







swin transformer 论文阅读
摘要
提出一个新的transformer,swin transfomer,可做为视觉领域一个通用的骨干网络。
应用cv用挑战:
- 1.尺度问题,eg:街景场景,车、人有不同的尺寸
- 2.图像分辨率太大:特征图、图像patch、图片画成小窗口窗口内做自注意力机制
提出hierarchical Transformer,特征通过移动窗口Shifted windows方式获得
优点:
1.更大效率,序列长度降低
2.移动操作,相邻窗口可以交互。上下层之间cross-window connection,全局建模能力。
层级式结构好处:提供各尺度特征信息;自注意力在小窗口计算,计算复杂度随图像大小线性增长
swin transformer 拥有像CNN的分层结构、多尺度特征,可应用到其他下游任务。在物体检测、分割上获取了很好的成绩,在cv非常有潜力。
对于mlp架构用Shifted windows也可以提升
1 Introduction
一、二段类似VIT,说明CV领域CNN主导地位,借鉴nlp将transformer应用与CV。
**研究动机:**证明transformer用作一个通用的骨干网络
**目标检测:**FPN(a feature pyramid network,特征金字塔网络)
每个卷积层特征,感受野不同,获取物体不同尺寸特征
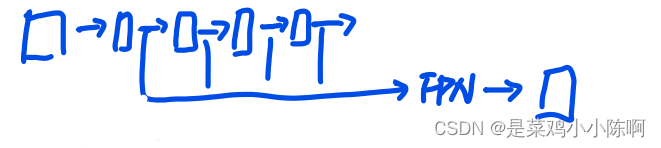
**目标分割:**skip connection
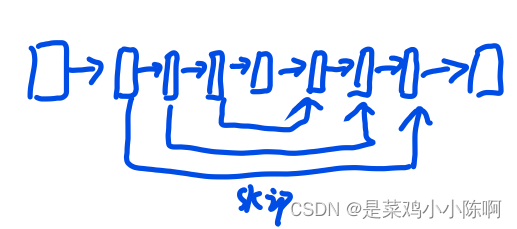
