







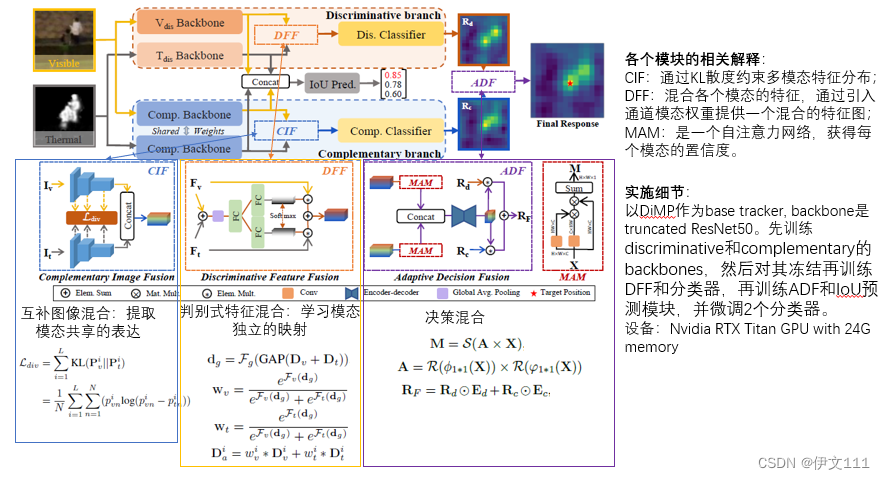
先贴个baseline的流程图:
Abstract
背景:随着多模态传感器的普及,可见光-热成像(RGB-T)目标跟踪将在温度信息的指导下实现稳健的性能和更广泛的应用场景。
科学问题:然而,缺乏成对的训练数据是当前RGB-T追踪的主要瓶颈。因为收集高质量的RGB-T序列是非常耗时费力的,最近的benchmarks仅提供了测试序列。
本文:
- 构建了一个可见光-热成像UAV跟踪大规模数据集(VTUAV),包含500 个序列具有 170 万个高分辨率(1920*1080 像素)帧对。
- VTUAV数据集考虑了不同场景下的综合应用(短期跟踪、长期跟踪和分割掩码预测)。
- VTUAV中提供了从粗到细的属性注释,其中提供了帧级属性用于探索特定跟踪器的性能。
- 设计了RGB-T baseline,称为分层多模式融合跟踪器 (HMFT)。
1. Introduction
可见光和热成像的优缺点:
| 类别 | 特点 |
|---|---|
| 可见光 | 当目标较黑/下雨/有雾/其他极端条件时,可见光提供的信息有限。 |
| 热成像 | 作为补充信息,对光照变化不敏感,但在目标和背景温度相近时,热成像难以区分前景/背景。 |
| 综合 | 将可见光-热成像(RGB-T)数据综合在一起可以提供互为补充的信息。 |
RGB-T已有数据集及相关工作:
| RGB-T已有数据集 | RGB-T相关工作 | 缺点 |
|---|---|---|
| a gray-scale RGB-T(50 videos);RGBT210(210 test videos); RGBT234(234 test videos); VOT-RGBT(60 sequences from RGBT234) | Li: 提出用于学习模态共享和模态特定表示的多适配器网络;Zhang:利用属性标注设计了实时的RGB-T追踪器;Zhang:将DiMP扩展至RGB-T追踪,在VOT2019-RGBT上获得了最好的名次 | 1. 这些数据集共包含了284个不重复的短期序列,追踪器需要在其他数据集上训练,限制了算法的泛化能力;2. 测试序列由监控设备捕获,视野/长度/图像质量有限 |
