







目录
1.Spak简介
Apache Spark是一个通用的、基于内存的分布式计算引擎,用于大规模数据处理。它的核心原理是将数据分散到多台计算机上并在这些计算机上并行执行计算任务,从而实现高效的数据处理和分析。
2.spark 运行架构
Spark 框架的核心是一个分布式计算引擎,它采用了标准 master-slave 的结构。如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。
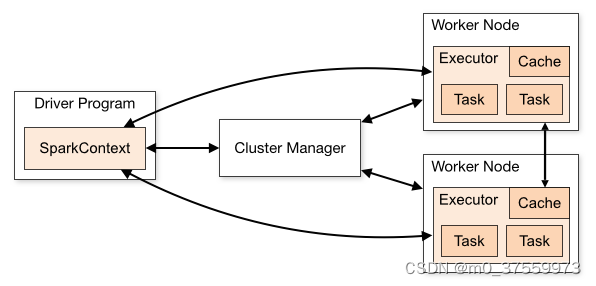
- SparkContext:Spark应用程序的入口,负责与Cluster Manager进行通信,协调集群资源的分配。
- Driver:运行SparkContext的节点,负责任务的调度和管理。
- Executor:是集群中工作节点(Worker Node)上运行的JVM进程,负责执行具体的任务,任务彼此之间互相独立。Executor为Spark应用程序提供分布式计算和数据存储功能。
- Cluster Manager:负责管理整个Spark集群,与SparkContext进行通信,分配集群资源。可以是Spark自带的集群管理器,也可以是其他的集群管理系统如Hadoop YARN、Mesos等。
3.Spark 部署模式
3.1 Local 模式
所谓的 Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,解压即可使用。
3.2 Standalone 模式
Local 本地模只适用于练习环境,生产环境中还是需要到集群中去执行任务。Spark 的 Standalone 模式是经典的 master-slave 模式。
Standalone 模式具体部署步骤请参考:搭建环境05:部署Spark-Standalone模式-CSDN博客
3.3 Yarn 模式
Standalone模式由 Spark 自身提供计算资源,无需其他框架提供资源。Spark是计算框架,资源管理不是它的强项,可由更专业的Yarn框架负责资源管理。
Yarn 模式具体部署部署请参考:部署Spark-YARN模式-CSDN博客
4. Spark 程序结构
Spark程序一般可包含以下几个部分构成:
1.初始化SparkContext对象
2.加载数据源
3.对数据进行加工
4.输出加工后的数据
5.停止SparkContext
- Java代码示例
package com.yichenkeji.demo.sparkjava;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.Arrays;
import java.util.List;
public class SparkApp {
public static void main(String[] args) {
//1.初始化SparkContext对象
SparkConf sparkConf = new SparkConf().setAppName("Spark Java").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
//2.加载数据源:员工工资
List<Integer> salary = Arrays.asList(1000,2000,3000,4000,4000);
JavaRDD<Integer> salaryRDD = sc.parallelize(salary);
//3.对数据进行加工:全部员工工资翻倍
JavaRDD<Integer> salaryMap = salaryRDD.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer s) throws Exception {
return s * 2;
}
});
//4.输出加工后的数据:直接打印到控制台
salaryMap.collect().forEach(s->System.out.println(s));
//5.停止SparkContext
sc.stop();
}
}
- Scala代码示例
package com.yichenkeji.demo.sparkscala
import org.apache.spark.{SparkConf, SparkContext}
object SparkApp {
def main(args: Array[String]): Unit = {
//1.初始化SparkContext对象
val sparkConf = new SparkConf().setAppName("Spark Scala").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.加载数据源:员工工资
val salary = Array(1000,2000,3000,4000,5000)
val salaryRDD = sc.parallelize(salary)
//3.对数据进行加工:全部员工工资翻倍
val salaryMap = salaryRDD.map(s=>{
s*2
})
//4.输出加工后的数据:直接打印到控制台
salaryMap.collect().foreach(s => println(s))
//5.停止SparkContext
sc.stop()
}
}
5. Spark 提交任务
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://01.weisx.com:7077 ./examples/jars/spark-examples_2.12-3.2.3.jar 10
1) --class 表示要执行程序的主类
2) --master spark://01.weisx.com:7077 独立部署模式,连接到 Spark 集群
3) spark-examples_2.12-3.2.3.jar 运行类所在的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
spark-submit常用参数说明
| 参数名称 | 参数说明 |
|---|---|
| master | 设置主节点 URL 的参数。支持: local: 本地机器。 spark://host:port:远程 Spark 单机集群。 yarn:yarn 集群 |
| deploy-mode | 允许选择是否在本地(使用 client 选项)启动 Spark 驱动程序,或者在集群内(使用 cluster 选项)的其中一台工作机器上启动。默认值是 client。 |
| num-executors | 配置 Executor 的数量 |
| executor-memory | 配置每个 Executor 的内存大小 |
| executor-cores | 配置每个 Executor 的虚拟 CPU core 数量 |















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











