







这里主要介绍召回层的技术,包括2个方面,一是召回的策略,另外一个是查找近似向量的策略。
-
召回策略
- 单策略召回:单一无法满足用户潜在多兴趣需求
- 多路召回:可以全面地照顾到不同的召回方法,各个策略之间的数据和信息是割裂的,无法综合考虑多个策略对同一个物品的影响
- 基于embedding召回:既考虑到了多路召回策略,又有评分连续性的特点,embedding线上相似度计算也比较简单。
-
召回层邻近检索方法
- 聚类k-means:虽然可以根据k个中心 进行缩小搜索范围,但是k是超参数,不好确定,并且无法处理边界相似点的问题
- 索引kd-tree:虽然可以利用二叉树找到对应片区进行相似度搜索,但是还是无法解决边界相似的问题,虽然有一些策略比如多棵树或者同时搜索左右子树。
- 局部敏感哈希:
- 索引HNSW(目前最佳的算法): NSW+SkipTable 分层可导航的最小社交网络图
召回层技术
- 召回层和排序层的功能特点
从技术架构的角度,“召回层”处于推荐系统的线上服务模块之中,推荐服务器从数据库或内存中拿到所有候选物品集合后,会依次经过召回层、排序层、再排序层,才能够产生用户最终看到的推荐列表。不同层之间功能特点有什么区别?
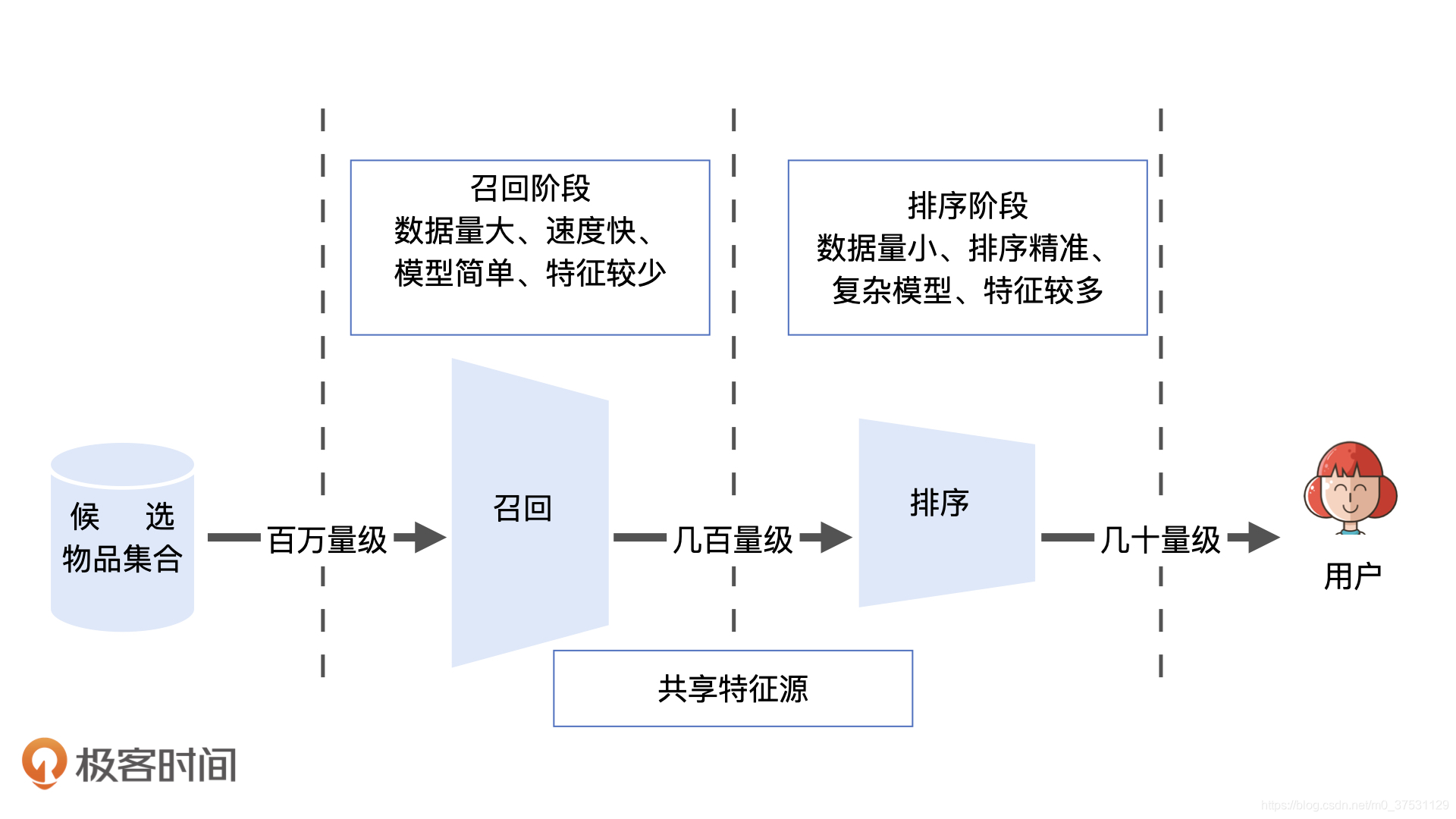
召回层就是要快速、准确地过滤出相关物品,缩小候选集合,排序层则要以提升推荐效果为目标,作为精准的推荐列表排序。
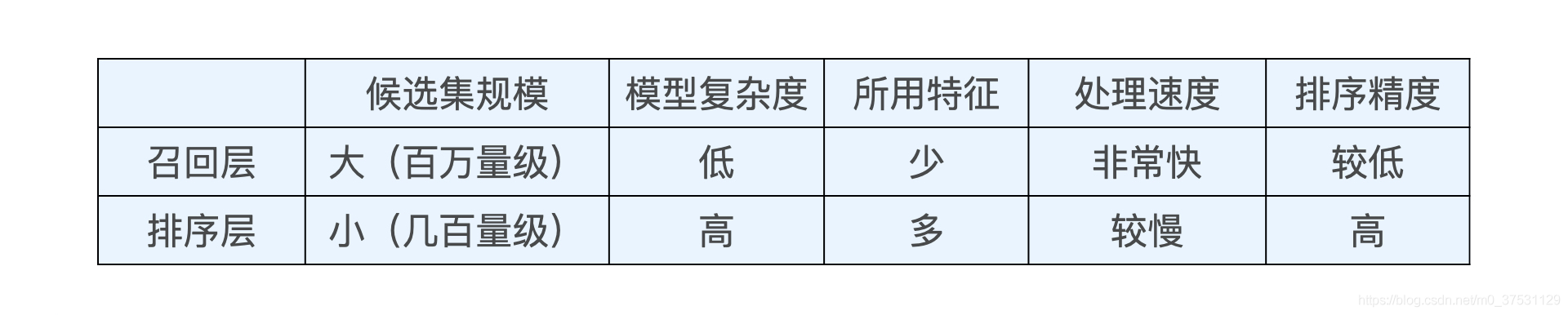
在召回层,计算速度和召回率是两个矛盾的指标。
如何理解“单策略召回"方法?
