







论文地址:https://arxiv.org/pdf/2010.11929.pdf
VIT论文阅读
摘要
虽然transformer已经是nlp领域的标准,但是transformer来做cv很有限,cv中跟attention跟cnn一起使用,或者cnn中的某些卷积替换成attention,整体结构不变。文章提出,直接使用transformer也可以在图像,尤其在大数据做训练再迁移到中小数据集。同时,transformer需要更少的训练资源。(2500天TPU V3)
INTRODUCTION
nlp领域的应用,transformer已经是必选模型。主流方式:在大规模数据集做预训练再去特定领域小数据集做微调(Bert)
transformer应用到cv难点:2d图片变成1d数据
self-attention应用到cv领域,
1.featuremap当做transformer输入,
2.孤立自注意力:通过局部小窗口,轴注意力:2d矩阵拆分为2个1d,先在高度维度做self-attention,再宽度维度做self-attention
2理论上高速,没有在硬件上加速,模型不够大。
直接应用transformer在图片领域,不做修改。把图片分成几个patches,每个patch通过fc layer得到一个linear embedding,将其输入给transformer。图片块类似nlp里面的tokens。训练使用有监督
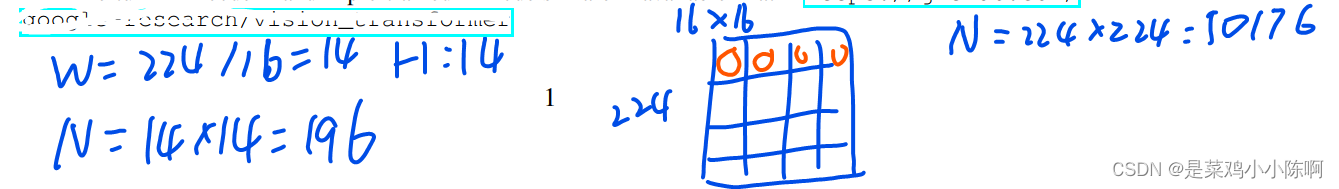
在中规模数据集,vit缺少归纳偏置(locality, translation equivariance:f(g(x))=g(f(x)),效果较弱。在大规模预训练,在下游任务去vit就可以取得相近或者更好的结果。
结论
抽图片块、位置编码之外没有引入归纳偏置。图像序列的图像块直接做transformer,简单、扩展性好的策略与大规模数据结合,达到了很好的效果。
未来方向:transformer在检测、分割的应用,自监督的预训练方式
模型变大达到更好的结果。
RELATEDWORK
transformer在nlp的应用:
BERT:denoising self-supervised(完形填空)
GPT:language modeling (next word pre)
在cv应用:
如果每个像素点当做一个元素,俩俩自注意力,平方复杂度难以应用
1.local neighborhoods
2.sparse transformer,稀疏点做自注意力
3.应用到不同大小block,或者按轴做自注意机制
需要用复杂工程加速算子
transformer和cnn结合:涵盖各领域
与之相似的工作:
1.Jean-Baptiste Cordonnier,Andreas Loukas,and Martin Jaggi. On the relationship between self-attention and convolutional layers. In ICLR, 2020.
