






一、前言
在上一博客中写了flink1.11.0读取kafka数据写入到hive中,发现hive中无法查询flink通过scala写入的数据,搜了些资料查找原因,参考了下文章:https://zhuanlan.zhihu.com/p/157899980 里无法读取hive数据的原因,但里面比较明确给出的解决方案是修改源码,我觉得太麻烦了。查了下官方和阅读些flink源码,终于找到一种我认为比较便捷的解决方案,具体分析方法如下:
完整的flink读取kafka数据动态写出hive,实现实时数仓的代码demo请参考上一篇文章:https://blog.csdn.net/m0_37592814/article/details/108044830
二、分析过程
1.StreamingFileCommitter 类中 commitPartitions 方法会调用PartitionTimeCommitTigger 类中的committablePartitions方法获取可提交的分区列表,然后变量分区提交分区。
2.主要是 PartitionTimeCommitTigger 类中的方法committablePartitions 用来获取需要提交分区的列表


里面需要 watermark > toMills(partTime) + commitDelay 成立 时才会把分区添加到需要提交分区列表中,这里是问题的关键,里面的 toMills(partTime) 方法转为毫秒时间时 会把 partTime 时间 往后8小时,所以会一直大于watermark 的值一直无法添加分区到需提交分区列表中


3.PartitionTimeExtractor 类 上图中的 extractor.extract()方法是实现了分区时间抽取接口 PartitionTimeExtractor 中的方法,查看flink官网:https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/connectors/filesystem.html 可以看出,可以自定义类实现 PartitionTimeExtractor 接口,重写里面的extract方法
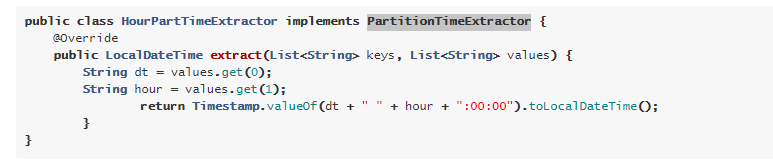
4. PartitionTimeExtractor 实例对象 extractor 是由 PartitionTimeCommitTigger 类的构造方法根据读取配置信息来创建的,
当 'partition.time-extractor.kind'='custom' 是 使用自定义的实现PartitionTimeExtractor接口的分区时间抽取类,否则使用的是默认的DefaultPartTimeExtractor


5. 解决方案:使用自定义的分区抽取时间实现类MyPartTimeExtractor,重写 extract方法,方法的返回值partTime 时间减少8小时,如步骤2中所说 toMills(partTime)方法会把partTime时间因为时区问题多加8小时,这样一减一加则抵消掉时区的影响了。
三、解决方案实现
1.添加自定义分区时间抽取类 MyPartTimeExtractor 。 代码主要是复制默认PartitionTimeExtractor 另一实现类DefaultPartTimeExtractor 的逻辑,修改如下一行代码,减去8小时。并且添加无参构造函数,不然无法实例化

实现类完整代码参考 上一篇文章:https://blog.csdn.net/m0_37592814/article/details/108044830
2.hive建表是添加 partition.time-extractor.kind 和 partition.time-extractor.class 属性
如下:

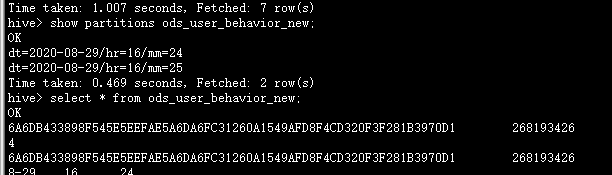
3.hive验证















 4244
4244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









