






目录
1.Kafka简介
Apache Kafka是一个开源分布式事件流平台,也是一种高吞吐量的分布式发布订阅消息系统,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序。
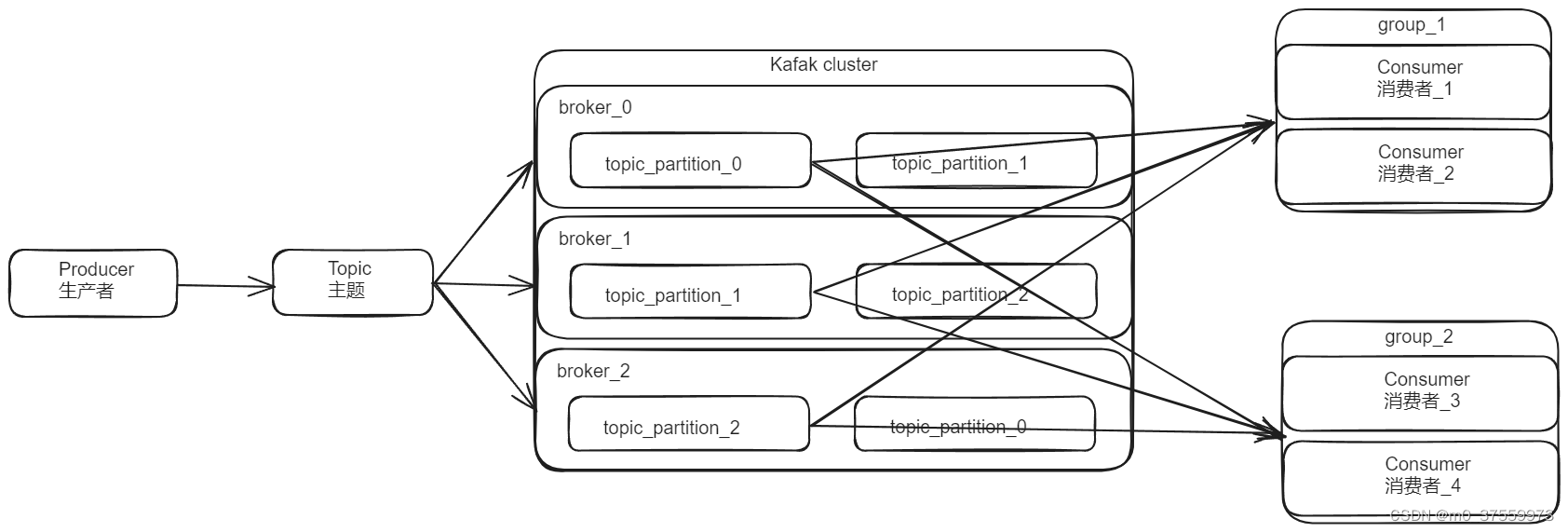
- Broker(代理节点):一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
- Topic(主题):可以理解为一个队列,生产者和消费者面向的都是一个 topic。
- Partition(分区):个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
- Replica(副本):一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- Leader (主副本):每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
- Follower (从副本):每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
- Producer(生产者):生产者负责将消息发送到 Kafka 集群。
- Consumer(消费者):消费者负责从 Kafka 集群中拉取并消费消息。
- Consumer Group(消费者组):每组由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
2.安装Kafka
2.1 安装JDK
Kafka需要jdk1.8+环境。
2.2 下载、解压Kafka
tar -zxf kafka_2.12-3.4.0.tgz -C ~/opt/