空洞卷积、psp、spp等
CV下游任务,尤其是密集预测型的检测、分割多尺度特征十分重要
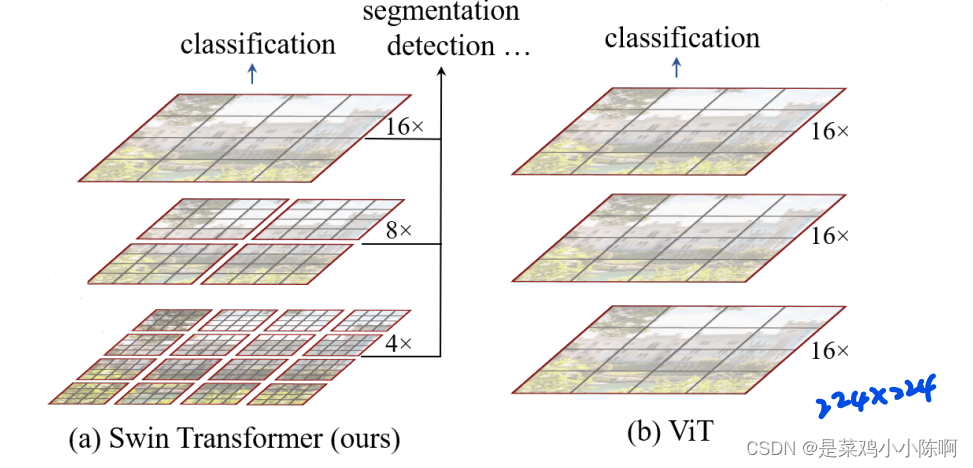
VIT:图片打成patch,16x 下采样率,每层的transfomer block看到的token尺寸一致。
全局自注意力操作达到全局建模能力,多尺寸特征能力较弱。
自注意力始终在最大窗口进行,全局建模,复杂度图像尺寸平方倍增长。
vit在图像尺寸224进行,检测、分割领域图像输入较大。
Swin :
1.减少序列长度、降低计算复杂度,采取小窗口计算自注意力。
窗口大小固定,计算复杂度就固定,计算复杂度与整图大小成线性关系。如果图像增大x倍,窗口个数增大x倍,时间复杂度乘以x。
利用CNN的inductive bias,局部性的先验知识。同一个物体的不同部分或者语义相似的不同物体大概率出现在相连的地方。即使在小窗口算自注意力也足够。
2.生成多尺寸特征。
CNN有pooling,可以增大每个卷积核看到的感受野,每次池化的特征抓住物体的不同尺寸。
swin transfomer提出patch merging,相邻patch合成大patch,一个大patch看到之前四个小patch看到的内容,感受野增大,抓住多尺寸特征。
3.移动窗口操作shifted window
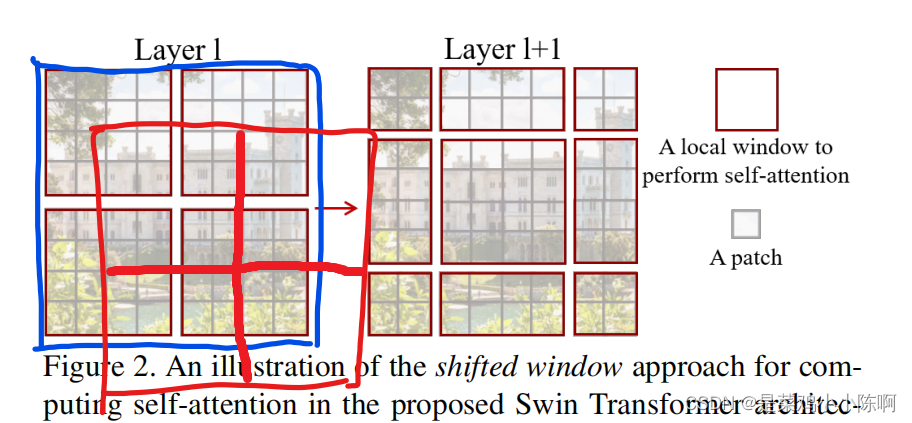
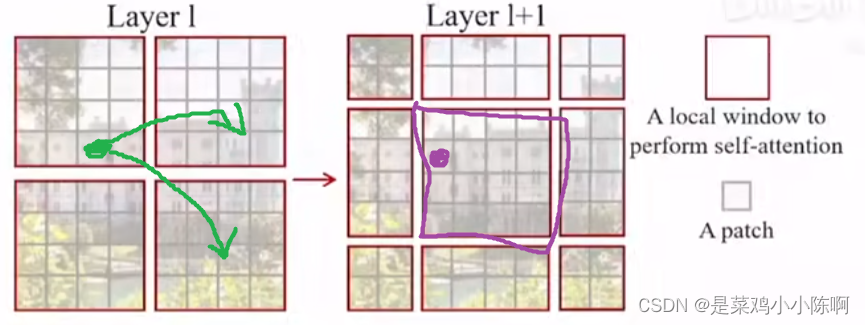
