







构建RAG应用
一.将LLM 接入 LangChain
使用 LangChain 调用智谱 GLM
使用的是智谱 GLM API,需要将封装的代码zhipuai_llm.py下载到本 Notebook 的同级目录下,才可以运行下列代码来在 LangChain 中使用 GLM。
# 需要下载源码
from zhipuai_llm import ZhipuAILLM
from dotenv import find_dotenv, load_dotenv
import os
_ = load_dotenv(find_dotenv())
# 获取环境变量 API_KEY
api_key = os.environ["ZHIPUAI_API_KEY"] #填写控制台中获取的 APIKey 信息
zhipuai_model = ZhipuAILLM(model="chatglm_std", temperature=0, api_key=api_key)
zhipuai_model("你好,请你自我介绍一下!")
返回结果
' 你好,我是 智谱清言,是清华大学KEG实验室和智谱AI公司共同训练的语言模型。我的目标是通过回答用户提出的问题来帮助他们解决问题。由于我是一个计算机程序,所以我没有自我意识,也不能像人类一样感知世界。我只能通过分析我所学到的信息来回答问题。'
二.构建检索问答链
1.加载向量数据库
首先,我们加载在前一章已经构建的向量数据库。注意,此处你需要使用和构建时相同的 Emedding。
import sys
sys.path.append("../C3 搭建知识库") # 将父目录放入系统路径中
# 使用智谱 Embedding API,注意,需要将上一章实现的封装代码下载到本地
from zhipuai_embedding import ZhipuAIEmbeddings
from langchain.vectorstores.chroma import Chroma
from dotenv import load_dotenv, find_dotenv
import os
_ = load_dotenv(find_dotenv()) # read local .env file
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
# 向量数据库持久化路径
persist_directory = '../data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding
)
print(f"向量库中存储的数量:{vectordb._collection.count()}")
返回结果
向量库中存储的数量:40
question = "什么是prompt engineering?"
docs = vectordb.similarity_search(question,k=3)
print(f"检索到的内容数:{len(docs)}")
for i, doc in enumerate(docs):
print(f"检索到的第{i}个内容: \n {doc.page_content}", end="\n-----------------------------------------------------\n")
返回结果
检索到的内容数:3
检索到的第0个内容:
相反,我们应通过 Prompt 指引语言模型进行深入思考。可以要求其先列出对问题的各种看法,说明推理依据,然后再得出最终结论。在 Prompt 中添加逐步推理的要求,能让语言模型投入更多时间逻辑思维,输出结果也将更可靠准确。
综上所述,给予语言模型充足的推理时间,是 Prompt Engineering 中一个非常重要的设计原则。这将大大提高语言模型处理复杂问题的效果,也是构建高质量 Prompt 的关键之处。开发者应注意给模型留出思考空间,以发挥语言模型的最大潜力
(此处省略)
2.创建一个 LLM
# 需要下载源码
from zhipuai_llm import ZhipuAILLM
from dotenv import find_dotenv, load_dotenv
import os
_ = load_dotenv(find_dotenv())
# 获取环境变量 API_KEY
api_key = os.environ["ZHIPUAI_API_KEY"] #填写控制台中获取的 APIKey 信息
llm = ZhipuAILLM(model="chatglm_std", temperature=0, api_key=api_key)
llm.invoke("请你自我介绍一下自己!")
3.构建检索问答链
from langchain.prompts import PromptTemplate
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template)
基于模板
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
创建检索 QA 链的方法 RetrievalQA.from_chain_type() 有如下参数:
- llm:指定使用的 LLM
- 指定 chain type : RetrievalQA.from_chain_type(chain_type=“map_reduce”),也可以利用load_qa_chain()方法指定chain type。
- 自定义 prompt :通过在RetrievalQA.from_chain_type()方法中,指定chain_type_kwargs参数,而该参数:chain_type_kwargs = {“prompt”: PROMPT}
- 返回源文档:通过RetrievalQA.from_chain_type()方法中指定:return_source_documents=True参数;也可以使用RetrievalQAWithSourceChain()方法,返回源文档的引用(坐标或者叫主键、索引)
4.检索问答链效果测试
question_1 = "什么是南瓜书?"
question_2 = "王阳明是谁?"
基于召回结果和 query 结合起来构建的 prompt 效果
result = qa_chain({"query": question_1})
print("大模型+知识库后回答 question_1 的结果:")
print(result["result"])
返回结果
大模型+知识库后回答 question_1 的结果:
南瓜书是一个在线的书籍共享平台,用户可以在上面分享自己喜欢的书籍,也可以下载其他用户分享的书籍。该平台旨在让用户能够更方便地分享和获取书籍资源。谢谢你的提问!