2.3 启动Kafka
Kafka可以使用Zookeeper或KPaft两种模式启动。Kafka3.x开始提供KRaft(Kafka Raft,依赖Java 8+ )模式,最新的3.6版本中,Kafka依然兼容zookeeper。
1. Zookeeper模式启动
1.启动Zookeeper,可以使用Kafka自带的zookeeper或者使用已部署好的zookeeper环境都可以,如果使用已部署好的zookeeper,需要修改kafka的配置文件(config/server.properties),指定zookeeper地址(zookeeper.connect=localhost:2181,localhost:2182)。这里直接使用Kafka自带zookeeper启动。
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
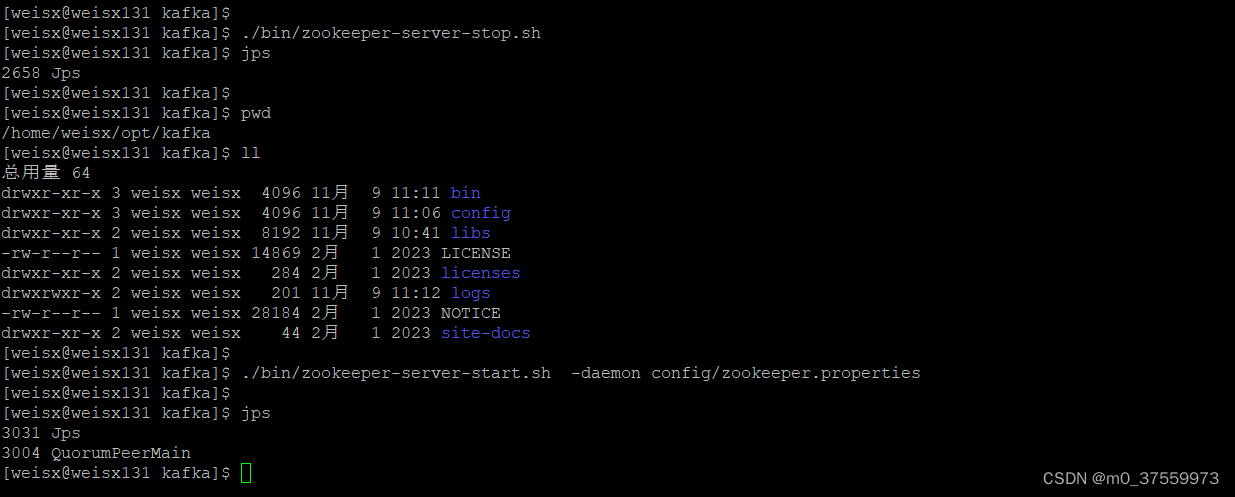
2.启动Kafka服务
./bin/kafka-server-start.sh -daemon config/server.properties