本文贡献:
- 创建高质量的可见光-热成像大规模跟踪数据集VTUAV。此外,该数据集可实现短期/长期/分割掩码预测任务的评测,还在帧和序列级别提供了属性注释,可以满足训练特定挑战跟踪器的要求。
- 提出RGB-T的baseline——HMFT,其以分层混合框架统一了不同模态的混合策略(图像混合,特征混合,决策混合)。在GTOT, RGBT21-, RGBT234, VTUAV数据集上都进行了不同混合类型的实验。
2. Related Work
2.1 RGB-T tracking benchmarks
| 数据集名称 | 介绍 |
|---|---|
| OTCBVS | 6个序列,7200帧,过时了。 |
| LITIV | 2012,9个视频片段,6300个图像对,过时了。 |
| GTOT | 2016, grayscale-thermal跟踪数据集,7800帧,包含各类极端条件算法稳定性的测试 |
| RGBT210 | 210个视频,超过104K帧 |
| RGBT234 | RGBT210的扩展版本,234个序列 |
| VOT-RGBT | 2019,60个序列,使用EAO评价算法精度和鲁棒性 |
| LSS | 可见或热图像是使用图像转换或视频着色方法从另一种模态生成的。 |
| LasHeR | 包含1224个短期视频,730K帧,多场景多角度 |
2.2 RGB-T tracking algorithms
| 混合类型 | 具体介绍 | 特点 |
|---|---|---|
| 图像混合 | 彭等人利用一组层通过共享异构数据的权重来学习互补信息。 | 能提供多模态的共享表达,高度依赖于图像对齐,还没有被充分探索 |
| 特征混合 | 包含2类:模态交互和直接混合。模态交互在另一种引导下对单模态特征进行细化,然后将两种模态的特征结合起来从而实现综合表示;直接混合先联合多模态特征然后直接级联/注意力技术得到一个混合的特征 | 更高的灵活性,能被大量不成对的数据训练,易于设计实现性能显著提升。 |