2.iGPT:生成性模型,也使用transformer。微调后性能72%
3.其他相似工作:大数据集预训练;数据集ImageNet-21k、JFT-300M
METHOD
模型设计贴近transformer原理,好处:直接使用nlp的transformer架构
1.VISIONTRANSFORMER(VIT)
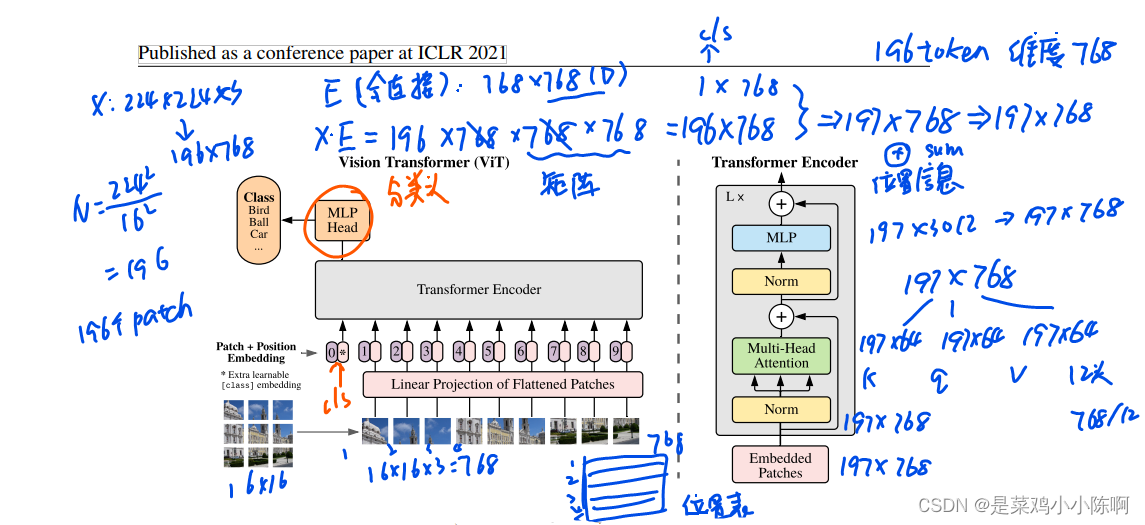
整体流程
1.图分成patch,变成序列
X: 224x224,使用patch size = 16, N= HW/P^2
得到196个图像块 ==> 16x16x3
2.每个patch经过linear projection线性投射层(全连接层E)得到特征,即patch embedding。加上位置编码信息position embedding。
3.借鉴bert extra learnable embedding,加入特殊字符cls ,图像*代替,class embedding。token输入transformer encoder
E: 768x768, D = 768,第一个768是图像计算得来16x16x8