灰色框小patch,最基本的元素单元,4x4patch
红色框:中型的计算单元,窗口;论文默认一个窗口有49个小patch,图仅为示意。
蓝色表示整体特征图,shifted window即像右下移动俩个patch,红色框,再次分成4方格
如果没有shifted,窗口不重叠,窗口内部自注意力时,patch无法注意到其他窗口信息,无法更好的理解上下文,没有全局建模能力。如下图绿色点示意
shifted操作,窗口有重叠,patch就可以与新窗口的patch进行交互,新窗口的patch来自上一层别的窗口的patch。如下图紫色点示意。corss-window conntection
配合之后的patch merge ,合并到最后几层,每个patch感受野就可以看到大部分图片,再加上移动窗口,窗口内的局部注意力变相等于全局自注意操作。
结论
1.提出swin transformer,层级式transformer,复杂度跟输入图像大小成线性增长
2.最关键贡献shifted window。接下来工作将其应用到nlp
2 Related Work
跟vit非常相似。先介绍讲解CNN,自注意力、Transfomer应用CNN,纯的Transfomer作为骨干网络
3. Method
3.1 整体流程
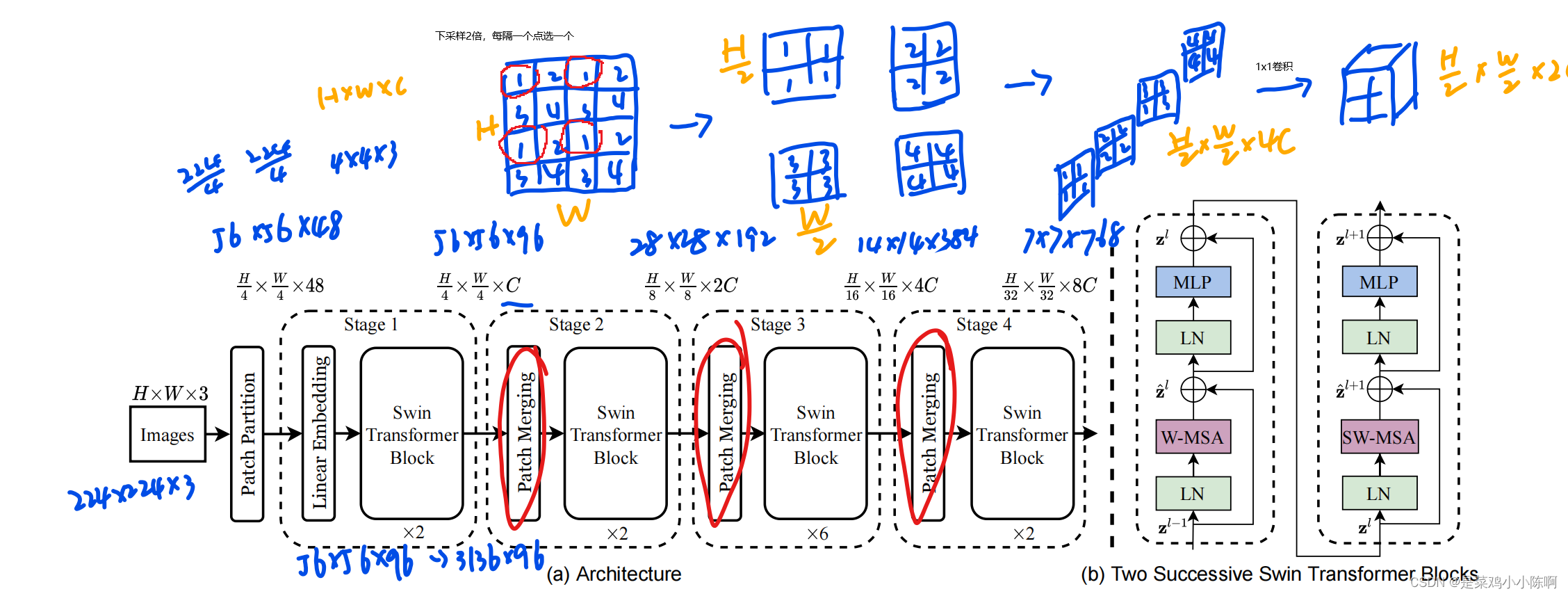
224x224x3 (patch size 4x4)
--> 56x56x48 (224/4, 48=4x4x3)
-->linear embeding,向量维度C=96, 56x56x96->3136x96
