







目录
相关概念阐述
数据挖掘:data mining,如何从海量数据中挖掘出有用的信息来。
机器学习:machine learning,目标是归纳一个x->y的函数(映射),来做分类、聚类或者回归的工作。
数据挖掘的工作是通过机器学习提供的算法工具实现的,
深度学习:deep learning,本质上是神经网络算法的衍生,深度学习也是来源于机器学习的算法模型
人工智能:AI,人工智能是对人的意识、思维的信息过程的模拟,能以人类智能相似的方式做出反应的智能机器
作用:
机器学习:识别花朵,手写体数字识别,人脸识别(天眼系统),模糊人脸还原
深度学习:神经网络
人工智能:AIphaGo()
详解机器学习
什么是机器学习
机器学习是各种学科,各种计算从大量数据归纳出一种模型,一种算法,是人工智能的核心,机器学习的算法在数据挖掘里被大量使用。
机器学习的应用
CTR估计(广告点击率预测)比如通过逻辑回归来实现。
欺骗检测和异常模式的监测(孤立点)
电子邮件(垃圾邮件的过滤)可以通过贝叶斯来实现
电话呼叫欺骗行为,根据呼叫目的地,持续事件,日或周呼叫次数,分析该模型发现与期待标准的偏差
对欺骗行为进行聚类和建模,并进行孤立点分析
购物篮商品分析,典型案例:啤酒-尿布
机器学习算法概述
| 模型类别 | 说明 | 算法 |
|---|---|---|
| 回归模型
|
回归模型研究的问题 因变量(y)和一个或多个自变量(x)的函数关系,可以用于预测,是现代预测学的基础。此外也可以用于分类。以前属于统计学范畴,现在也归到机器学习的范畴 | 1.最小二乘法 3.逐步回归 4.多元自适应样条法 是利用样条函数的张量积作为基础函数,分为前向过程,剪枝等过程。在处理大量数据,高维数据时表现良好 5.本地权重评估估计法 引入数据窗口概念,一般应用在量化投资,金融分析等领域
|
| 正则化模型
|
正则化模型的思想是基于一个基础模型(比如最小二乘法)引入惩罚措施,目的是使模型具有更好的泛化能力 | 1.岭回归 3.弹性网 4.最小角回归 |
| 决策树模型
|
决策树建立的模型不是函数式,而是一个决策树,既可以解决分类问题,也可以解决预测问题 | 1.CART树 4.卡方自动交叉校验树 通过方差诱导思想来实现树的分裂,当方差或误差小于一定阈值时,停止树的分裂
|
| 集成模型
|
集成模型的特点将多个弱模型组合在一起。所以可以提高模型的精度和准确度。所以深受欢迎。 | 1.Boosting |
| 聚类模型
|
聚类算法的特点一般是基于距离度量来对数据做聚类分析,聚类的类别事先是不知道的。 | 1.K-Means |
| 基于实例模型(判别模型)
|
判别模型模型的特点基于样本数据建立判别函数,通过判别函数判别新样本的类归属问题 | 1.KNN(k-最近邻法) |
| 支持向量机模型
|
支持向量机主要解决分类问题,在数据升维过程中,可能带来维数灾难问题,而SVM引入核函数概念,可以解决高维计算问题,所以性能很好。此外还包含凸优化理论,拉格朗日乘子法等知识。可以应用于手写体识别,语音识别等领域。 | SVM 特征空间的映射 核函数 凸优化理论 拉格朗日乘子法 |
| 贝叶斯模型
|
这个模型的核心思想是基于贝叶斯公式(定理),是一个种概率模型,可以应用自动推理,文本分析里的垃圾信息过滤 | 1.朴素贝叶斯分类器 |
| 降维模型
|
模型的核心思想是做数据的降维,因为数据维数越高,计算代价越大。 | 1.主成分分析(PCA) |
| 关联规则模型
|
模型的核心思想是挖掘数据之间的关联关系,典型的案例 :啤酒-尿布 案例 |
|
| 图模型
|
核心思想通过图的形式来建模 | 1.贝叶斯网络 3.链图 |
| 人工神经网络模型
|
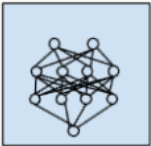
核心思想是模拟人的神经元来建模,含有接收数据+处理数据+传输函数模型 | 1.BP神经网络 |
| 深度学习
|
本质是神经网络的延伸,具有一定的模型深度 | 1.深玻尔兹曼机 |

总体分类,可以分两大来:监督学习算法和无监督学习算法
| 常见的监督学习算法 | 常见的无监督学习算法 |
|---|---|
| 1.线性回归 2.逻辑回归 3.朴素贝叶斯 4.KNN(最近邻算法) 5.决策树 6.支持向量机 7.某些可用于分类或预测功能的神经网络模型 | 1.系统聚类 2.K-means 3.K-中值聚类 3.K-众数法 4.某些神经网络模型,比如BP神经网络等 5.受限玻尔兹曼机
|
1.监督学习算法:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有导师训练。
监督学习中在给予计算机学习样本的同时,还告诉计算各个样本所属的类别
2.无监督学习算法:根据没有被标记的训练样本解决模式识别中的各种问题,称之为无监督学习。比如“鸡尾酒会问题(cocktail party problem)”就是一个无监督学习问题。无监督学习看做是聚类问题。
强化学习(RL)
也属于机器学习的范畴,灵感来自于行为主义心理学。
强化学习的思想是:引入奖励和惩罚机制,并告知模型如何采取行动,从而最大限度地获取奖励。
AI程序一开始是一块干净的白板,不知道自己应该要做什么。然后,通过奖励函数(导师或监督),使AI不断地训练,从而获取更高的奖励以及避免惩罚,最后得到理想的模型。
所以,只要给予足够的时间,机器学习算法将能够训练自己以成功完成给定的任务。尽管这可能需要花费很长时间,但最重要的还是要为你的程序提供高质量的训练数据,以获得更准确的结果。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









