







论文地址:https://arxiv.org/pdf/2110.08822.pdf
Code:https://github.com/RISC-NYUAD/SiamTPNTracker
目录
摘要
最近的目标跟踪方法依赖于深度网络或复杂的体系结构。这些跟踪器中的大多数都很难在计算资源有限的移动平台上满足实时处理要求。在这项工作中,我们介绍了Siamese Transformer金字塔网络(SiamTPN),它继承了CNN和Transformer架构的优点。具体地说,我们利用了轻量级网络(ShuffleNetV2)的固有特征金字塔,并使用Transformer对其进行强化,以构建一个鲁棒的特定于目标的外观模型。提出了一种具有横向交叉关注的集中式体系结构,用于构建增强的高级特征图。为了避免金字塔表示与Transformer融合时的计算和存储强度,我们进一步引入了集中注意力模块,大大降低了内存和时间复杂度,同时提高了鲁棒性。在航空和流行跟踪基准上的综合实验在高速运行的同时获得了有竞争力的结果,证明了SiamTPN的有效性。此外,我们最快的变体跟踪器在单CPU核心上运行超过30 Hz,在LaSOT数据集上获得58.1%的AUC分数。源代码可在https://github.com/RISCNYUAD/SiamTPNTracker上获得
1.引言
无人机(UAV)跟踪近年来受到越来越多的关注,因为它在路径规划[25]、视觉监视[43]和边境安全[44]等不同领域具有巨大的潜力。虽然功能强大的视觉目标跟踪方法已经取得了广泛的进展,但实时跟踪的问题却被忽视了。此外,低性能紧凑设备上固有的有限电源资源进一步限制了无人机跟踪的发展。
随着移动设备软硬件的优化和轻量级但功能强大的骨干网[24,36,41]的发展,在CPU端实现了基于视觉分类、目标检测、实例分割的实时应用。然而,为计算资源有限的无人机(如单CPU核心)设计一个高效的对象跟踪器仍然具有挑战性。轻量级主干不足以提取鲁棒的区分特征,这对跟踪性能至关重要,特别是在不确定场景下。因此,以前的追踪者试图通过采用更深层次的网络[26]、设计复杂的结构[50]或者牺牲推理速度的在线更新器[2]来解决这个问题。
在这项工作中,我们缓解了上述问题,适应轻量级主干,构建基于CPU的实时跟踪器。首先,为了补充轻量级骨干网的代表能力,我们将特征金字塔网络(FPN)[30]集成到跟踪流水线中。虽然现有的跟踪器[7,15,27]也采用了多尺度功能,但它们大多采用简单的组合或针对不同的任务使用功能。我们声称这从根本上是有限的,因为判别性表示需要组合来自多个尺度的上下文。尽管FPN从低层/高层语义对金字塔信息进行编码,但它只利用来自局部邻域的上下文,而不是显式地对全局交互进行建模。FPN的感知受感受场的限制,而感受场仅限于较浅的网络。受Transformer[5]的发展及其建模全局依赖关系的能力的启发,最近的著作[13,49]引入了基于注意力的模块,并取得了深刻的成果。然而,这些模型的复杂性可能会导致不适合金字塔体系结构的计算/存储开销。相反,我们设计了一个轻量级的Transformer attention层,并将其嵌入到金字塔网络中。所提出的Siamese Transformer金字塔网络(命名为SiamTPN)通过金字塔特征之间的横向交叉关注来增强目标特征,产生鲁棒的特定于目标的外观表示。图2说明了我们的跟踪器与现有跟踪器之间的主要区别。此外,我们的跟踪器基于轻量级骨干网,在GPU和CPU端都能实时运行,达到了最先进的效果,如图1所示。