2. KRaft模式启动
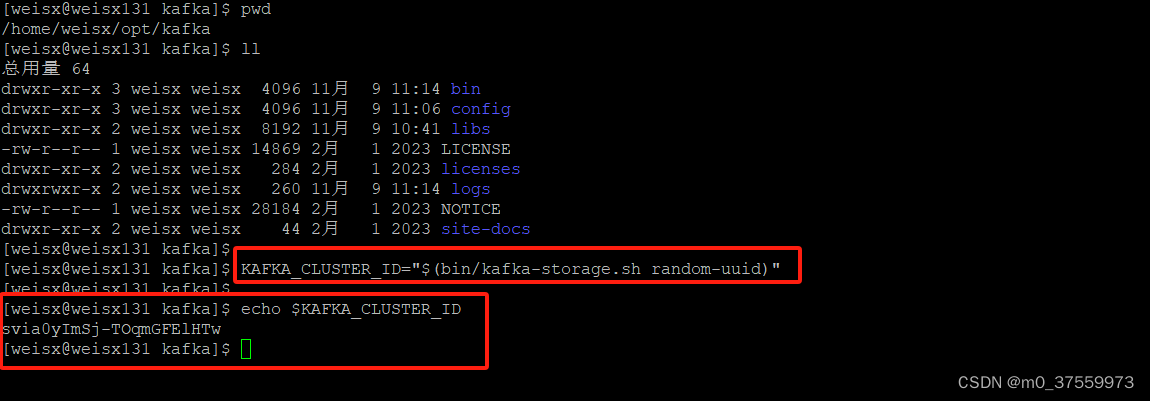
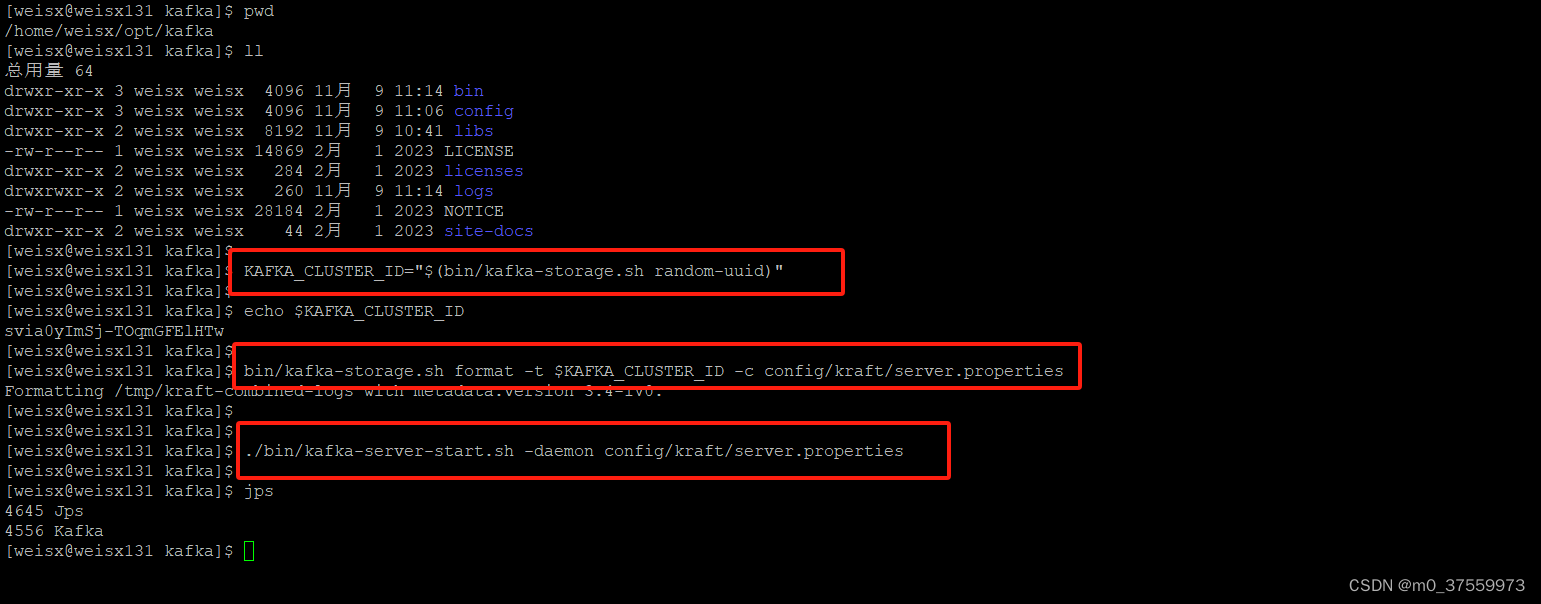
1.生成集群ID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
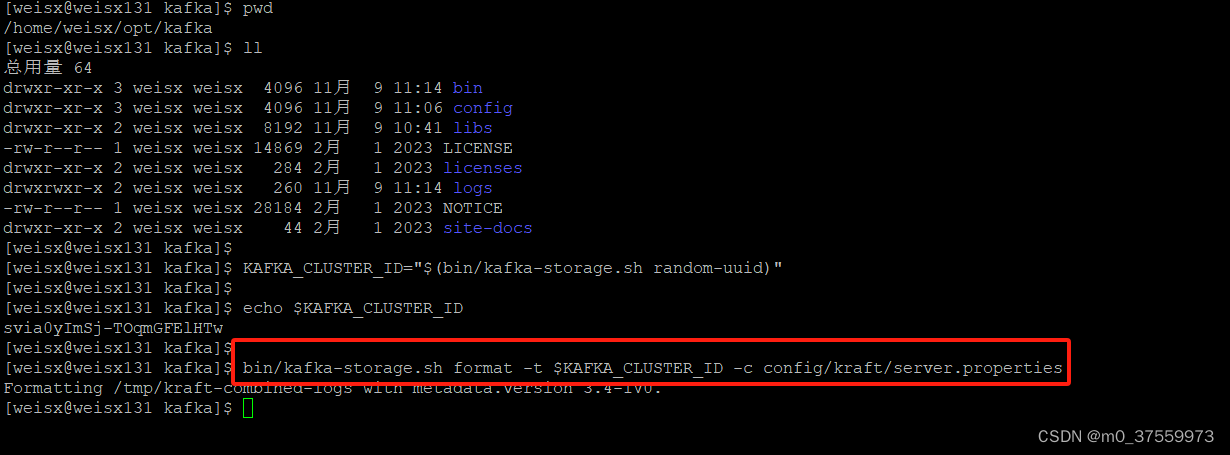
2.格式化存储目录,可以修改Kafka 运行日志(数据)存放的路径(config/kraft/server.properties),默认存放在/tmp下。
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
3. 启动Kafka服务
./bin/kafka-server-start.sh -daemon config/kraft/server.properties
3.Kafka常用命令
3.1 Kafka 服务命令
1.启动kakfa
参考2.3一节。
2.关闭kafka
./bin/kafka-server-stop.sh