单策略召回指的是,通过指定一条规则或利用一个简单模型来快速地召回可能的相关物品。这里的规则其实就是用户可能感兴趣的物品的特点,比如推荐电影时,很有可能是三类:大众口碑好的、近期火热的、用户喜欢风格的电影。
基于以上任何一条,我们都可以快速实现一个单策略召回层。特点是非常快。局限性也很强,因为大多数用户的兴趣是多元的,单策略很难满足用户的潜在需求。
如何理解"多路召回"方法
为了让召回的结果更加全面,多路召回方法应运而生。
”多路召回策略”,就是指采用不同的策略、特征或简单模型,分别召回一部分候选集,然后把候选集混合在一起供后续排序模型使用的策略。
其中,各简单策略保证候选集的快速召回,从不同角度设计的策略又能保证召回接近理想状态,所以多路召回策略是在计算速度和召回率之间进行权衡的结果。
比如 电影推荐中常用的多路召回策略, 包括热门电影、风格类型、高分评价、最新上映以及朋友喜欢等,除此以外,我们也可以把一些推断速度比较快的简单模型(逻辑回归、协同过滤等)生成的推荐结果放入多路召回层中,形成综合性更好的候选集。具体步骤:分别执行这些策略,让每个策略选取topk个物品,最后混合多个topk物品,就形成了多路召回候选集。
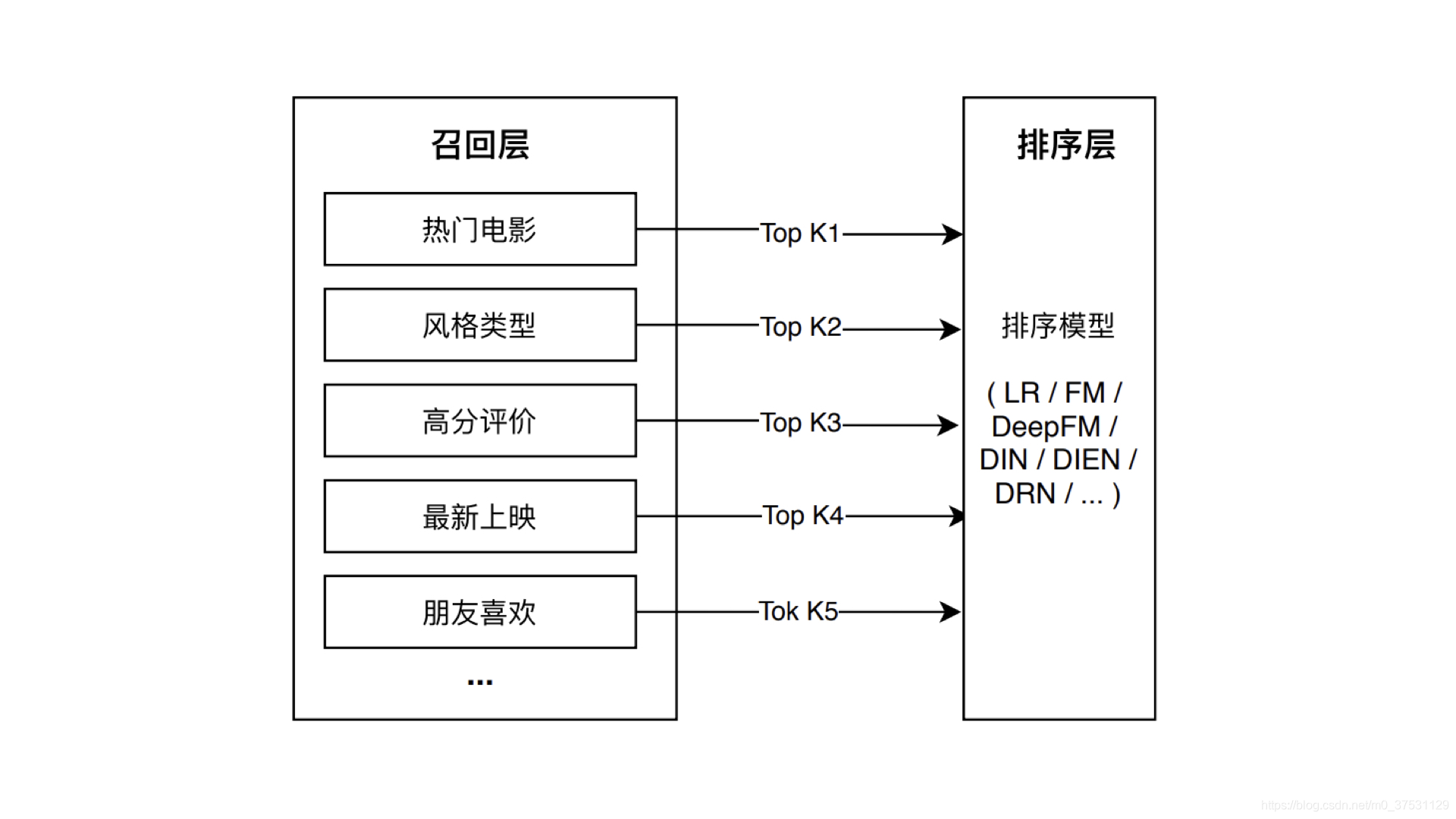
在实现多路召回中,为了进一步优化召回效率,还可以通过多线程并行、建立标签、特征索引、建立常用召回集缓存等方法来进一步完善它。
多路召回策略虽然可以全面地照顾到不同的召回方法,但是也存在一些缺点,比如在确定每一路的召回物品数量时,往往需要大量的人工参与和调整,具体的数值需要线上AB测试确定,此外,因为策略之间的信息和数据是割裂的,所以很难综合考虑不同策略对一个物品的影响。
