







今天我们来讲讲召回层。在讲召回层前,先了解下推荐系统的整体组成部分。
一个工业级推荐系统的技术架构按照数据部分和模型部分展开,其中“数据和信息”部分逐渐发展为推荐系统中融合了数据离线批处理、实时流处理的数据流框架;“算法和模型”部分则进一步细化为推荐系统中,集训练(Training)、评估(Evaluation)、部署(Deployment)、线上推断(Online Inference)为一体的模型框架。基于此,我们就能总结出推荐系统的技术架构图。
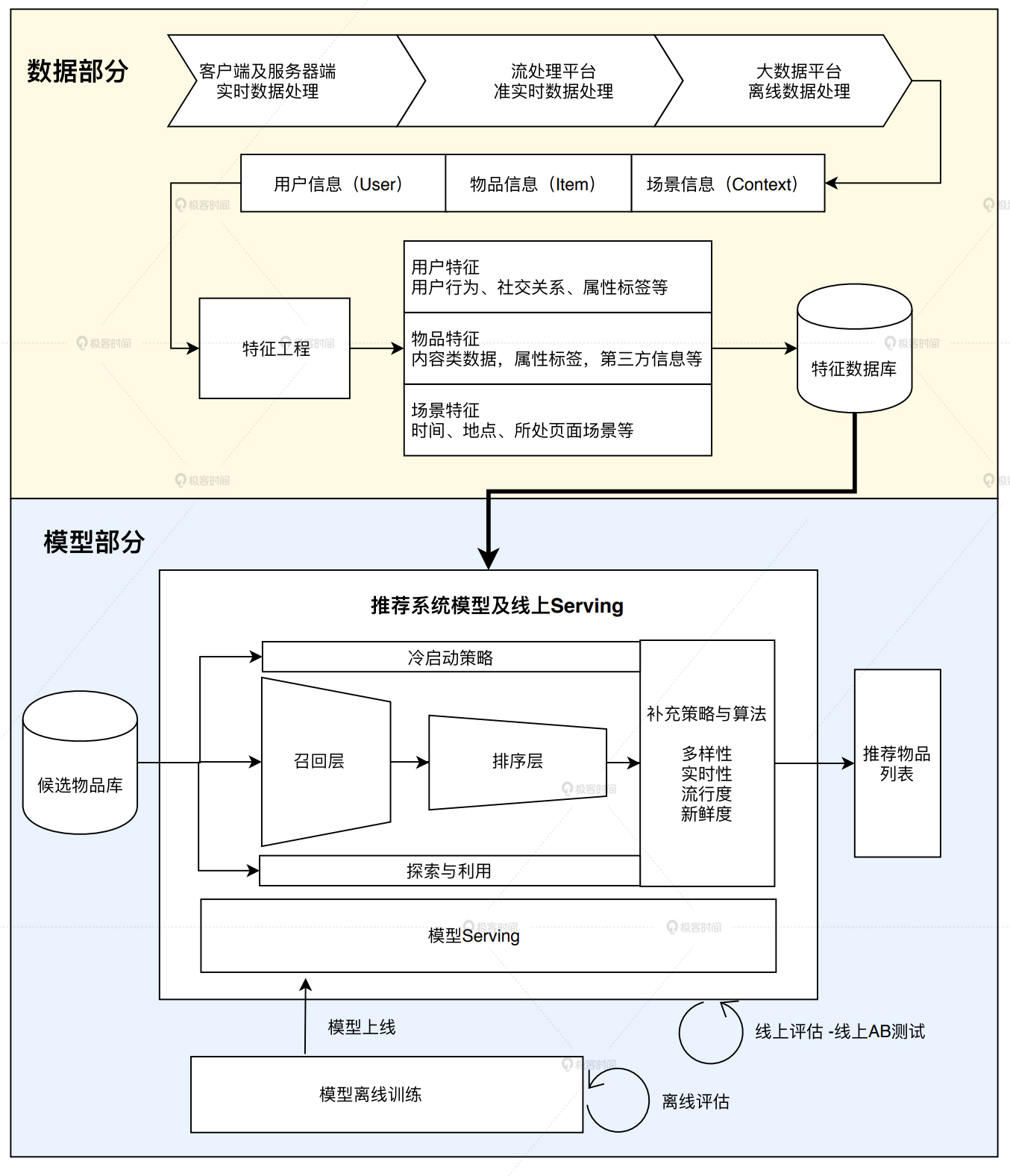
其中,在模型部分中最重要的就是 召回层 和 排序层。
-
"召回层"一般由高效的召回规则、算法或简单的模型组成,这让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品。
-
“排序层”,也称精排层,是利用排序模型对初筛的候选集进行精排序。
-
“补充策略与算法层”,也被称为“再排序层”,是在返回给用户推荐列表之前,为兼顾结果的“多样性”“流行度”“新鲜度”等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。
在召回阶段候选集的规模大,模型复杂率低,所用特征少,处理速度特别快,排序京精度较低,基于这几个角度主要有三种主要的召回方法。
单策略召回
单策略召回指的是,通过制定一条规则或者利用一个简单模型来快速地召回可能的相关物品。
在电影推荐中,最新上映反响好的,与用户自身历史电影观看风格类似的,大众口碑好的这三个因素是用户选择观看的重要因素。基于其中的任何一条,进行召回策略。例如:给用户推荐的电影列表中,若某个电影的风格为A、B风格,则各筛选出所有电影中A、B风格,且瓶觉评分在100的电影召回,并对召回的电影合并去重,放入排序候选集中,具体方法见candidateGenerator。
//get movies by genre, and order the movies by sortBy method
public List<Movie> getMoviesByGenre(String genre, int size, String sortBy){
if (null != genre){
List<Movie> movies = new ArrayList<>(this.genreReverseIndexMap.get(genre));
//根据rating活releaseYear降序排序
switch (sortBy){
case "rating":movies.sort((m1, m2) -> Double.compare(m2.getAverageRating(), m1.getAverageRating()));break;
case "releaseYear": movies.sort((m1, m2) -> Integer.compare(m2.getReleaseYear(), m1.getReleaseYear()));break;
default:
}
//过滤出movies的数量为size
if (movies.size() > size){
return movies.subList(0, size);
}
return movies;
}
return null;
}
/**
* generate candidates for similar movies recommendation
* @param movie input movie object
* @return movie candidates
*/
public static List<Movie> candidateGenerator(Movie movie){
//使用HashMap去重
HashMap<Integer, Movie> candidateMap = new HashMap<>();
//电影movie包含多个风格标签
for (String genre : movie.getGenres()){
//召回策略的实现
List<Movie> oneCandidates = DataManager.getInstance().getMoviesByGenre(genre, 100, "rating");
for (Movie candidate : oneCandidates){