result = qa_chain({"query": question_2})
print("大模型+知识库后回答 question_2 的结果:")
print(result["result"])
返回结果
大模型+知识库后回答 question_2 的结果:
王阳明是中国明代著名的哲学家、政治家和军事家。他是心学派别的创立者,提出了“知行合一”的哲学观点,对中国文化产生了深远的影响。
大模型自己回答的效果
prompt_template = """请回答下列问题:
{}""".format(question_1)
### 基于大模型的问答
llm.predict(prompt_template)
返回结果
' 南瓜书是一本针对人工智能领域中的数学难题的书籍,由开源组织Datawhale发起,团队成员谢文睿、秦州牵头。南瓜书针对一些难以理解的公式进行解析,对跳跃性较大的公式进行推导,帮助读者解决数学难题。该书的发布受到了广大学习者的好评,并且有幸得到西瓜书作者周志华教授的好评。南瓜书的项目地址在GitHub上,star数已经突破1.1万。'
prompt_template = """请回答下列问题:
{}""".format(question_2)
### 基于大模型的问答
llm.predict(prompt_template)
返回结果
' 王阳明,原名王守仁,是明代著名的思想家、哲学家、文学家和军事家。他出生于浙江余姚,曾在朝廷担任兵部尚书等要职,也是心学流派的创立者。王阳明提出了“心即理”的哲学观点,认为人的本性本善,只要克服私欲,就能达到道德的境界。他的思想影响深远,被誉为中国古代哲学的瑰宝之一。'
5.添加历史对话的记忆功能
5.1 记忆(Memory)
使用 ConversationBufferMemory ,它保存聊天消息历史记录的列表,这些历史记录将在回答问题时与问题一起传递给聊天机器人,从而将它们添加到上下文中。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history", # 与 prompt 的输入变量保持一致。
return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串
)
5.2 对话检索链(ConversationalRetrievalChain)
对话检索链(ConversationalRetrievalChain)在检索 QA 链的基础上,增加了处理对话历史的能力。
它的工作流程是:
- 将之前的对话与新问题合并生成一个完整的查询语句。
- 在向量数据库中搜索该查询的相关文档。
- 获取结果后,存储所有答案到对话记忆区。
- 用户可在 UI 中查看完整的对话流程。
from langchain.chains import ConversationalRetrievalChain
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
llm,
retriever=retriever,
memory=memory
)
question = "我可以学习到关于提示工程的知识吗?"
result = qa({"question": question})
print(result['answer'])
是的,你可以通过吴恩达老师的《Prompt Engineering for Developer》课程学习到关于提示工程的知识。该课程由吴恩达老师与 OpenAI 技术团队成员 Isa Fulford 老师合作授课,内容涵盖了软件开发提示词设计、文本总结、推理、转换、扩展以及构建聊天机器人等语言模型典型应用场景。通过学习该课程,你可以了解到如何提升大语言模型应用效果的各种技巧和最佳实践,从而激发你的想象力,开发出更出色的语言模型应用。
question = "为什么这门课需要教这方面的知识?"
result = qa({"question": question})
print(result['answer'])
吴恩达老师的《Prompt Engineering for Developer》课程需要教授关于提示工程的知识,因为提示工程是开发人员使用大语言模型(LLM)的关键技能。通过学习提示工程的最佳实践和技巧,开发人员可以更好地利用 LLM 的强大功能,并通过 API 接口快速构建软件应用程序。此外,提示工程对于提高语言模型应用的效果和构建出色的语言模型应用也至关重要。
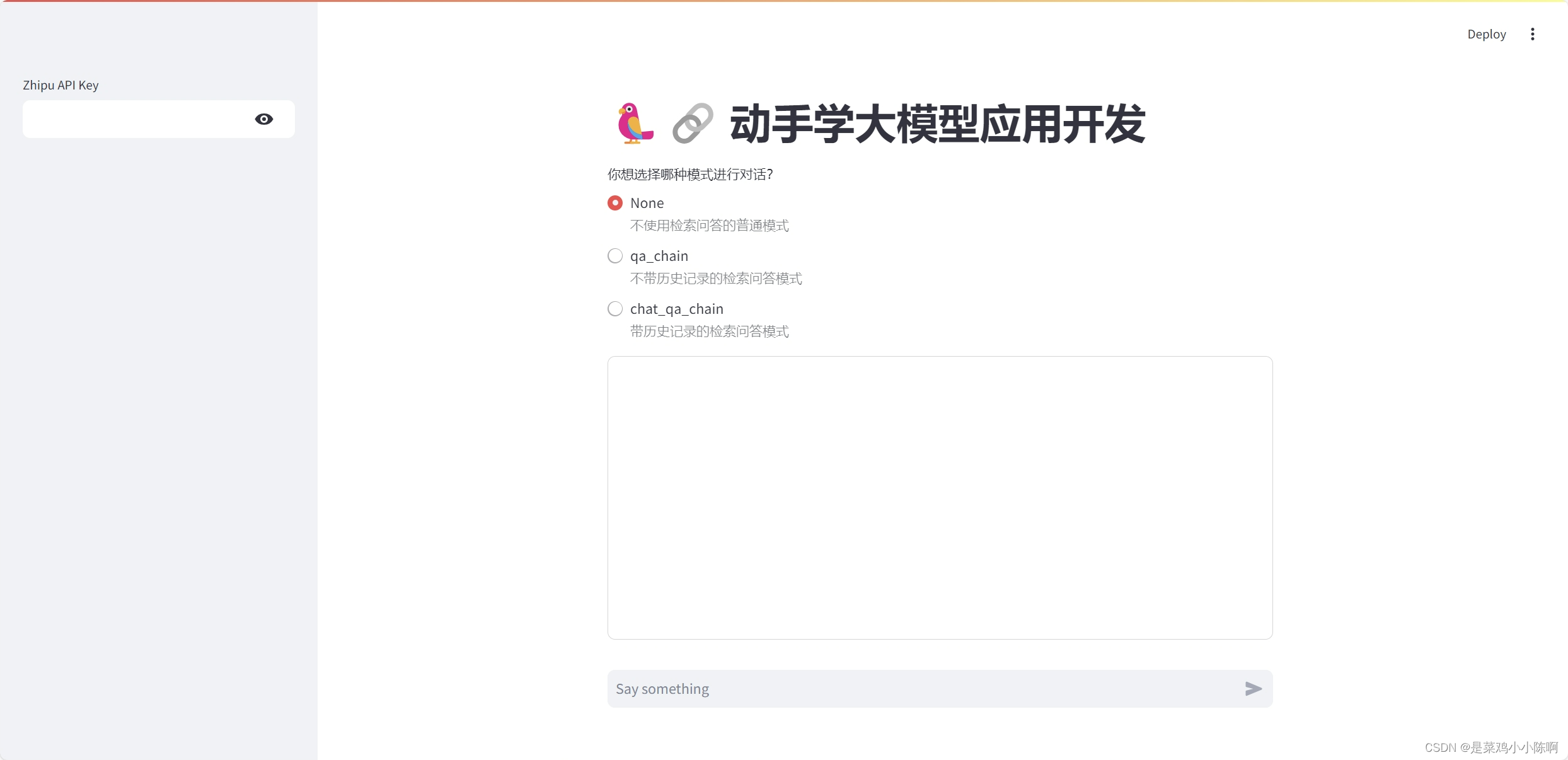
三. 部署知识库助手