-->Swin transformer block 56x56x96
-->patch mergeing 如上图,空间大小减半,通道数X2,28x28x192
-->Swin transformer block
-->patch mergeing 14x14x384
-->Swin transformer block
-->patch mergeing 7x7x768
4个stage
分类头:gloabl avg pooling
3.2 移窗口自注意力
3.2.1 窗口自注意

橘黄色方格——窗口,内部还有mxm个patch,m=7;自注意力计算在小方格完成,序列长度49
(56/7) x (56/7) = 8x8 =64 个窗口;

h x w个patchs,C特征维度
M=7
标准多头自注意力复杂度
1.input乘上3个系数矩阵(cxc)变成q、k、v ,计算复杂度:3hwC2
2.q、k相乘得到自注意力矩阵A (hw x hw),计算复杂度:(hw)2C
3.A与value做乘法,加权。计算复杂度:(hw)2c
4.多头,projection layer,投射向量维度。hwc乘以CxC变成hwC,计算复杂度hwC2
即为公式1所示4hwC2 + 2(hw)2C
(hwC) q*k转置
(hwc) |---- q ---| A --|
input[] |---- k ---| |---proj
|---- v ---------|
基于窗口自注意力复杂度
每个窗口计算多头注意力,套用公式1,hxw变成MxM