X * E = 196 x 768 x 768 x 768 = img: 196 x 768 = 197 x 768, 矩阵乘法
cls: 1 x 768
加入位置编码信息,sum
4.多头自注意力机制,mlp head 分类头
12个头:768 / 12 = 64
197x64 197x64 197x64 12个头输出拼接:197 x 768
k q v
layer norm: 197 x 768
mlp: 放到4倍:197 x 3072 缩小投射———> 197 x 768
消融实验
HEAD TYPE AND CLASSTOKEN
class token 当做图像的整体特征,token输出接mlp,使用tanh为激活函数做预测。
(ResNet)图像全局向量特征:feature map ——> globally average-pooling

transformer
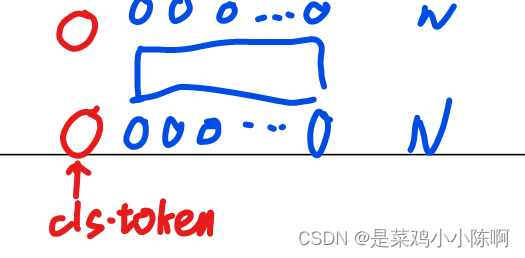
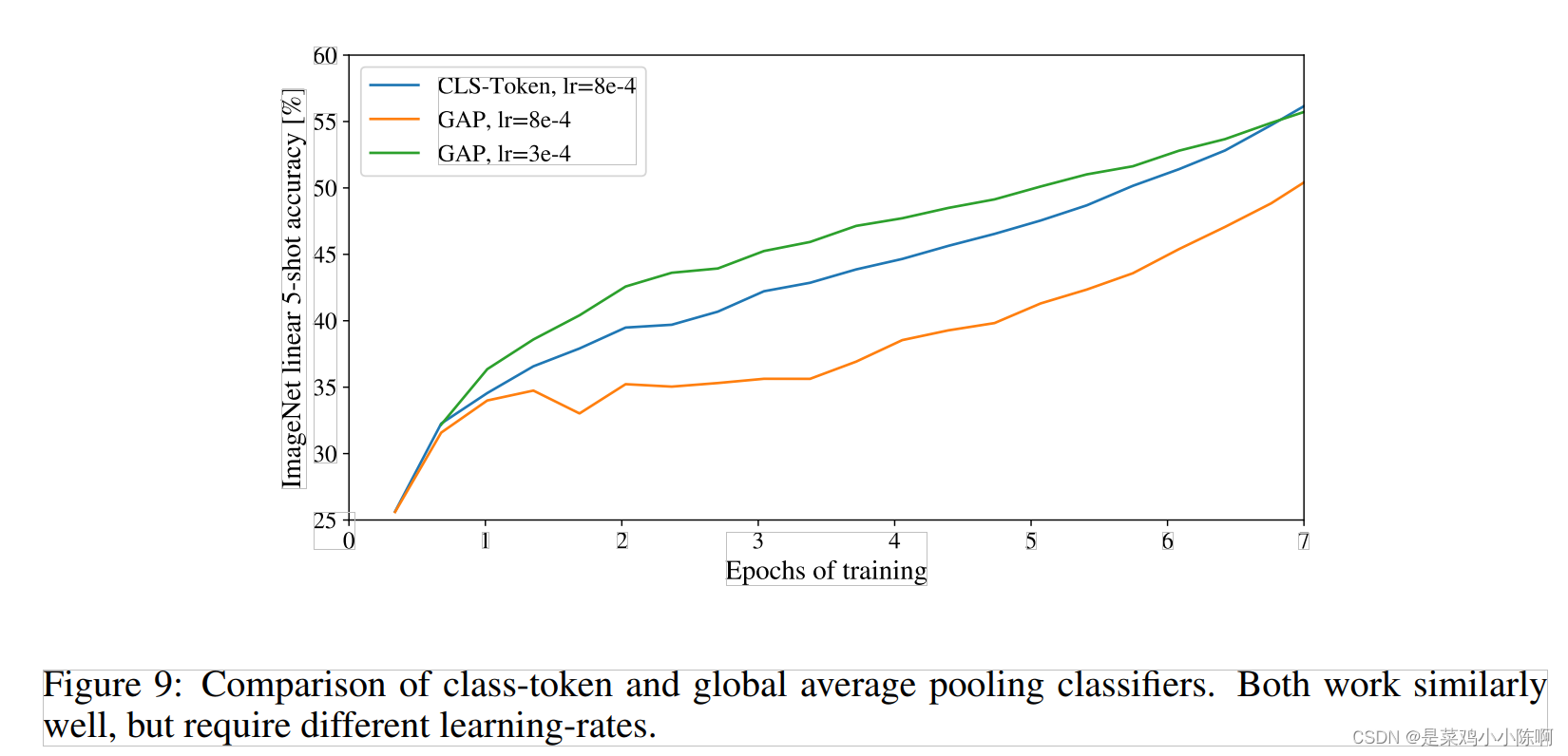
两种方式都可以,vit用class token,尽可能跟transformer保持一致
poisitional embedding
-
1D: nlp常用的