candidateMap.put(candidate.getMovieId(), candidate);
}
}
//去掉movie本身
candidateMap.remove(movie.getMovieId());
//最终的候选集
return new ArrayList<>(candidateMap.values());
}
多路召回
所谓“多路召回策略”,就是指采用不同的策略、特征或简单模型,分别召回一部分候选集,然后把候选集混合在一起供后续排序模型使用的策略。
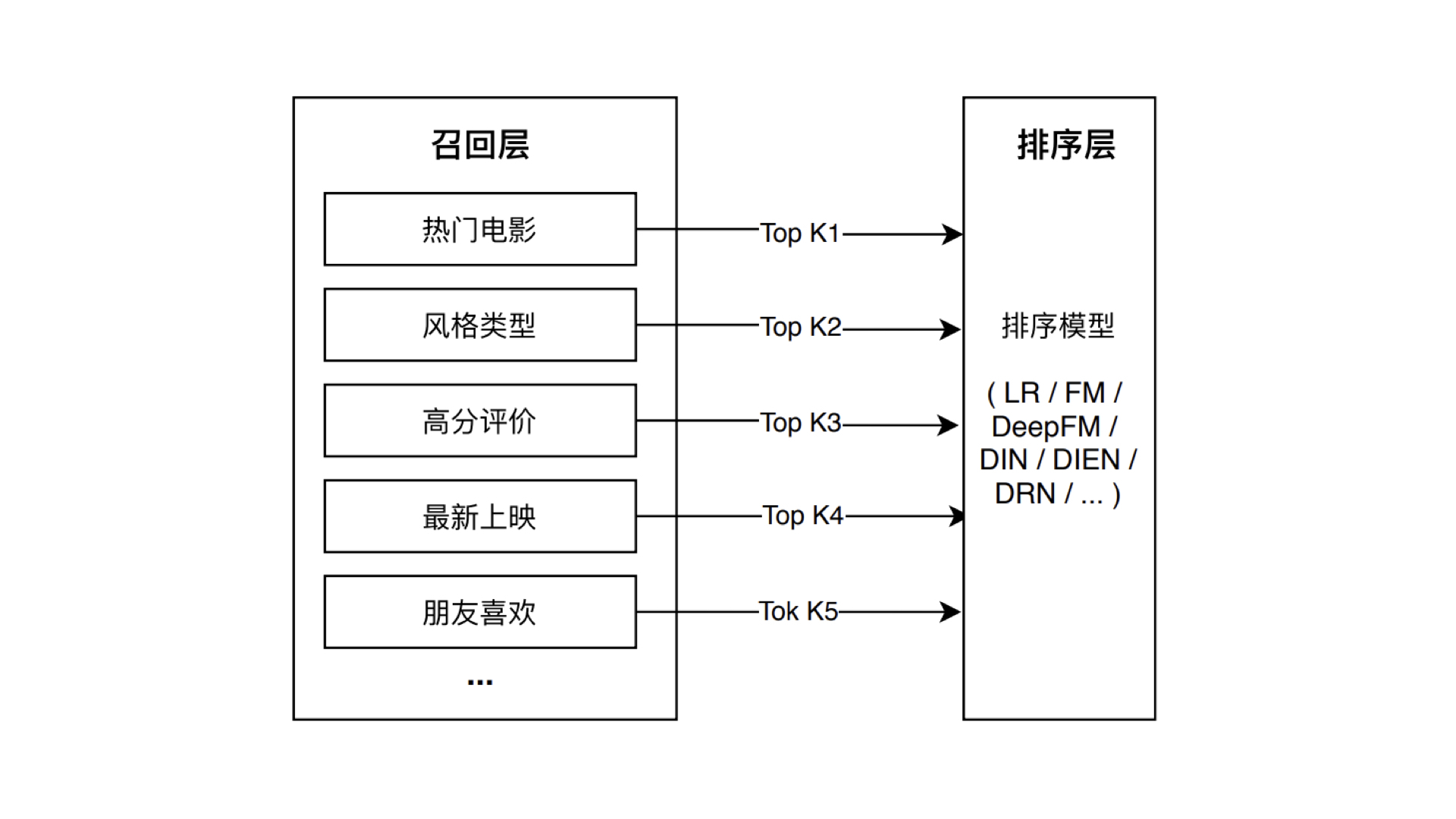
例如:风格类型选择同一类电影平均评分Top20(风格类型)、所有电影平均评分Top100(高分评价)、上映年份Top100(最新上映),将其候选集合并去重。见multipleRetrievalCandidates。
/**
* multiple-retrieval candidate generation method
* @param movie input movie object
* @return movie candidates
*/
public static List<Movie> multipleRetrievalCandidates(Movie movie){
if (null == movie){
return null;
}
//统计当前电影的电影风格
HashSet<String> genres = new HashSet<>(movie.getGenres());
HashMap<Integer, Movie> candidateMap = new HashMap<>();
//召回同一类型电影中排名最高的20部电影
for (String genre : genres){
List<Movie> oneCandidates = DataManager.getInstance().getMoviesByGenre(genre, 20, "rating");
for (Movie candidate : oneCandidates){
candidateMap.put(candidate.getMovieId(), candidate);
}
}
//召回所有电影中排名最高的100部电影
List<Movie> highRatingCandidates = DataManager.getInstance().getMovies(100, "rating");
for (Movie candidate : highRatingCandidates){
candidateMap.put(candidate.getMovieId(), candidate);
}
//召回最新上映的100部电影
List<Movie> latestCandidates = DataManager.getInstance().getMovies(100, "releaseYear");
for (Movie candidate : latestCandidates){
candidateMap.put(candidate.getMovieId(), candidate);
}
//去除当前电影
candidateMap.remove(movie.getMovieId());
//形成最终的候选集
return new ArrayList<>(candidateMap.values());
}
基于Embedding召回
Embedding 召回可以把 Embedding 间的相似度作为唯一的判断标准,因此它可以随意限定召回的候选集大小。而不用考虑单策略召回以及多路召回中召回的数据集大小,以及召回策略的选择情况。
代码见retrievalCandidatesByEmbedding。
//calculate cosine similarity between two embeddings
public double calculateSimilarity(Embedding otherEmb){
if (null == embVector || null == otherEmb || null == otherEmb.getEmbVector()
|| embVector.size() != otherEmb.getEmbVector().size()){
return -1;
}
double dotProduct = 0;