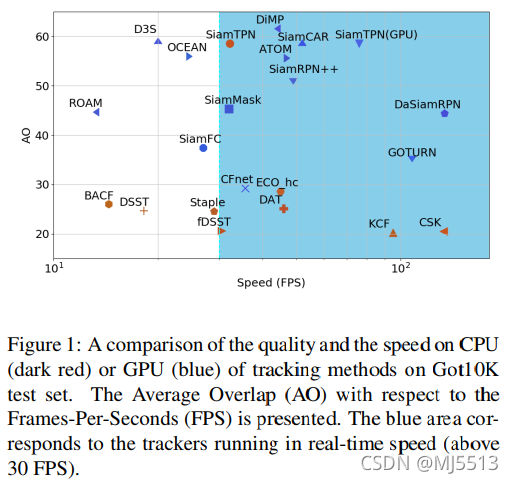
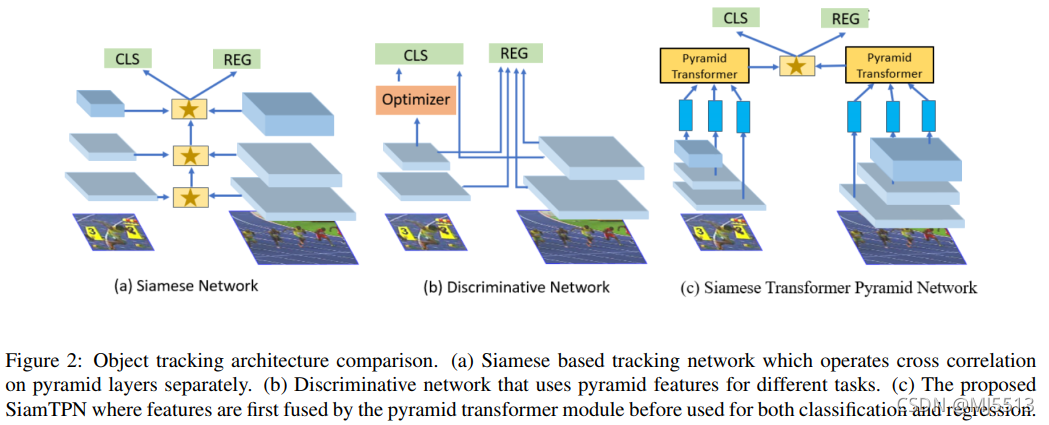
我们的主要贡献总结如下:
1.针对计算资源有限的系统,我们提出了一种新的基于Transformer的跟踪框架。这些系统在仅支持CPU的无人机中通常会遇到。据我们所知,这是第一个基于深度学习的视觉跟踪器,在使用CPU的无人机上以实时速度运行。
2.我们提出了一个轻量级的Transformer层,并将其集成到金字塔网络中,以构建一个高效的框架。
3.在多个基准上的优异性能以及广泛的消融研究证明了所提出的方法的有效性。特别是,我们的方法获得了最先进的结果,在LaSOT[14]上仅使用轻量级主干的AUC得分为58.1,同时在CPU端以超过30 FPS的速度运行。现场测试进一步验证了SiamTPN在实际应用中的有效性。
2.相关工作
2.1 轻量级网络
针对神经网络在移动平台上运行的需求,提出了一系列轻量级模型[24,36,41]。AlexNet[24]充分利用了卷积运算,并在ImageNet[12]分类任务上取得了深刻的结果。MobileNet[41]家族提出倒置残差块,深度分离卷积以节省运算量。ShuffleNet[36]系列是另一个轻量级深度神经网络系列,它引入了通道混洗操作,并针对目标硬件优化了网络设计。
特征金字塔。特征金字塔(即,自下而上特征金字塔)是现代神经网络设计中最常见的体系结构。CNN 的层次结构在逐渐增加的感受野中对上下文进行编码。特征金字塔网络(FPN)[30]和路径聚合网络(PANET)[32]通常用于跨尺度特征交互和多尺度特征融合。FPN包括自下而上和自上而下的路径,用于将语义信息传播到多级特征中。
2.2 目标跟踪
判别相关滤波器(DCF)。自从Mosse[3]和KCF[19]以来,DCF在目标跟踪方面已经显示出很有前途的结果。之后,使用多通道特征、颜色名称和多尺度特征[9,39]来提高跟踪的鲁棒性。通过非线性核[10,28]、长期记忆[8]和深层特征[11,17]实现了进一步的改进。[21,29]进一步提高了无人机跟踪的鲁棒性和优化的DCF。
基于深度学习的目标跟踪。流行的基于Siamese网络家族的跟踪器通过相似性学习解决了对象跟踪问题。SiamRPN[27]引入区域建议网络,联合进行分类和回归。DaSiamRPN[51]通过抗干扰感知模块提高了模型的辨别能力,SiamRPN++[26]通过更强大的深层架构进一步提高了性能。最近的研究成果如SiamBAN[6]、SiamFC++[47]和Ocean[50]用无锚点机制取代了RPN,实现了更快的跟踪速度。DIMP[2]和ATOM[7]在线学习判别分类器,以区分目标和背景。这些方法需要大量的计算,不适合基于CPU的跟踪。
Transformer。Transformer在[45]中首次被提出用于机器翻译,并在许多顺序任务中显示出巨大的潜力。DETR5]首次将Transformer移植到目标检测任务中,并取得了显著的效果。最近的工作[13,49]引入了一种注意力机制来提高跟踪性能。在DETR的启发下,[4]利用变频器直接融合不同层次的相关图,对无人机上的目标跟踪取得了显著的精度和速度。在这项工作中,我们没有迁移复杂的Transformer编码器和解码器范例,而是利用Transformer编码器并设计了基于注意力的特征金字塔融合网络来更有效地学习特定于目标的模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