1 2 3 4 ... 9 维度 D -
2D:
D/2 D/2 11 12 13 21 22 23 31 32 33 维度D/2的向量表示X-embedding, D/2的向量表示Y-embedding contact成维度D --> 2d poisitional embedding -
Relative position embedding:绝对距离、相对距离
实验结果:都可以
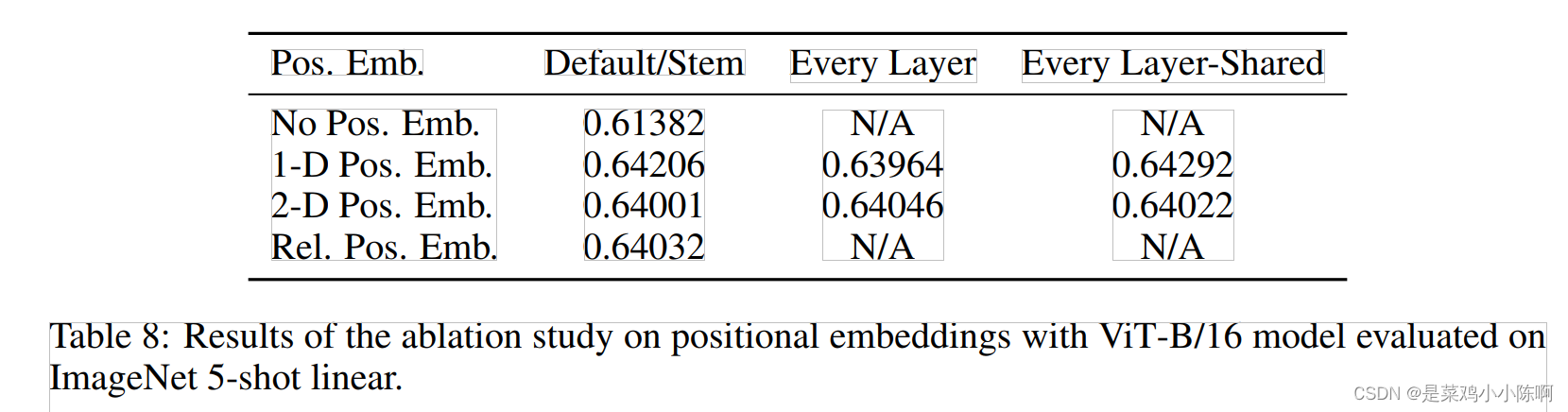
ptach-level而不是pixel-level,图像块较小,获取小块之间相对位置较容易,因此采用不同位置编码差异不大。
本文中vision transformer采用class token 跟1d position embedding(对标准的transformer不做过多改动)
整体过程公式

Inductive bias
cnn: locality、translation equivariance,模型每一层均体现,先验知识贯穿
vit:mlp layer是局部、平移等变性,self-attention全局,图片2d信息基本没有使用。位置编码也是随机初始化,没有携带任何2d信息。(缺少偏置,中小数据集效果不如cnn)
