像,最高次是p,(mu,sigma)表示的是特征归一化!















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