基于Embedding的召回方法
利用物品和用户Embedding相似性来构建召回层,是深度学习推荐系统中非常经典的技术方案。优势有三个方面:
- 首先,多路召回中使用的“兴趣标签”,“热门度”,“流行趋势”,“物品属性”等信息都可以做为Emebdding方法中的附加信息,融合进最终的Embedding向量中,因此,利用Embedding召回的过程中,我们就相当于考虑了多路召回的多种策略。
- 其次,Embedding召回的评分具有连续性。多路召回中不同召回策略产生的相似度、Reduce等分支不具备可比性,所以我们无法据此来决定每个召回策略放回候选集合的大小,但是Embeddign召回可以把Emebdding间的相似度作为唯一的判断标准,因此它可以随意限定召回的候选集大小。
- 最后,在线上服务过程中,Emebdding相似性的计算也相对简单而直接,通过简单的点积或余弦相似度运算就能够得到相似度得分,便于线上召回。
- 获取用户的Embedding,
- 获取所有物品的候选集,并且逐一获取物品的embedding, 计算物品embedding和用户emebdding的相似度,
- 根据相似度排序返回规定大小的候选集合
这3步中,最主要的时间开销是第2步,虽然时间复杂度上线性的,但是当物品集过大时,线性运算也会有很大的时间开销,那么如何进一步缩小embeding召回的运算时间呢?
局部敏感哈希
在常数时间内搜素Embedding最近邻。
两份方法:聚类,索引。
聚类:把相似的点聚类到一起,快速地找到彼此最近邻的点。
索引:通过某种数据结构建立基于向量距离的索引,在查找最近邻的时候,通过索引快速缩小范围来降低复杂度。