一个窗口复杂度4M2C2 + 2M4C
窗口数目 (h/M) x (w/M)
整体 (h/M) x (w/M) x(4M2C2 + 2M4C)=4hwC2 + 2M2hwC
带入数据 差异大。
3.2.2移动窗口自注意力
窗口互相通信,具有上下文信息。
trandsformer block:先做基于windown的多头注意力再做基于shifted window的多头注意力
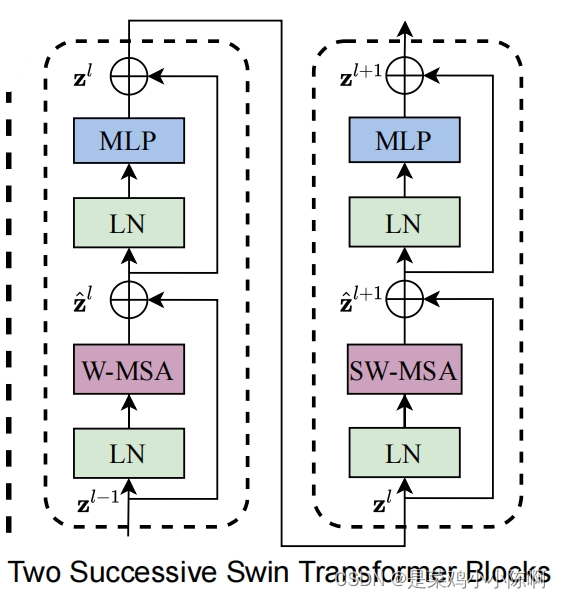
两个block组成一个swin transformer基本的计算单元。模型配置多少层block始终是偶数。
层级式transformer,提出patch merging的操作,从而像CNN一样把transformer分成几个阶段;为了减少计算复杂度,做CV密集预测任务,提出基于窗口和移动窗口的自注意力机制。
3.2.3 其他
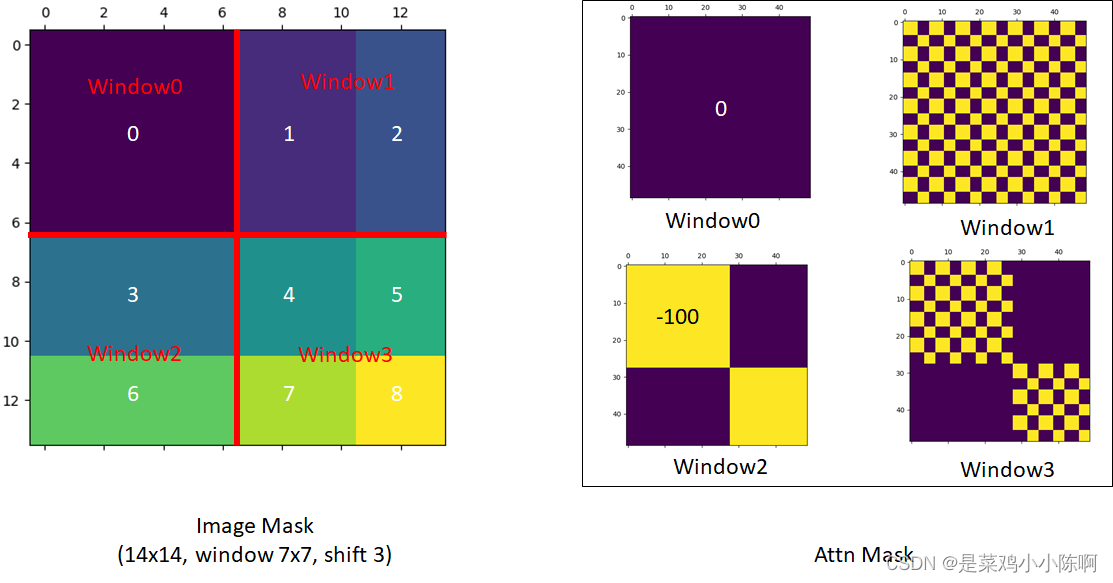
1.提高移动窗口的计算效率:masking掩码方式
2.没有使用绝对位置编码,使用相对位置编码
masking掩码方式
问题:移动窗口后,窗口数量增加,大小不一,快速运算无法做到。
**循环移位:**得到9个窗口后,做一次循环移位cyclic shift,得到4个窗口。计算复杂度固定
算完多头注意力后,需要将位移还原,保持图片相对位置不变,整体语义信息不变。如果不还原操作相当于在transformer中一直把图片往右下移动,语义信息可能被破坏。
—对于左上角窗口,元素互相紧挨可以做自注意力。