3.2Topic 常用命令
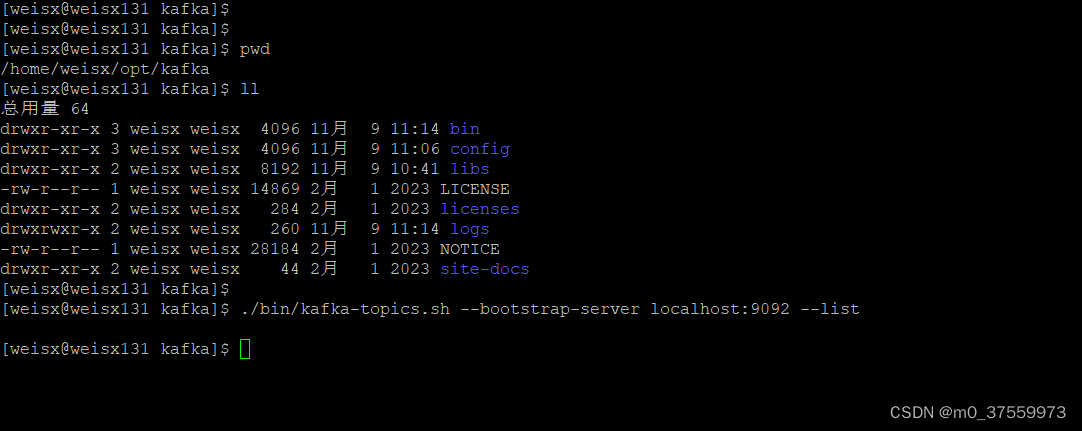
1.查看Topic列表
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
2.新建Topic
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test --partitions 1 --replication-factor 1
–partitions:分区数量,
–replication-factor:副本数量,不能大于broker数量

3.查看Topic信息
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic test

4.修改Topic信息
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic test --partitions 3