- 聚类k-means: 虽然可以根据聚类结果缩小查找范围,但是缺点聚类中心k的数量不好确定,太大或者太小都会给离线和上线带来麻烦,并且无法处理边界点。
- 索引kd-tree: 虽然可以根据树的方式进行片区快速搜索,但是也无法解决边界问题,比如相似的在旁边的片区,并且kd-tree结构复杂,在线和离线维护也比较麻烦。
聚类K-means
步骤:
- 随机指定K个中心点
- 每个中心点代表一个类,把所有的点按照距离的远近指定给距离最近的中心点代表的类
- 计算每个类包含点的平均值作为新的中心点位置
- 确定好新的中心点位置后,迭代进入第2步,直到中心点位置收敛,不再移动。
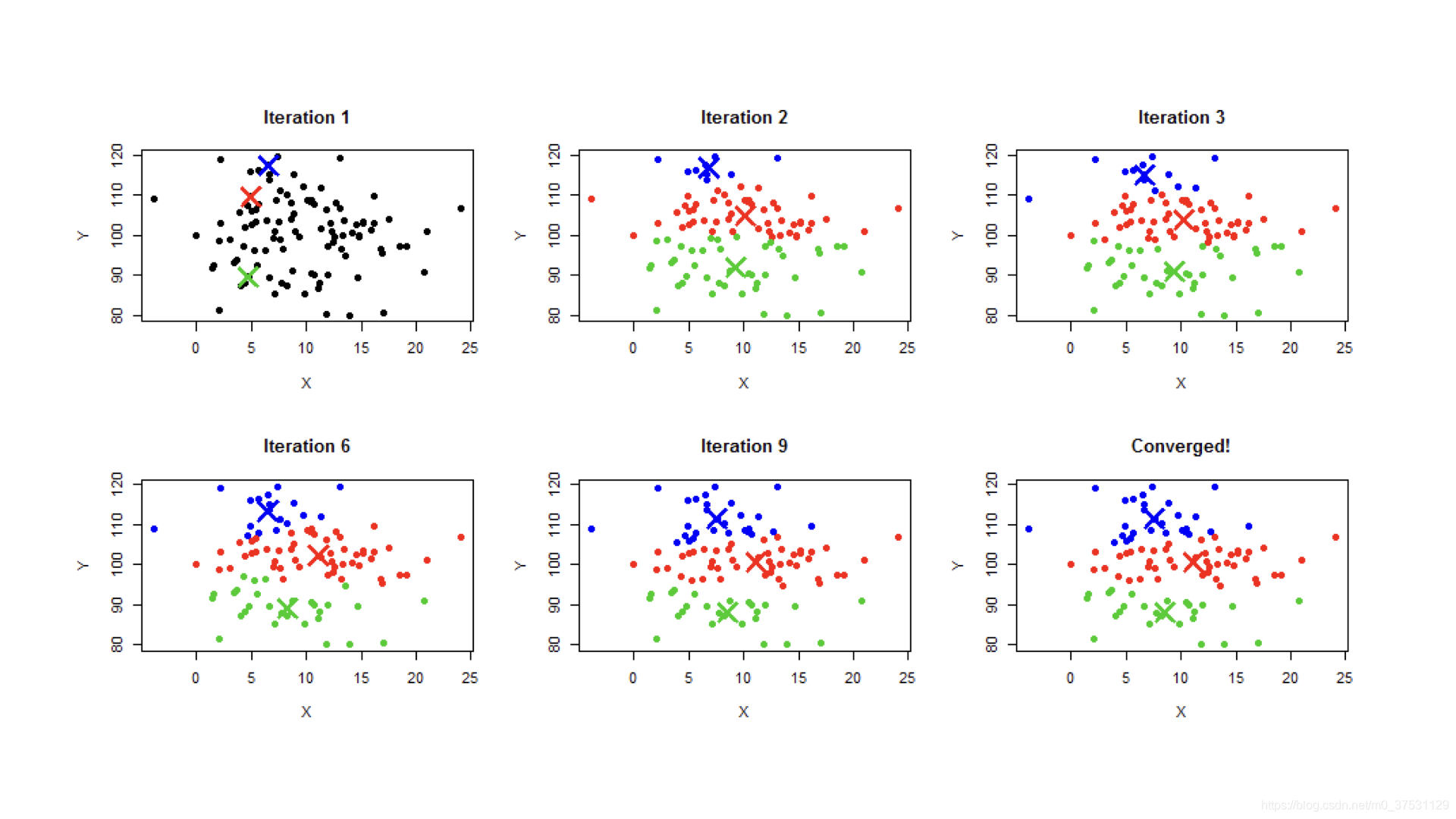
如果我们能够在离线计算好每一个Emebdding向量的类别,在线上我们只需要在同一类别内的Embedding向量中搜索就可以了,这会大大缩小了Embedding的搜索范围,时间复杂度自然下降了。
这个过程还存在着一些边界情况。比如,聚类边缘的点的最近邻往往会包括相邻聚类的点,如果我们只在类别内搜索,就会遗漏这些近似点。此外,中心点的数量k 也是超参数,不好确定,k选太大,离线迭代会非常慢,k选太小,在线搜索范围还是很大,并没有减少太多的搜索时间。所以基于聚类的搜索还有一定的局限性,解决上面的问题也会增加过多冗余过程,得不偿失。
kd-tree 索引
既然聚类有局限性,那么索引 会不会更好呢?下面可以看 经典的 向量空间索引方法 kd-tree,与聚类不同,它是为空间中的点-向量建立一个索引。比如下图,我们先用红色的线把点一分为二,再用深蓝色的线把各自片区的点一分为二,依次类推,直到每个片区只剩下一个点,就完成了空间索引的构建。