—剩下几个窗口,有些元素不相邻,不应该做自注意力。
因此需要进行掩码操作
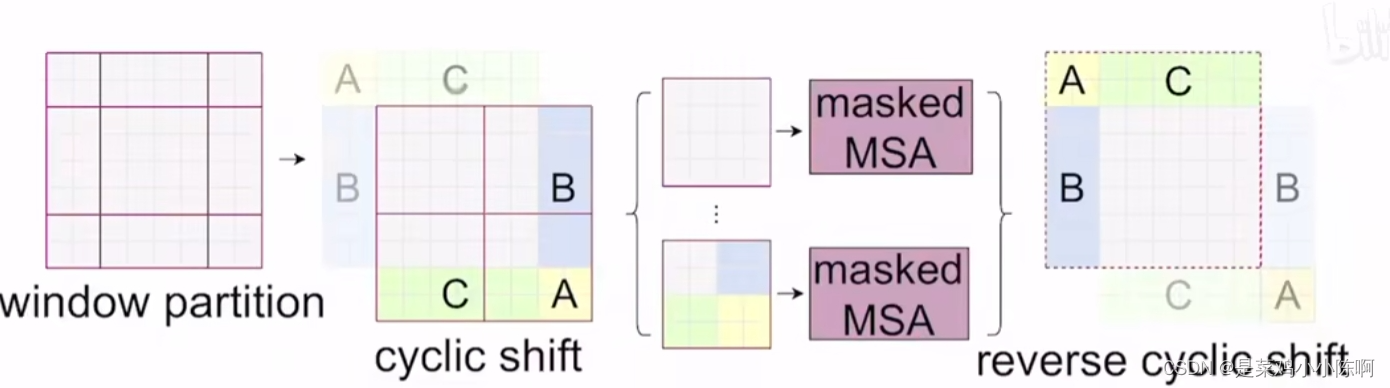
掩码方式:
窗口1:序号0,元素相邻,可以互相做自注意
窗口2:序号1、2不相邻,不可以做自注意力机制
窗口3:序号3、6不相邻,不可以做自注意力机制
窗口4:序号4、5、7、8不相邻,不可以做自注意力机制
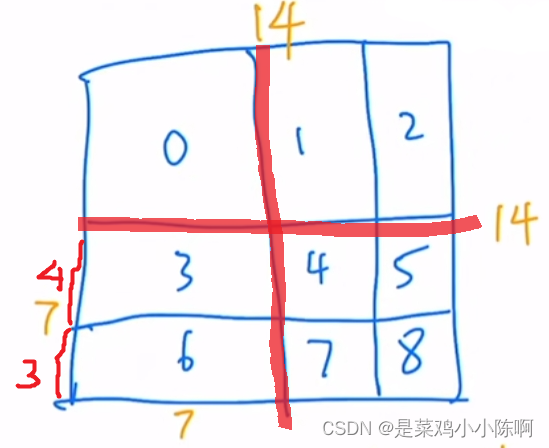
以窗口3为例
窗口内部有49patch。
窗口是7,移动位置一半,则序号3高度为4,6为3。
窗口做自注意力,如下图右侧。36和63区域的自注意力机制masked
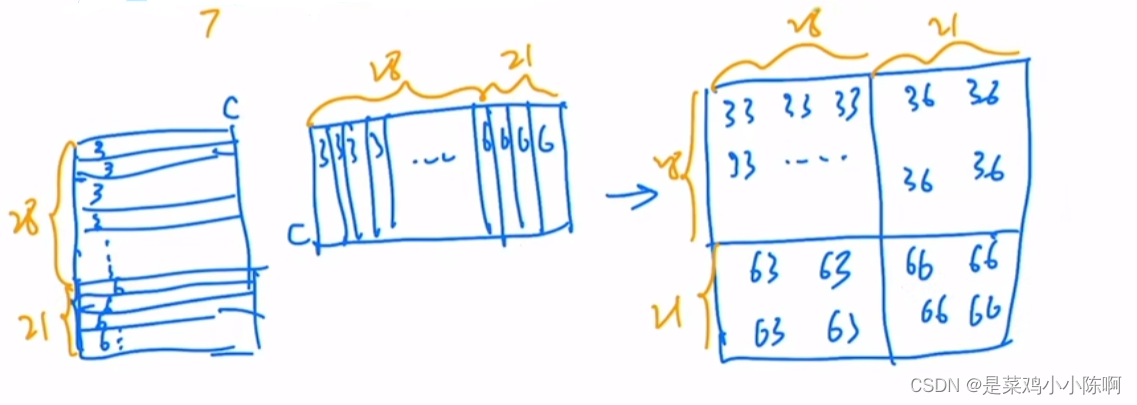
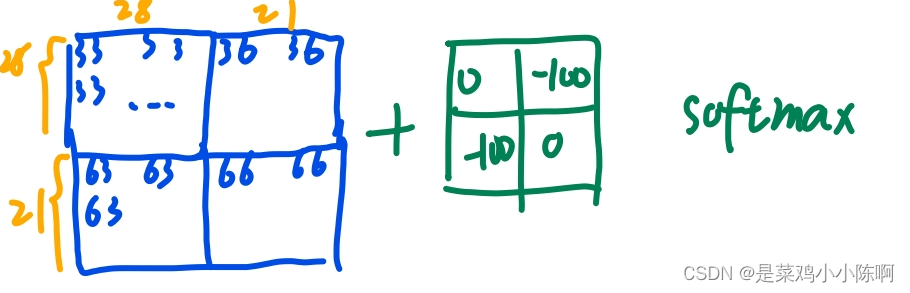
设计掩码模板,下图绿色矩阵。
自注意力矩阵和掩码矩阵相加,36、63两个区域的值非常小,再加上-100(负的很大数),变成非常负的小数,再通过softmax操作就变为0。则36、63区域masked掉
以窗口1为例

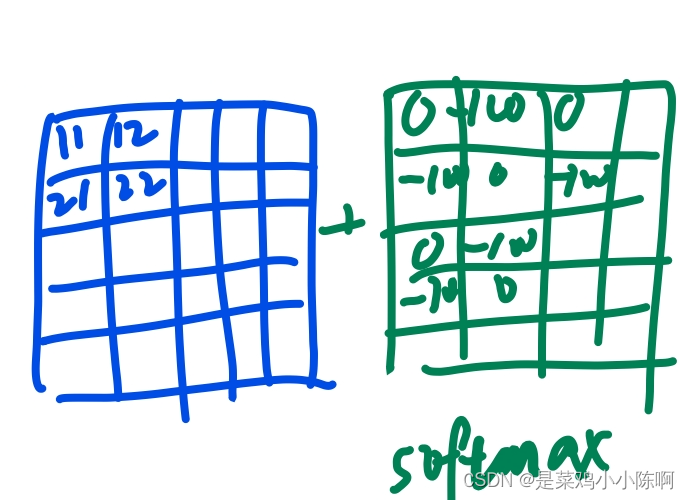
作者提供的窗口及掩码可视化
3.3 变体
• Swin-T: C = 96, layer numbers = {2, 2*,* 6*,* 2*}* ,复杂度ResNet-50差不多
• Swin-S: C = 96, layer numbers ={2, 2*,* 18*,* 2*}*, 复杂度ResNe-101差不多