5.删除Topic
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic test

3.3 生产者常用命令
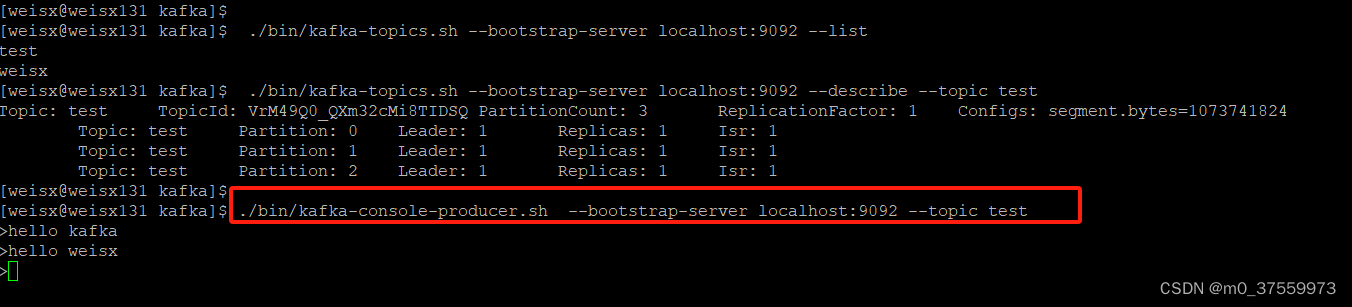
1.发送信息
./bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test
3.4 消费者常用命令
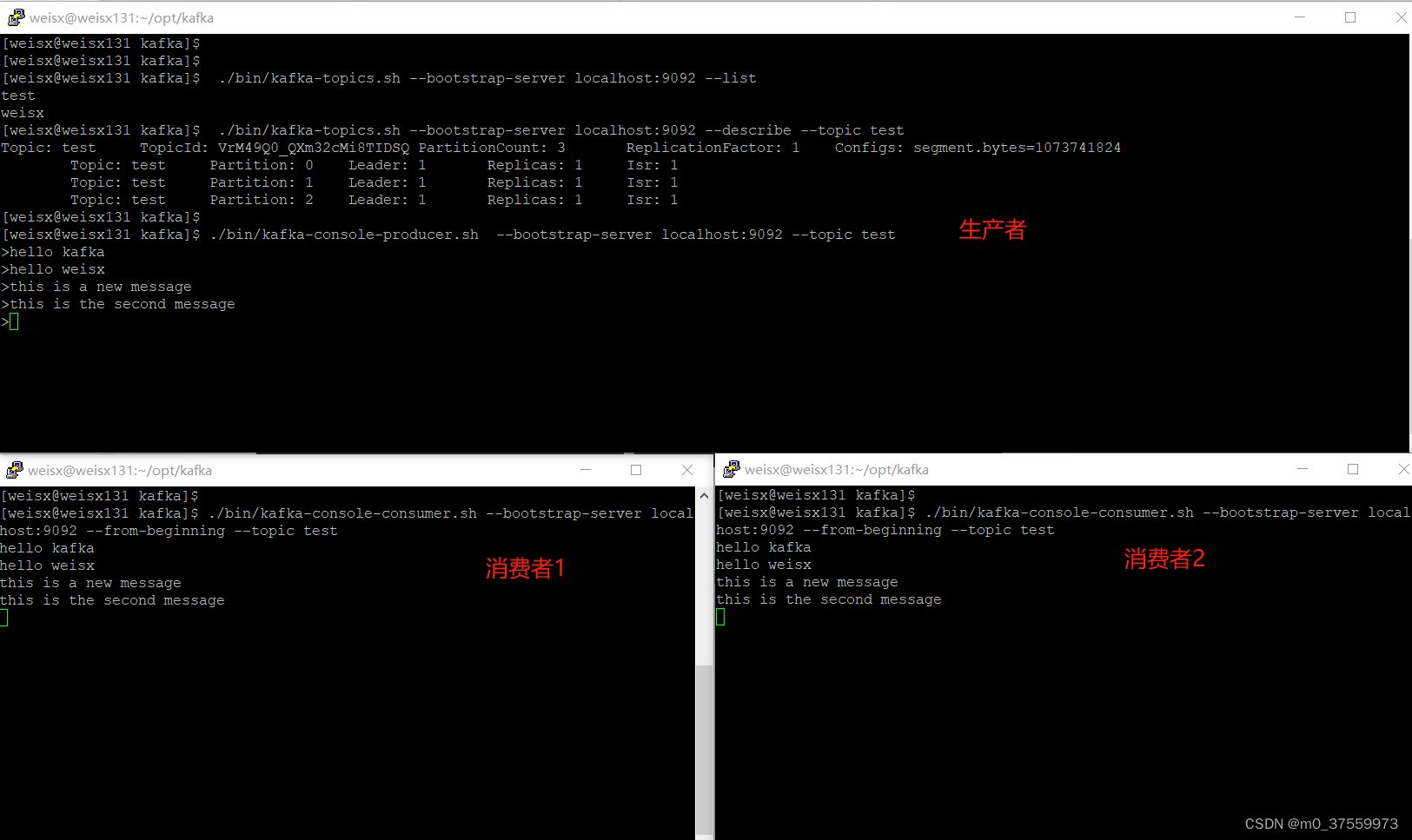
1.消费消息(从最新的地方开始)
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test [--offset latest]

2.消费消息(从头开始)
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test
3.消费消息(指定相同组)
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group group_1
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group group_1