如果这个索引搬到线上,就可以利用二叉树的结构快速找到邻接点。比如希望找到q的m个邻节点,我们可以先搜索它相邻子树下的点,如果数量不够,可以回退一个层级,搜索它父片区下的其他点,直到数量凑够m个为止。
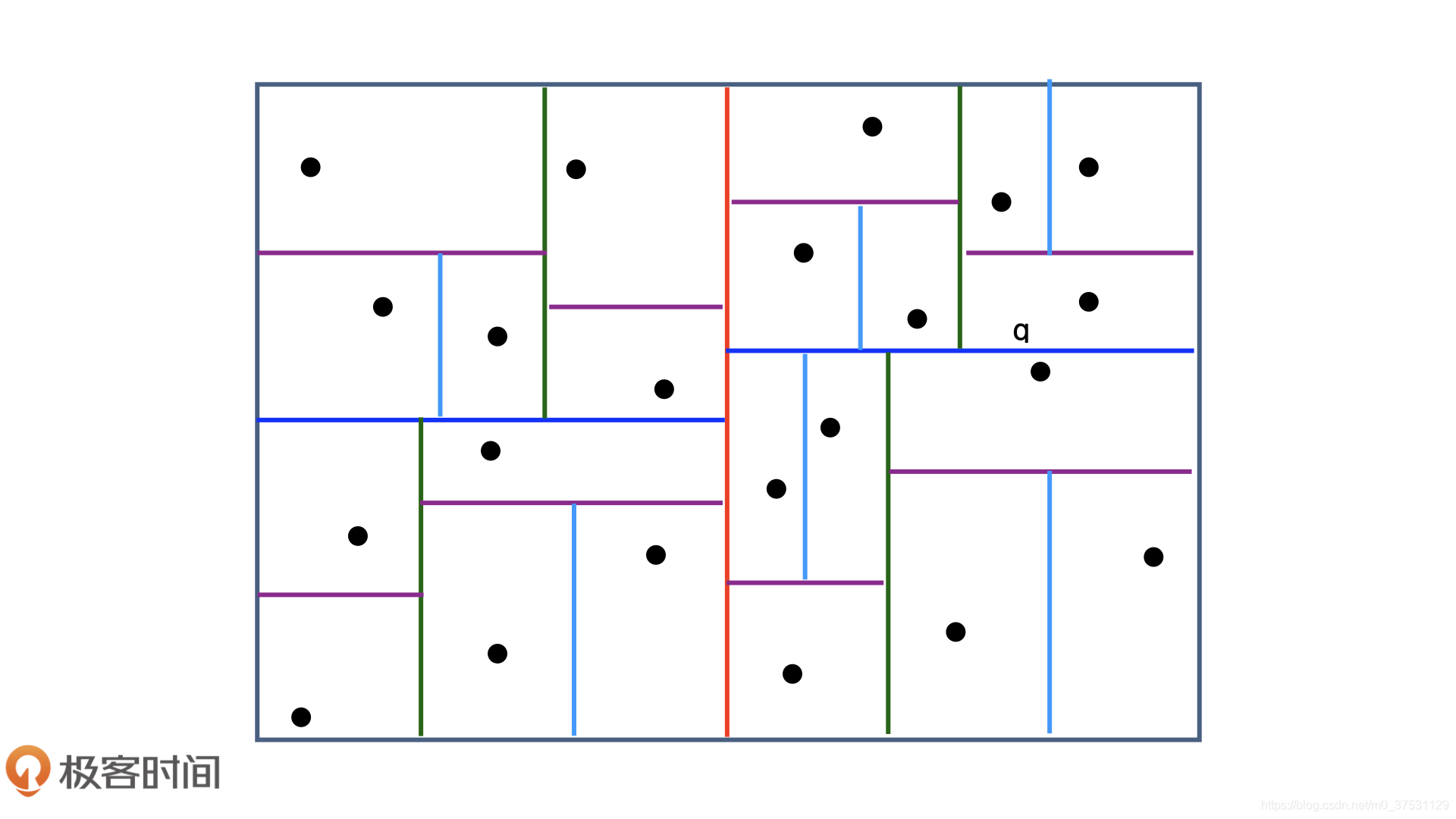
看上去kd-tree貌似是一个完美的解决方案,但是它还是无法完全解决边缘点最近邻的问题。对于点q来说,它的邻接片区是右上角的片区,但是它的最近邻点却是深蓝色切分线下方的点。所以按照kd-tree的索引方法,我们还是会遗漏掉最近邻点,它只能保证快速搜索到近似的最近邻点集合,而kd-tree索引的结构并不简单,离线和在线的维护过程也相对复杂,都是它的弊端。
局部敏感哈希的原理及多桶策略
为了拯救推荐系统的召回层,“局部敏感哈希”出来了,简洁高效几乎完美地解决了这个问题。
-
局部敏感哈希的原理
局部敏感哈希的基本思想是希望让相邻的点落入同一个“桶”,这样在金乡最近邻搜索时,我们仅需要在一个桶内,或相邻的几个桶内的元素进行搜索即可。如果保持每个桶中的元素个数在一个常数附近,我们就可以把最近邻搜索的时间复杂度降低到常数级别。如何构建局部敏感哈希中的“桶”?下面以欧式距离的最近邻搜索为例,来解释构建局部敏感哈希“桶”的过程。
- 首先,弄清楚一个问题,如果将高维空间中的点向低维空间进行映射,其在欧式相对距离是不是会保持不变呢?欧式空间中,将高维空间的点映射到低维空间,原本接近的点在低纬空间中肯定依然接近,但原本远离的点则有一定的改了变成接近的点。