• Swin-B: C = 128, layer numbers ={2, 2*,* 18*,* 2*}*
• Swin-L: C = 192, layer numbers ={2, 2*,* 18*,* 2*}*
差异:向量维度大小C,每个stage的有几个transformer block
4.Experiments
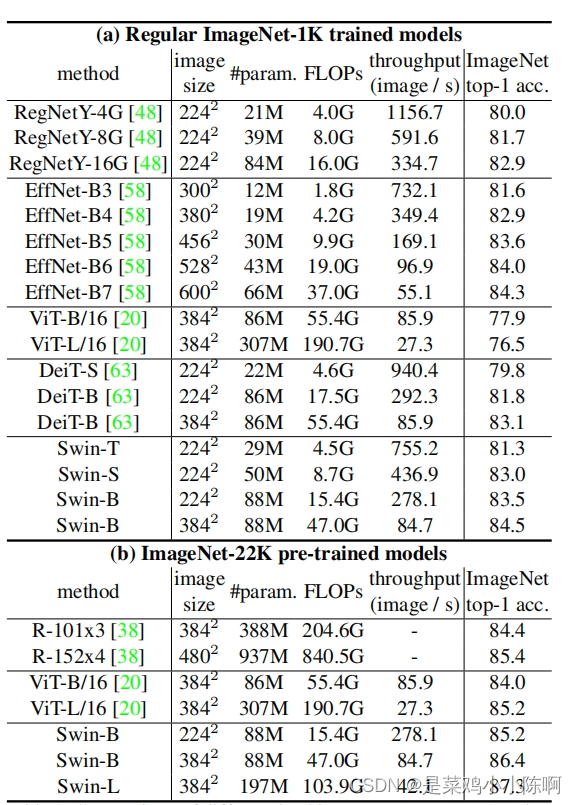
4.1. 分类实验ImageNet-1K
两种预训练方式
- ImageNet-1K数据集训练
- PImageNet-22K 数据集做预训练, ImageNet-1K微调
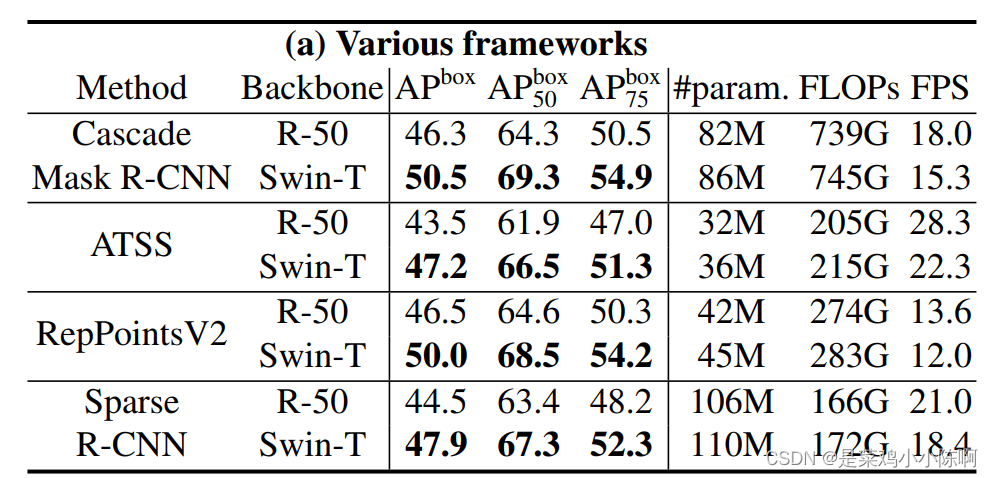
4.2. 目标检测 COCO
- 第一个测试方式:不同的算法框架下,对比不同网络。证明 Swin Transformer 是可以当做一个通用的骨干网络来使用的。对比了 Mask R-CNN、ATSS、RepPointsV2 和SparseR-CNN。骨干网络选用的由ResNet-50替换成了 Swin Tiny。Swin Tiny 的参数量和 FLOPs 与 ResNet-50 是比较一致的,二者对比相对公平。
可以看到,Swin Tiny 在四个算法上都超过了 ResNet-50 ,而且超过的幅度也是比较大的
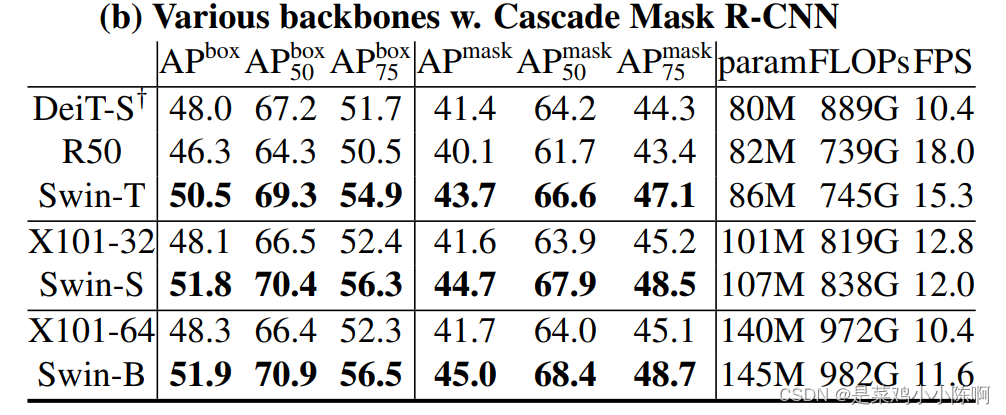
-
