







 本文提出了将知识蒸馏视为解决问题的流,通过不同层特征的内积计算,实现学生网络的快速优化和性能超越教师网络。这种方法不仅适用于迁移学习,还能显著提升学生网络的性能,且实验表明,通过FSP矩阵损失,可以提高学习效率并降低不同网络之间的相关性,从而提升集成模型的准确性。
本文提出了将知识蒸馏视为解决问题的流,通过不同层特征的内积计算,实现学生网络的快速优化和性能超越教师网络。这种方法不仅适用于迁移学习,还能显著提升学生网络的性能,且实验表明,通过FSP矩阵损失,可以提高学习效率并降低不同网络之间的相关性,从而提升集成模型的准确性。
目录
摘要
提出了将蒸馏的知识看作成一种解决问题的流,它是在不同层之间的feature通过内积计算得到的
这个方法有三个好处:
student网络可以学的更快
student网络可以超过teacher网路的性能
可以适用于迁移学习(teacher和student属于不同的任务)
引言
- 之前的工作
KD
Fitnets(hint)
- 本文的创新点
将知识看作如何解决问题的流,所以将要蒸馏知识看作解决问题的流
流被定义为在两个不同层上的features上的关系
Gram matrix是通过计算特征间的内积得到的,可以表示输入图像的纹理信息,本文也是通过计算Gram matrix来得到流,不同点在于原本的Gram matrix是计算一个层的特征间的内积,而本文是结算不同层特征间的内积
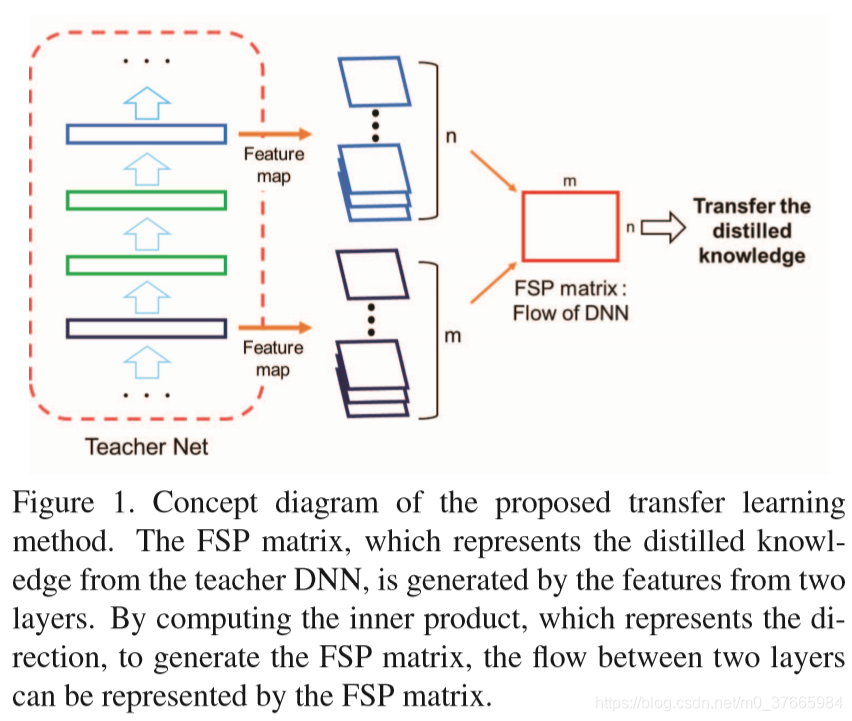
Figure1是计算FSP的概念图,FSP就是flow of solution procedure
- 本文的贡献
提出了一种好的知识蒸馏的方法
这种方法对快速优化有帮助
这种方法可以显著提升student网络的性能
这种方法适用于迁移学习
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2523
2523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