4.消费消息(指定不同组)
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group group_1
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group group_2
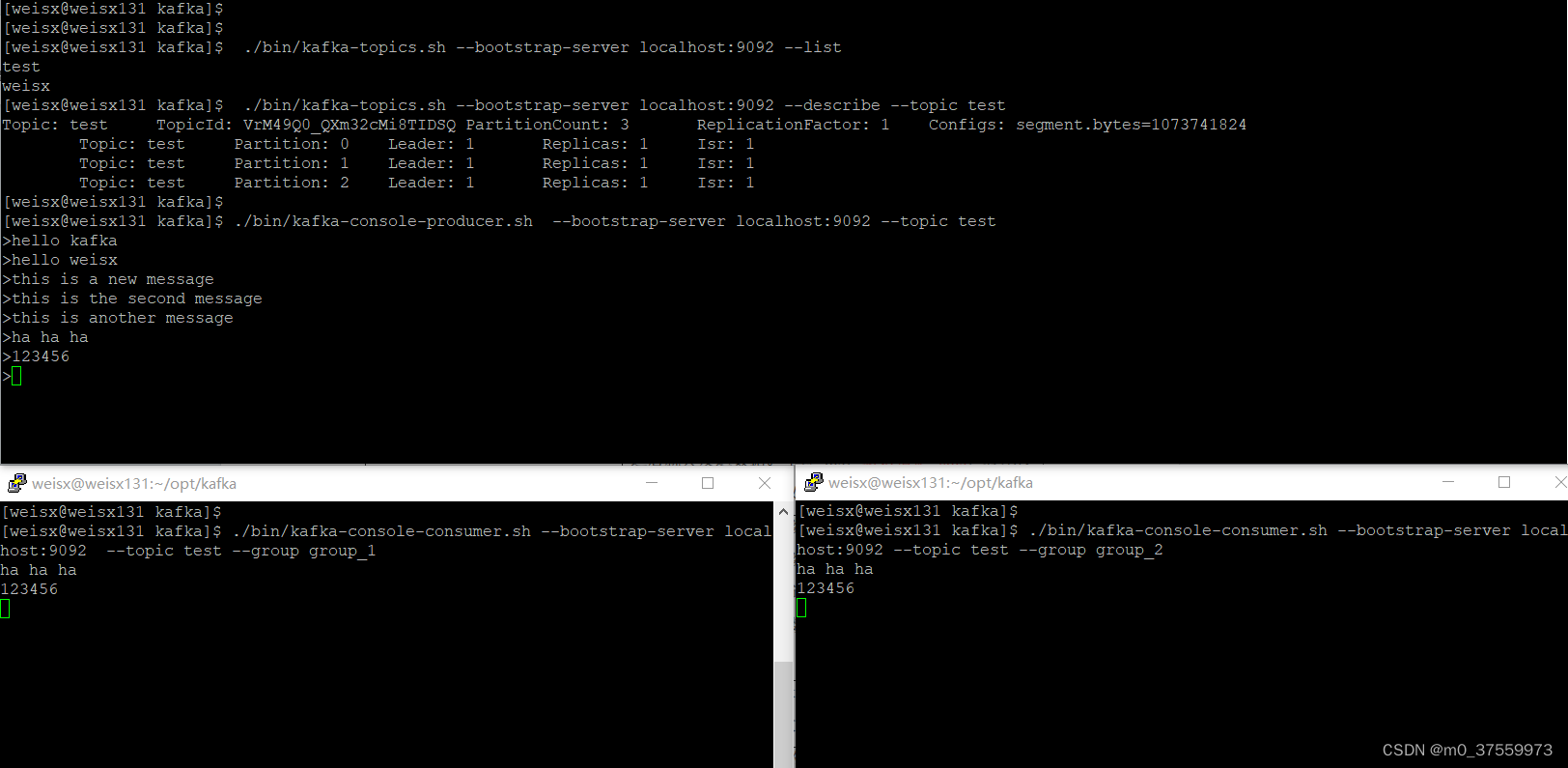
3.5消费者Group常用命令
1.指定消费者Group
参考3.4节,第3、第4点。
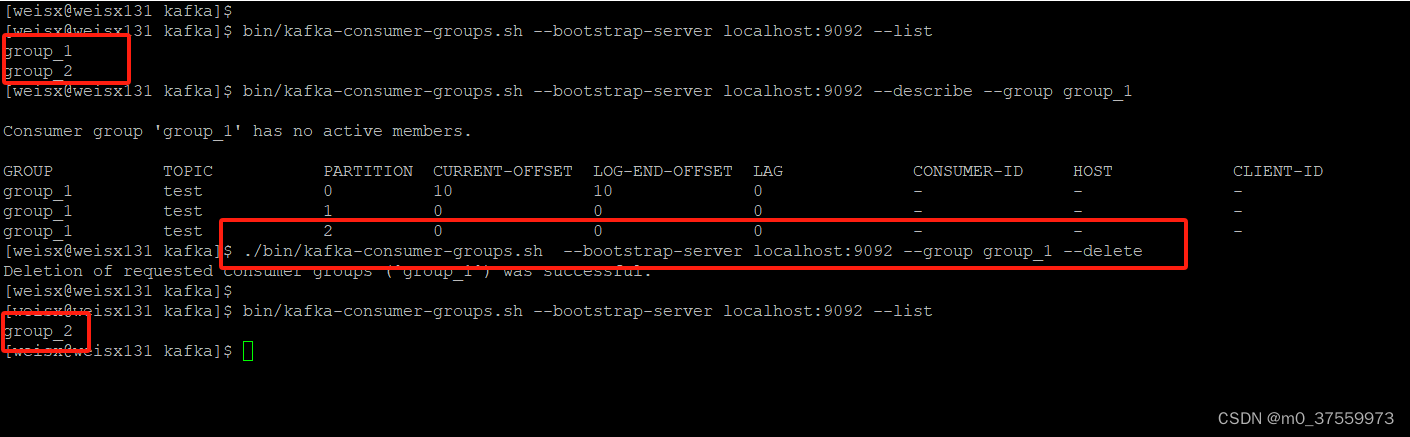
2.查看消费者Group列表
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list