第二个测试方式:选定一个算法,更换的不同的骨干网络。选定Cascade Mask R-CNN 算法,使用 DeiT-S、ResNet-50 和 ResNet-101做为骨干网络
在相似的模型参数和相似的 Flops 之下,Swin Transformer 都是比之前的骨干网络要表现好的
-
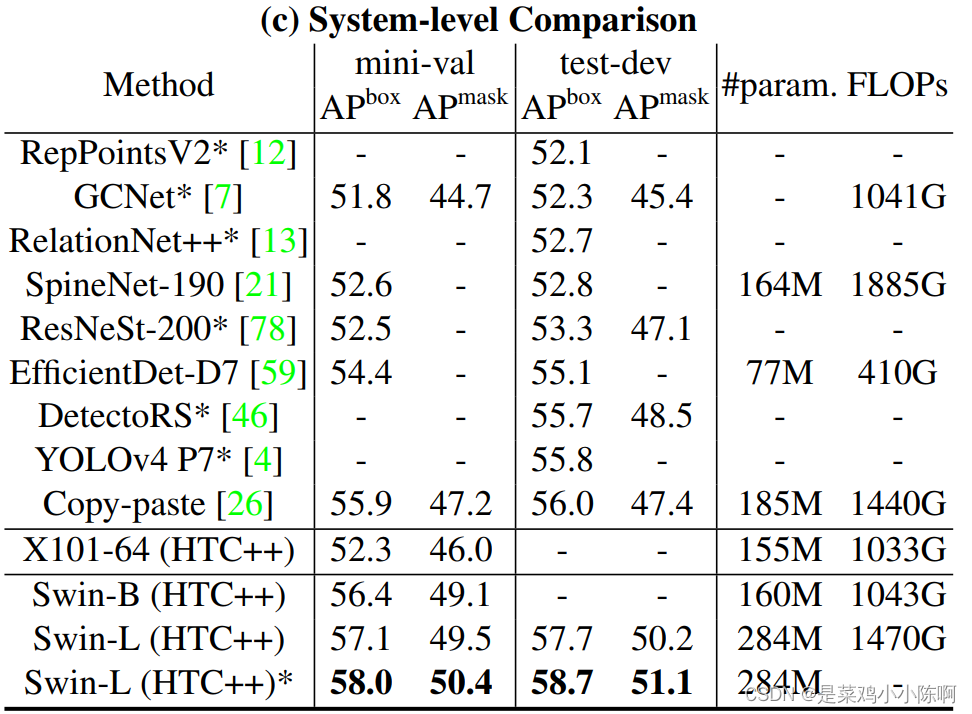
第三种测试的方式,就是系统层面的比。可以使用更多的数据,可以使用更多的数据增强,可以在测试的使用 test time augmentation(TTA)的方式
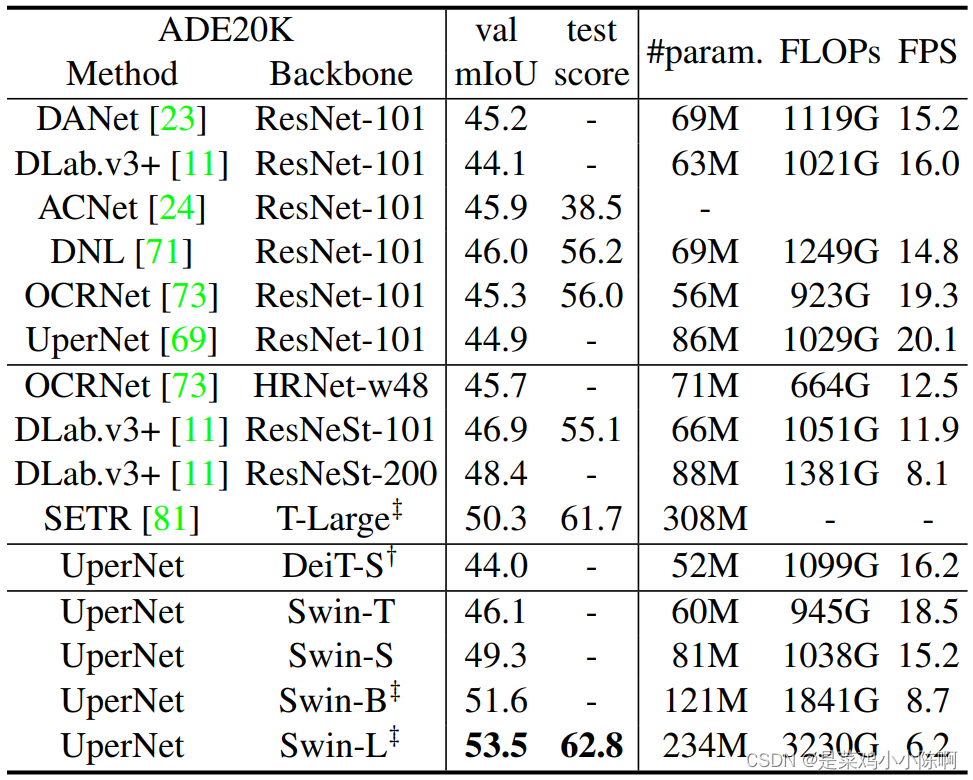
4.3语义分割ADE20K数据集
4.4 消融实验
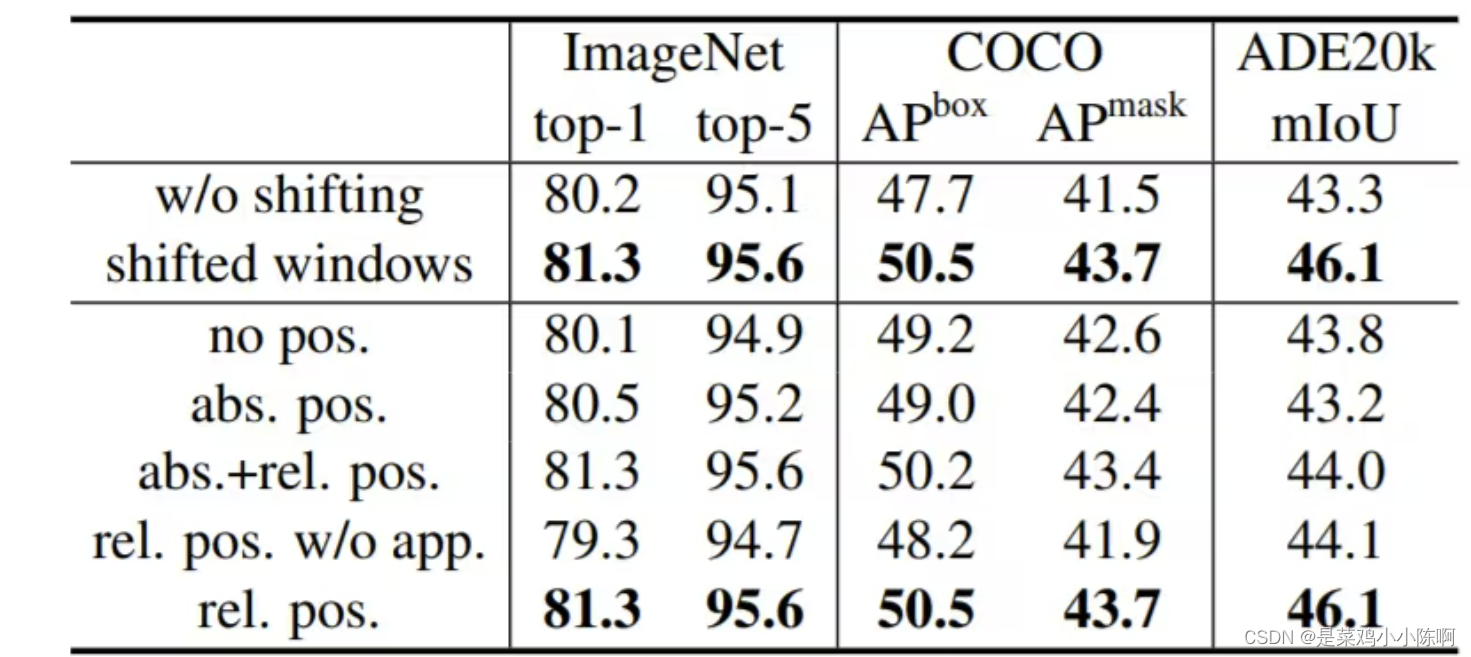
移动窗口以及相对位置编码到底对 Swin Transformer 有多有用
在分类任务的话,移动窗口和位置编码,提升相对于基线没有特别明显。在ImageNet数据集上提升一个点也算是很显著了
下游任务里,就目标检测和语义分割这两个任务上,使用了移动窗口和相对位置编码以后,都会比之前大概高了3个点左右,提升是非常显著的。如果现在去做这种密集型预测任务,需要特征对位置信息更敏感,更需要周围的上下文关系,通过移动窗口提供的窗口和窗口之间的互相通信,以及在每个 Transformer block都做更准确的相对位置编码,对这类型的下游任务有较大的提升。














 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