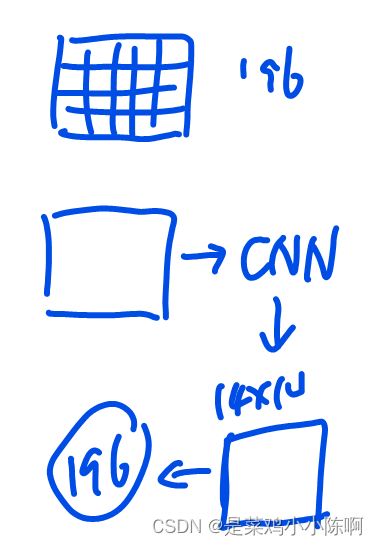
Hybrid Architecture
使用CNN进行预处理
图片通过CNN获取feature map,拉直后跟全连接层操作
2.FINE-TUNINGANDHIGHERRESOLUTION
微调用较大尺寸图像,得到更好结果。
使用预训练好的vision transformer,当用更大尺寸图像,patch size 保持一致,序列长度增加,提前预训练好的位置编码失效。
进行2d插值解决该问题(临时解决方案,微调局限性),2D interpolation
实验
对比resnet、vit和hybrid表征学习能力,不同大小数据集做预训练,在很多数据集做测试。vit在大多数数据集上训练时间短效果好
数据集:imagetNet、imagetNet-21k、JFT
下游任务分类:CIFAR-10/100、Oxford-IIIT Pets、,OxfordFlowers-102
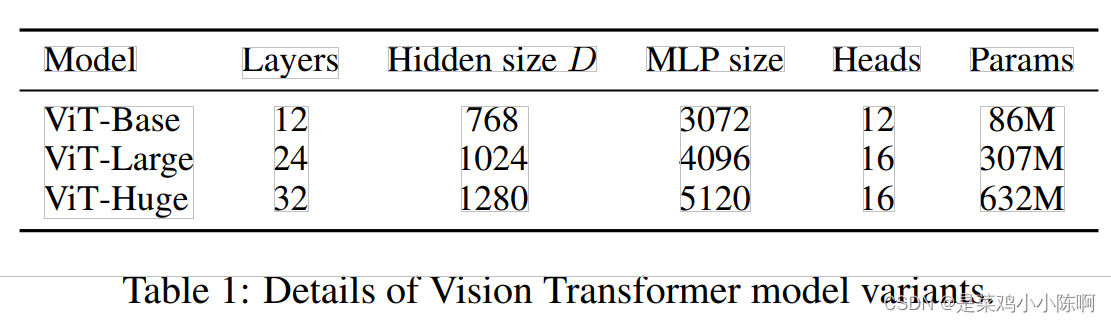
ViT-L/16:Large模型,patch size 16x16