1. Streamlit 简介
Streamlit 是一种快速便捷的方法,可以直接在 *Python 中通过友好的 Web 界面演示机器学习模型*。
Streamlit 提供了一组简单而强大的基础模块,用于构建数据应用程序:
-
st.write():这是最基本的模块之一,用于在应用程序中呈现文本、图像、表格等内容。
-
st.title()、st.header()、st.subheader():这些模块用于添加标题、子标题和分组标题,以组织应用程序的布局。
-
st.text()、st.markdown():用于添加文本内容,支持 Markdown 语法。
-
st.image():用于添加图像到应用程序中。
-
st.dataframe():用于呈现 Pandas 数据框。
-
st.table():用于呈现简单的数据表格。
-
st.pyplot()、st.altair_chart()、st.plotly_chart():用于呈现 Matplotlib、Altair 或 Plotly 绘制的图表。
-
st.selectbox()、st.multiselect()、st.slider()、st.text_input():用于添加交互式小部件,允许用户在应用程序中进行选择、输入或滑动操作。
-
st.button()、st.checkbox()、st.radio():用于添加按钮、复选框和单选按钮,以触发特定的操作。
2、构建应用程序
导入必要的 Python 库。
import streamlit as st
# from langchain_openai import ChatOpenAI
from zhipuai_llm import ZhipuAILLM
from dotenv import find_dotenv, load_dotenv
import os
# 读取本地/项目的环境变量。
# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
# 获取环境变量 API_KEY
api_key = os.environ["ZHIPUAI_API_KEY"] #填写控制台中获取的 APIKey 信息
# llm = ZhipuAILLM(model="chatglm_std", temperature=0, api_key=api_key)
创建应用程序的标题st.title
st.title('🦜🔗 动手学大模型应用开发')
添加一个文本输入框,供用户输入其 zhipu API 密钥
zhipu_api_key = st.sidebar.text_input('ZhiPu API Key', type='password')
**定义一个函数,使用用户密钥对 zhipu API 进行身份验证、发送提示并获取 AI 生成的响应。**该函数接受用户的提示作为参数,并使用st.info来在蓝色框中显示 AI 生成的响应
def generate_response(input_text):
llm = ZhipuAILLM(temperature=0.7, zhipu_api_key=zhipu_api_key)
st.info(llm(input_text))
**使用st.form()创建一个文本框(st.text_area())供用户输入。**当用户单击Submit时,generate-response()将使用用户的输入作为参数来调用该函数
with st.form('my_form'):
text = st.text_area('Enter text:', 'What are the three key pieces of advice for learning how to code?')
submitted = st.form_submit_button('Submit')
if not openai_api_key.startswith('sk-'):
st.warning('Please enter your Zhipu API key!', icon='⚠')
if submitted and openai_api_key.startswith('sk-'):
generate_response(text)
保存当前的文件streamlit_app.py
返回计算机的终端以运行该应用程序
streamlit run streamlit_app.py















 1255
1255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