| 决策混合 | 独立建模每个模态。JMMAC采用多模态融合网络通过考虑模态级别和像素级别重要性来集成响应。 罗利用独立框架在RGB-T数据中进行跟踪,然后通过自适应加权组合结果。 | 避免了不同模态的异质性,对模态配准不敏感 |
3. VTUAV Benchmark
3.1 Benchmark Features and Statistics
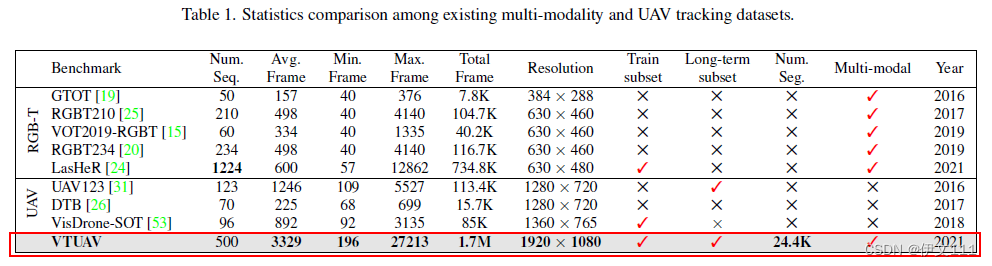
- Large-scale sequences with high diversity
500个序列with 1664549个RGB-T图像对,图像分辨率:1920x1080,250个序列的训练集(207个短时+43个长时)+250个序列的测试集(176个短时+74个长时)。
【注】:目标离开视野连续超过20帧定义为长时跟踪。
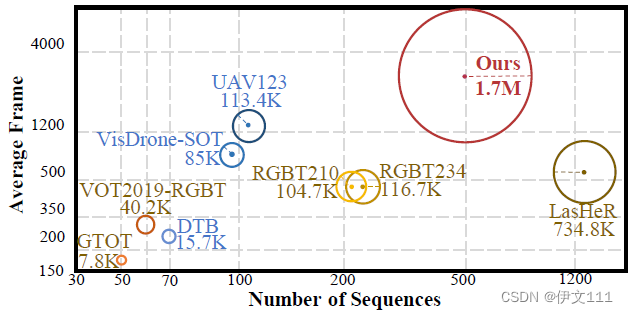
VTUAV和其他数据集的比较如下图:
- Generic object and scene category
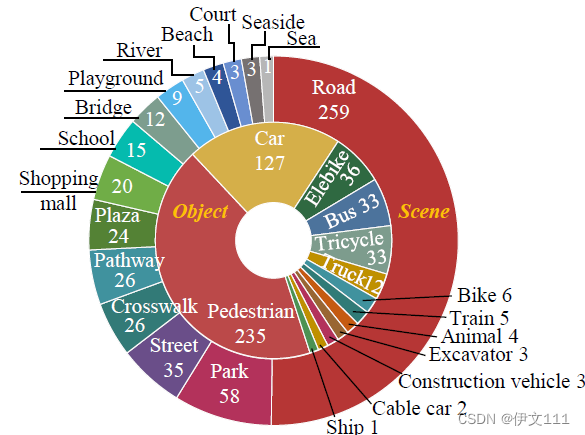
体现VTUAV数据集场景及目标多样性(5个超类,13个子类,2个城市中的15个场景,325个序列在白天+175个在晚上)的统计图如下:
- Hierarchical attributes
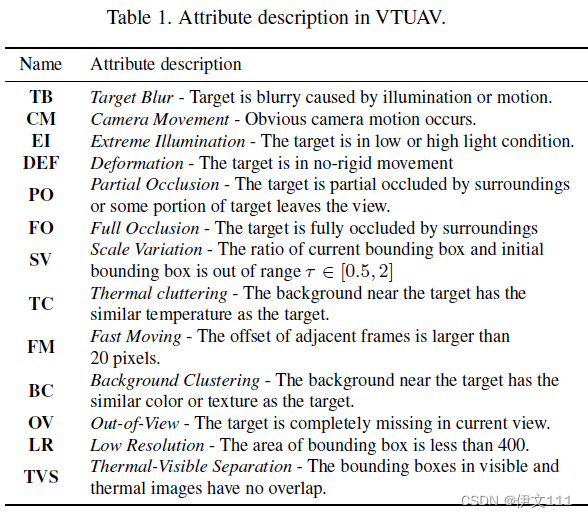
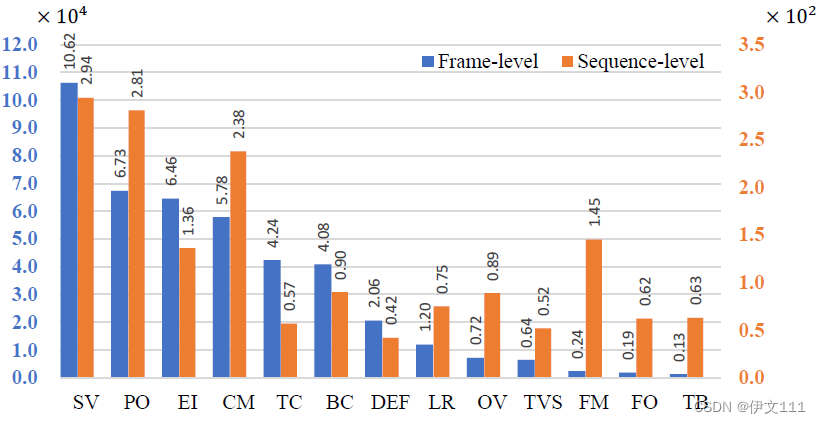
有序列级别还有帧级别的标注。共13个属性。介绍如下:
- Alignment
VTUAV在每个视频的初始帧中对不同模态图像对齐并将其应用于所有帧。 注意到大多数帧都实现了良好的对齐。
3.2 High-quality Annotation
- Bounding boxes
每间隔10帧对目标提供了稀疏的标注。稠密边界框注释通过SOTA的跟踪算法获得。共326961高质量的边界框标注。 - Segmentation masks
- Attribute annotations
提供帧级别的属性标注。301678帧,430960个属性标注,500*13个序列级别的注释。
3.3 Evaluation Metrics