序列长度跟patch size成反比,模型用更小的patch size时,计算代价更大
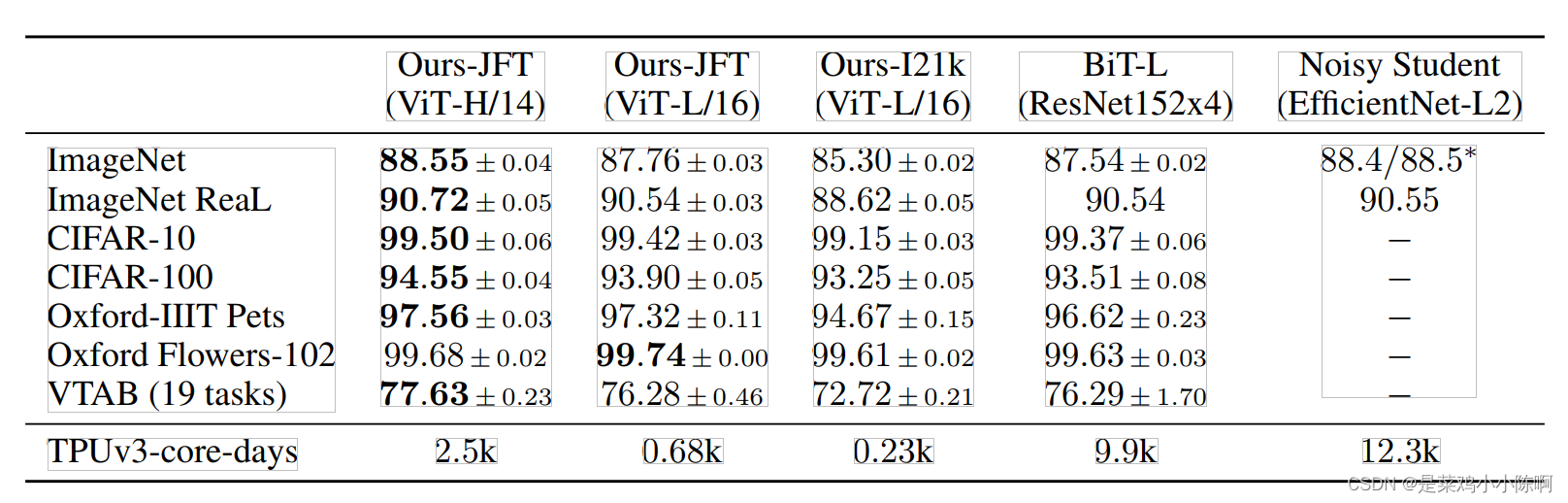
bit:cnn中较大的模型
noisy student:image net中表现最好 ,pseudo-label进行self training (伪标签)
vit训练时间更短
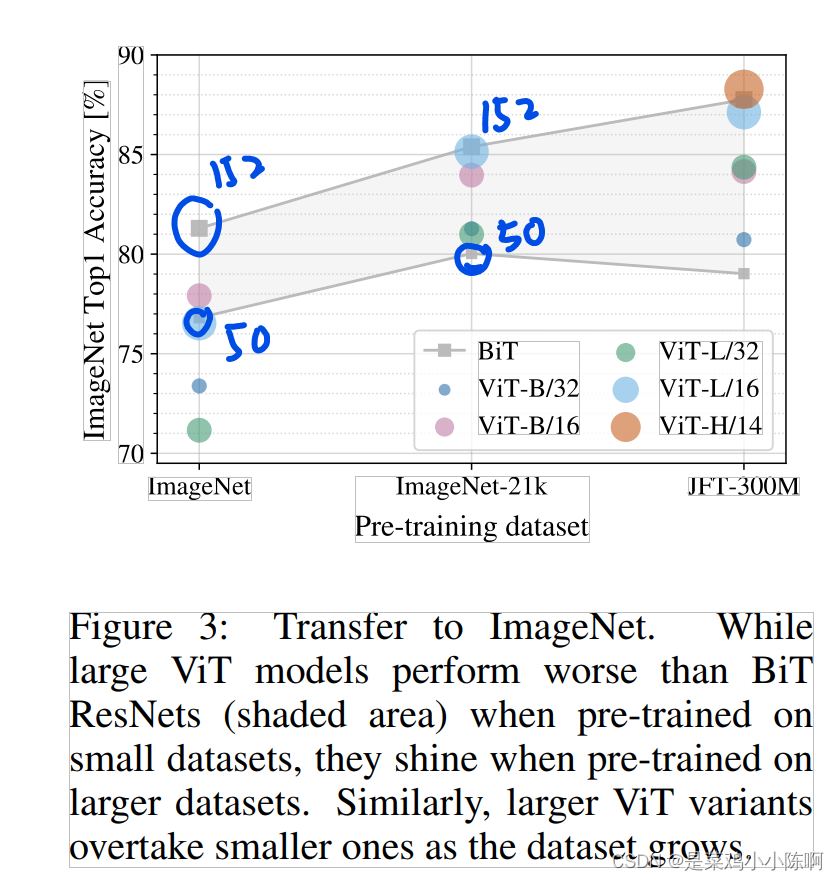
1.小数据集cnn效果好
2.数据规模大于ImageNet-21K,vit效果较好
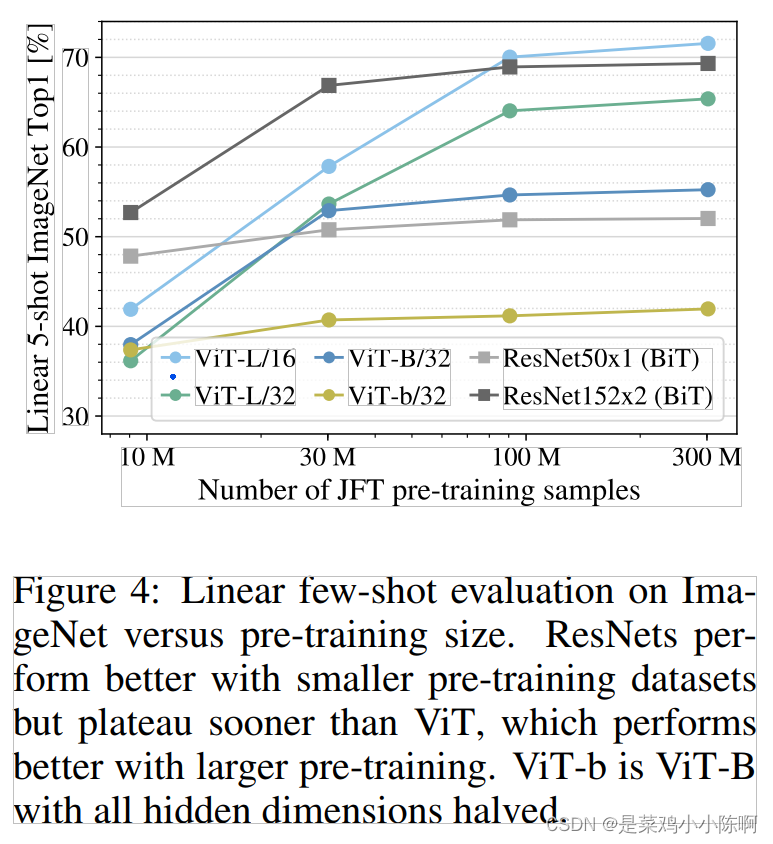
使用预训练模型当做特征提取器,做5-shot
原因:缺少归纳偏置,小数据集效果较cnn差;
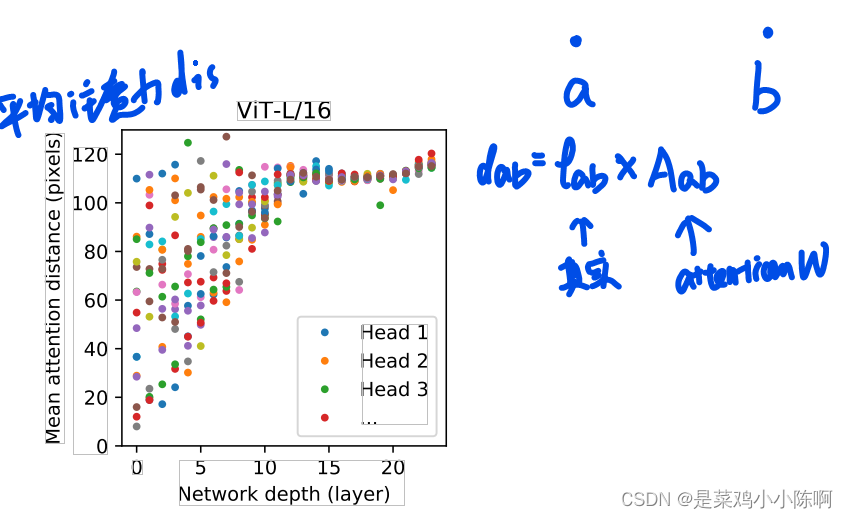
平均注意力距离
自监督:masked patch,将图片分成几个patch,随机涂抹几个patch;















 2347
2347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