double denominator1 = 0;
double denominator2 = 0;
//通过点积运算获得相似度得分
for (int i = 0; i < embVector.size(); i++){
dotProduct += embVector.get(i) * otherEmb.getEmbVector().get(i);
denominator1 += embVector.get(i) * embVector.get(i);
denominator2 += otherEmb.getEmbVector().get(i) * otherEmb.getEmbVector().get(i);
}
return dotProduct / (Math.sqrt(denominator1) * Math.sqrt(denominator2));
}
}
/**
* function to calculate similarity score based on embedding
* @param movie input movie
* @param candidate candidate movie
* @return similarity score
*/
public static double calculateEmbSimilarScore(Movie movie, Movie candidate){
if (null == movie || null == candidate){
return -1;
}
return movie.getEmb().calculateSimilarity(candidate.getEmb());
}
}
/**
* embedding based candidate generation method
* @param movie input movie
* @param size size of candidate poolretrievalCandidatesByEmbedding·
* @return movie candidates
*/
//获取电影embedding向量
public static List<Movie> retrievalCandidatesByEmbedding(Movie movie, int size){
if (null == movie || null == movie.getEmb()){
return null;
}
//获取所有影片候选集(这里取评分排名前10000的影片作为全部候选集)
List<Movie> allCandidates = DataManager.getInstance().getMovies(10000, "rating");
HashMap<Movie,Double> movieScoreMap = new HashMap<>();
//逐一获取电影embedding,并计算与当前电影embedding的相似度
for (Movie candidate : allCandidates){
double similarity = calculateEmbSimilarScore(movie, candidate);
movieScoreMap.put(candidate, similarity);
}
List<Map.Entry<Movie,Double>> movieScoreList = new ArrayList<>(movieScoreMap.entrySet());
//按照电影-电影embedding相似度进行候选电影集排序
movieScoreList.sort(Map.Entry.comparingByValue());
//生成并返回最终的候选集
List<Movie> candidates = new ArrayList<>();
for (Map.Entry<Movie,Double> movieScoreEntry : movieScoreList){
candidates.add(movieScoreEntry.getKey());
}
return candidates.subList(0, Math.min(candidates.size(), size));
}















 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