3.查看消费者Group详情
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group group_1

4.删除消费者Group
./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group group_1 --delete
4.Kafka集群
4.1 Zookeeper模式集群
1.搭建zookeeper集群
在搭建kafka集群前,需要先搭建、启动好zookeeper集群,具体操作可以参考:搭建环境03:安装zookeeper-CSDN博客
2.下载、解压kafka
tar -zxf kafka_2.12-3.4.0.tgz -C ~/opt/
3.修改kafka配置
修改kafka 服务的配置文件(config/server.properties),修改broker.id和指定zookeeper集群地址:
#broker 的全局唯一编号,不能重复,只能是数字
broker.id=131#不同服务器绑定的端口
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
#broker 对外暴露的地址
advertised.listeners=PLAINTEXT://192.168.179.131:9092#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/home/weisx/opt/kafka_zookeeper/kafka-logs
#配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka_zookeeper,方便管理)
zookeeper.connect=192.168.179.131:2181,192.168.179.132:2181,192.168.179.133:2181/kafka_zookeeper
4.配置其他集群服务器
将上一步修改后的kafka同步到其他服务器上,然后修改broker.id和advertised.listeners。
scp -r kafka_zookeeper 192.168.179.132:~/opt/
scp -r kafka_zookeeper 192.168.179.133:~/opt/
修改192.168.179.132服务器上的broker.id=132,advertised.listeners=PLAINTEXT://192.168.179.132:9092
修改192.168.179.133服务器上的broker.id=133,advertised.listeners=PLAINTEXT://192.168.179.133:9092
5.启动kafka集群
依次在集群服务器上启动kafka
./bin/kafka-server-start.sh -daemon config/server.properties

新建topic,验证集群:

6.关闭kafka集群
依次在集群服务器上关闭kafka
./bin/kafka-server-stop.sh
4.2 KRaft 模式集群
KRaft模式不依赖外部框架(zookeeper),只需要数个(奇数)Kafka节点就可以直接构成集群,集群中的Kafka节点既可以是Controller节点也可以是Broker节点,还可以是混合节点(同时担任Broker和Controller角色)。
1.下载、解压kafka
tar -zxf kafka_2.12-3.4.0.tgz -C ~/opt/
2.修改kafka配置
修改kafka 服务的配置文件(config/kraft/server.properties),修改node.id和配置节点角色等信息:
#混合节点
process.roles=broker, controller#节点 ID,集群中每个节点id不能重复
node.id=131#controller 服务协议别名
controller.listener.names=CONTROLLER#broker 服务协议别名
inter.broker.listener.name=PLAINTEXT#Controller 列表,其配置格式为id1@host1:port1,id2@host2:port2,id3@host3:port3...
controller.quorum.voters=131@192.168.179.131:9093,132@192.168.179.132:9093,133@192.168.179.133:9093#不同服务器绑定的端口
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
#broker 对外暴露的地址
advertised.listeners=PLAINTEXT://192.168.179.131:9092#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/home/weisx/opt/kafka_kraft/kafka-logs
3.配置其他集群服务器
将上一步修改后的kafka同步到其他服务器上,然后修改node.id和advertised.listeners。
scp -r kafka_kraft 192.168.179.132:~/opt/
scp -r kafka_kraft 192.168.179.133:~/opt/
修改192.168.179.132服务器上的node.id=132,
advertised.listeners=PLAINTEXT://192.168.179.132:9092
修改192.168.179.133服务器上的node.id=133,
advertised.listeners=PLAINTEXT://192.168.179.133:9092
4.格式化存储目录
生成集群ID,使用该集群ID在各个服务器中格式化存储目录
#131服务器操作
bin/kafka-storage.sh random-uuid
bin/kafka-storage.sh format -t 3Ww7omfAQMm3bCb1HRI5_Q -c config/kraft/server.properties
#132服务器操作
bin/kafka-storage.sh format -t 3Ww7omfAQMm3bCb1HRI5_Q -c config/kraft/server.properties
#133服务器操作
bin/kafka-storage.sh format -t 3Ww7omfAQMm3bCb1HRI5_Q -c config/kraft/server.properties

5.启动kafka集群
依次在集群服务器上启动kafka
./bin/kafka-server-start.sh -daemon config/kraft/server.properties
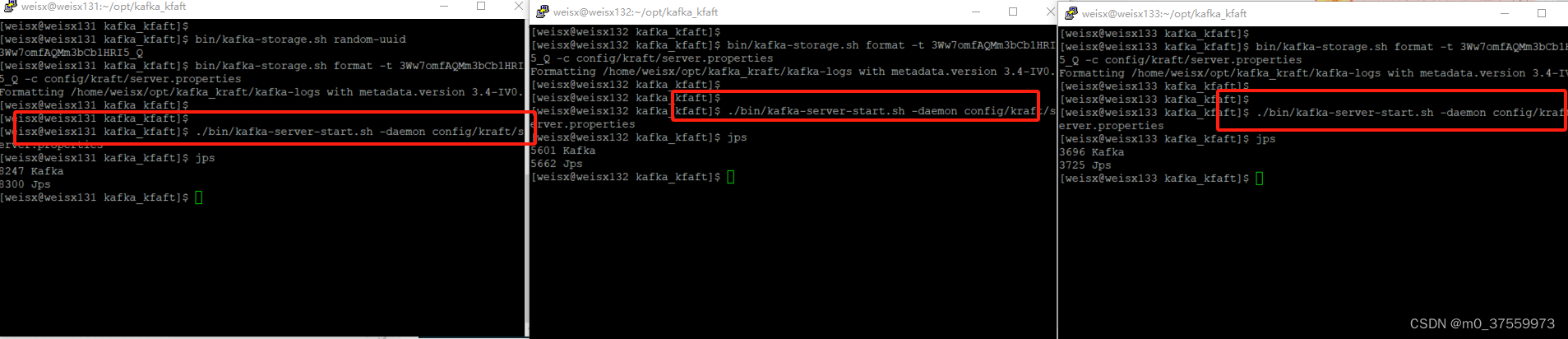
新建topic,验证集群:

5.关闭kafka集群
依次在集群服务器上关闭kafka
./bin/kafka-server-stop.sh















 19万+
19万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