- 利用低维空间可以保留高维空间相近距离关系的性质,我们就可以构造局部敏感哈希“桶”。对于Embedding向量来说,由于Embedding大量使用内积操作计算相似度,因此我们也可以用内积操作来构建局部敏感哈希桶。假设v是高维空间中的k维Embedding向量,x是随机生成的k维映射向量,那我们利用内积操作可以将v映射到一维空间,得到数值h(v)=v*x.
- 一维空间会保留高维空间的近似距离信息,因此,我们可以使用哈希函数h(v)进行分桶,公式为: h x , b ( v ) = x w + b w h^{x,b}(v)=\frac{xw+b}{w} hx,b(v)=wxw+b 其中w是分桶宽度,b是0到w的一个均匀分布随机变量,避免分桶边界固化。
- 映射操作会损失部分距离信息,如果我们仅采用一个哈希函数进行分桶,必然存在相近点误判的情况,因此,我们可以采用m个哈希函数同时进行分桶。如果两个点同时掉进了m个桶,那么他们是相似点的概率将大大增加。通过分桶找到相近点的候选集合,我们就可以在有限的候选集合中通过遍历找到目标点真正的k近邻。
-
局部敏感哈希的多桶策略
使用多个分桶函数的方式来增加找到相似点的概率,那么如果有多个桶函数的话,具体应该如何处理不同桶之间的关系呢?这就是局部敏感哈希的多桶策略。
假设有ABCDE五个点,有h1和h2两个分桶函数,使用h1来分桶时,AB掉进一个桶里面,CDE掉进一个桶里面,使用h2来分桶时,ACD掉到了一个桶里面,BE在一个桶,那么请问如果我们想要找到C的最近邻的点,应该如何利用2个分桶的结果来计算呢?。。。。
参考:极客时间-推荐系统














 1263
1263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









