







目录
一、SWIFT 介绍
SWIFT(Scalable lightWeight Infrastructure for Fine-Tuning)是魔搭ModelScope开源社区推出的一套完整的轻量级训练、推理、评估和部署工具,支持200+大模型、15+多模态大模型以及10+轻量化Tuners,让AI爱好者能够使用自己的消费级显卡玩转大模型和AIGC。
SWIFT 框架主要特征特性:
- 具备SOTA特性的Efficient Tuners:用于结合大模型实现轻量级(在商业级显卡上,如RTX3080、RTX3090、RTX4090等)训练和推理,并取得较好效果
- 使用ModelScope Hub的Trainer:基于transformers trainer提供,支持LLM模型的训练,并支持将训练后的模型上传到ModelScope Hub中
- 可运行的模型Examples:针对热门大模型提供的训练脚本和推理脚本,并针对热门开源数据集提供了预处理逻辑,可直接运行使用
- 支持界面化训练和推理
二、SWIFT 安装
SWIFT在Python环境中运行。请确保您的Python版本高于3.8。swift下载模型默认是home目录,可通过设置环境变量:os.environ['MODELSCOPE_CACHE']='your path' 修改目录。
2.0 配置环境(可选)
# 创建新的conda虚拟环境
conda create -n swift python=3.11 -y
conda activate swift# 设置pip全局镜像
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/#pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
2.1 使用pip进行安装
pip install 'ms-swift'
# 使用评测
pip install 'ms-swift[eval]' -U
# 使用序列并行
pip install 'ms-swift[seq_parallel]' -U
# 全能力
pip install 'ms-swift[all]' -U
2.2 源代码安装
# 源码安装
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
# 全能力
# pip install -e '.[all]'
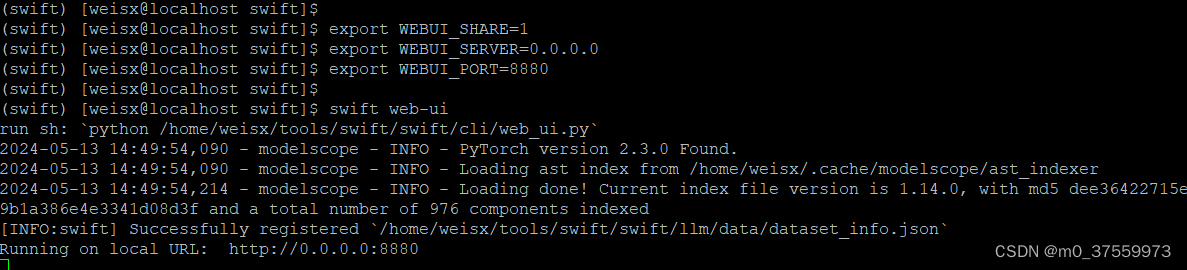
2.3 启动 WEB-UI
export WEBUI_SHARE=1
export WEBUI_SERVER=0.0.0.0
swift web-ui
web-ui没有传入参数,所有可控部分都在界面中。但是有几个环境变量可以使用:
- WEBUI_SHARE=1:控制gradio是否是share状态
- SWIFT_UI_LANG=en/zh:控制web-ui界面语言
- WEBUI_SERVER:server_name参数, web-ui host ip,0.0.0.0代表所有ip均可访问,127.0.0.1代表只允许本机访问
- WEBUI_PORT:web-ui的端口号
三、部署模型
swift可以使用VLLM作为推理后端, 并兼容openai的API样式。
3.1 deploy命令参数
deploy参数继承了infer参数, 除此之外增加了以下参数:
- --host: 默认为'127.0.0.1.
- --port: 默认为8000.
- --ssl_keyfile: 默认为None.
- --ssl_certfile: 默认为None.
3.2 部署原始模型
服务端:
# 原始模型默认下载到~/.cache/modelscope/hub/目录下,可以通过export MODELSCOPE_CACHE=/data/weisx/swift/ 指定目录
CUDA_VISIBLE_DEVICES=0 swift deploy --host 0.0.0.0 --model_type qwen1half-4b-chat
#也可以使用已下载好的模型
CUDA_VISIBLE_DEVICES=0 swift deploy --host 0.0.0.0 --model_type qwen1half-4b-chat --model_id_or_path /data/weisx/model/Qwen1.5-4B-Chat
# 使用VLLM加速
CUDA_VISIBLE_DEVICES=0 swift deploy --model_type qwen1half-4b-chat\
--infer_backend vllm --max_model_len 8192
# 多卡部署
RAY_memory_monitor_refresh_ms=0 CUDA_VISIBLE_DEVICES=0,1,2,3 swift deploy --model_type qwen1half-4b-chat --tensor_parallel_size 4
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1456
1456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