以OPE方式运行,评价指标:maximum success rate (MSR,IoU大于一定阈值的帧的占比) and maximum precision rate (MPR,中心距离小于阈值的帧的占比)。
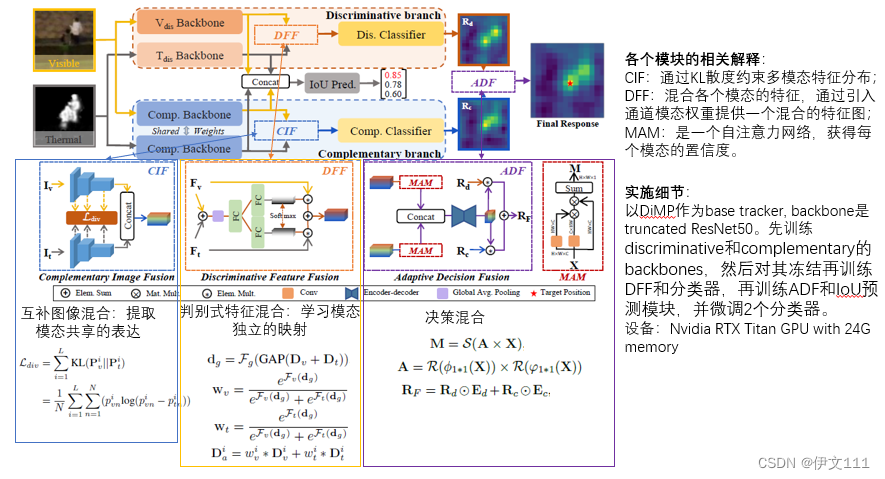
4. Hierarchical Multi-modal Fusion Tracker
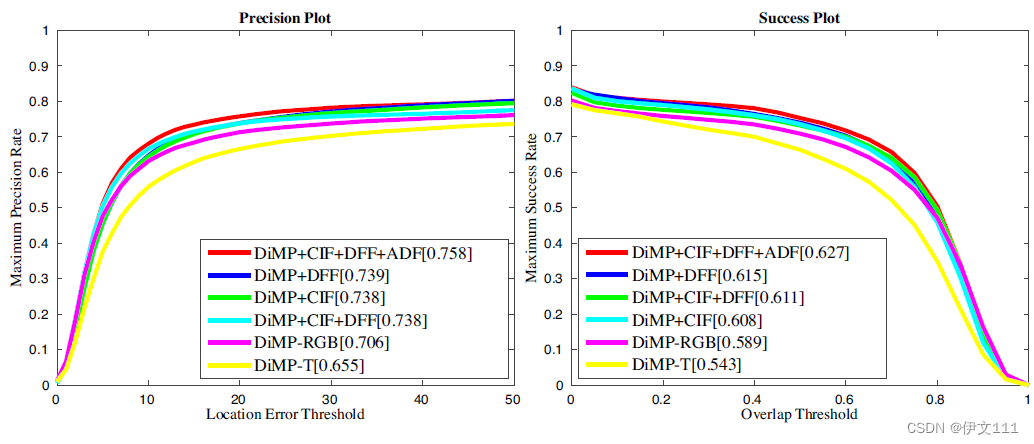
包含3种层次的混合(CIF图像混合,DFF特征混合,ADF决策混合)
- CIF:致力于学习两个模态间的共享模式;
- DFF:引入异构表示的通道组合;
- ADF:考虑判别和互补分类器的响应来提供最终目标候选者。
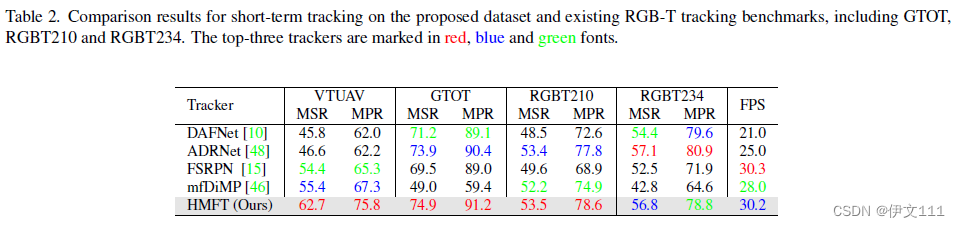
5. Experimental Analysis for RGB-T Tracking
5.1 Short-term Evaluation
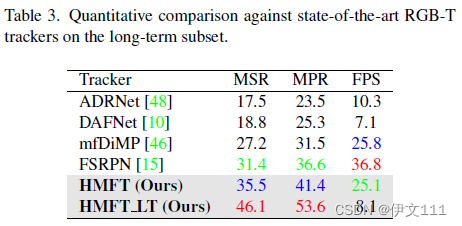
5.2 Long-term Evaluation
HMFT_LT:是HMLT的变体,HMLT作为局部追踪器(目标在视野中),将GlobalTrack作为全局追踪器(目标离开视野),RTMDNet作为tracker switcher。
5.3 Ablation Study
5.4 Qualitative Analysis

6. Experimental Results on VTUAV-V Subset
VTUAV-V是VTUAV的子集,只包含可见光的图像。
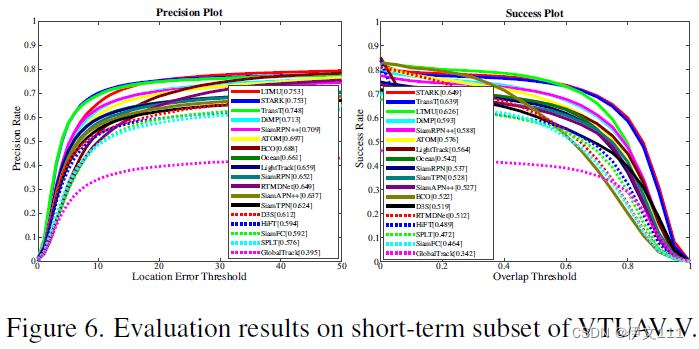
6.1 Short-term Evaluation
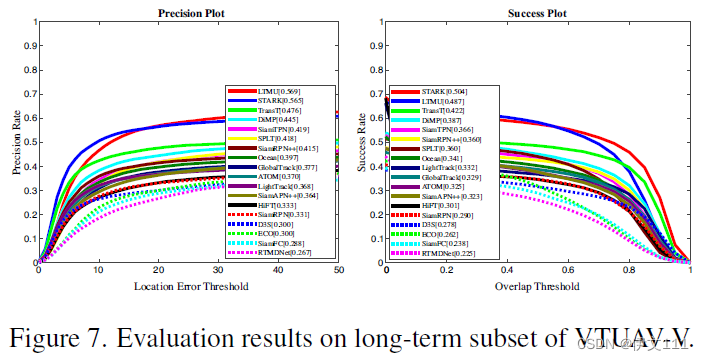
6.2 Long-term Evaluation

















 7565
7565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









