







1 cut
cut的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出
1)基本用法
cut [选项参数] filename
2)选项参数说明
- -f:列号,提取第几列
- -d:分隔符,按照指定分隔符分割列
- -c:指定具体的字符
3)案例实操
数据准备
[mayx@hadoop206 ~]$ vim cut.txt
[mayx@hadoop206 ~]$ cat cut.txt
1 hello world
2 jiansheng libai
3 xingzhe wukong
4 fashi anqila
5 sheshou yuji
a 切割cut.txt 第二列
[mayx@hadoop206 ~]$ cut -d " " -f 2 cut.txt
hello
jiansheng
xingzhe
fashi
sheshou
b 切割cut.txt第一、第二列
[mayx@hadoop206 ~]$ cut -d " " -f 1,2 cut.txt
1 hello
2 jiansheng
3 xingzhe
4 fashi
5 shedshou
c 在cut.txt文件中切割出libai
[mayx@hadoop206 ~]$ cat cut.txt | grep "libai" |cut -d " " -f 3
libai
d 选取系统PATH变量值,第2个“:”开始后的路径和第2个开始后的所有路径
[mayx@hadoop206 ~]$ echo $PATH
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/opt/module/jdk1.8.0_144
:/opt/module/hadoop-2.7.2/bin:/opt/module/hadoop-2.7.2/sbin:/home/mayx/bin
[mayx@hadoop206 ~]$ echo $PATH | cut -d: -f 2
/bin
[mayx@hadoop206 ~]$ echo $PATH | cut -d: -f 2-
/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/opt/module/jdk1.8.0_144/bin:/opt/modul
doop-2.7.2/bin:/opt/module/hadoop-2.7.2/sbin:/home/mayx/bin
e 切割ifconfig后打印的IP地址
[mayx@hadoop206 ~]$ ifconfig | grep "inet addr" | cut -d: -f 2 | cut -d " " -f 1
192.168.206.206
127.0.0.1
2 sed
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出
1)基本用法
sed [选项参数] 'command' filename
2)选项参数说明
- -e:直接在指令列模式上进行sed的动作编辑,允许对输入数据应用多条sed命令编辑
- -i:直接 编辑文件
- -n:一般sed命令会把所有数据都输出到屏幕,如果加入-n选项的话,则会把经过sed命令处理的行输出到屏幕
3)命令功能描述
- a:追加,在当前行后添加一行或多行
- d:删除
- c:行替换,用c后面的字符串替换原来数据行
- i:插入,在当前行前插入一行或多行
- p:打印,输出指定的行
- s:字符串替换,用一个字符串替换另一个字符串。格式为’行范围s/旧字符串/新字符串/g’
4)案例实操一
数据准备
[mayx@hadoop206 ~]$ cat sed.txt
hello world
jiansheng libai
xingzhe wukong
fashi anqila
shedshou yuji
a 将“yewang hanxin”插入到sed.txt的第二行
[mayx@hadoop206 ~]$ sed '2a yewang hanxin' sed.txt
hello world
jiansheng libai
yewang hanxin
xingzhe wukong
fashi anqila
shedshou yuji
b 删除sed.txt文件包含“libai”的行
[mayx@hadoop206 ~]$ sed '/libai/d' sed.txt
hello world
xingzhe wukong
fashi anqila
shedshou yuji
c 将sed.txt文件中he替换成**
[mayx@hadoop206 ~]$ sed 's/he/**/g' sed.txt
**llo world
jians**ng libai
xingz** wukong
fashi anqila
s**dshou yuji
d 将sed.txt文件中的第二行删除并将he换成**
[mayx@hadoop206 ~]$ sed -e '2d' -e 's/he/**/g' sed.txt
**llo world
xingz** wukong
fashi anqila
s**dshou yuji
5)案例实操二
数据准备
[mayx@hadoop206 ~]$ cat sed.txt
hello world
hi neinv
welcome shagnhai
welcome beijng
go hangkang
go swimming
a 删除:d命令
sed '2d' sed.txt -- 删除 sed.txt 文件的第二行。
sed '2,$d' sed.txt -- 删除 sed.txt 文件的第二行到末尾所有行。
sed '$d' sed.txt -- 删除 sed.txt 文件的最后一行。
sed '/hello/d ' sed.txt -- 删除 sed.txt 文件所有包含 hello 的行。
sed '/[A-Za-z]/d ' sed.txt -- 删除 sed.txt 文件所有包含字母的行。
b 整行替换:c命令
sed '2c hello world' sed.txt -- 将第二行替换成 hello world
c 字符串替换:s命令
sed 's/hello/hi/g' sed.txt -- 在整行范围内把 hello 替换为 hi。如果没有 g 标记,则只有每行第一个匹配的 hello 被替换成 hi
sed 's/hello/hi/2' sed.txt -- 此种写法表示只替换每行的第 2 个hello为hi
sed 's/hello/hi/2g' sed.txt -- 此种写法表示只替换每行的第 2 个以后的 hello 为 hi(包括第 2 个)
sed -n 's/^hello/hi/p' sed.txt -- (-n) 选项和 p 标志一起使用表示只打印那些发生替换的行。也就是说,如果某一行开头的 hello 被替换成 hi,就打印它
sed -n '2,4p' sed.txt -- 打印输出 sed.txt 中的第 2 行和第 4 行
sed -n 's/hello/&-hi/gp' sed.txt -- &符号表示追加一个串到找到的串后
sed -n '5,/^hello/p' sed.txt -- 打印从第五行开始到第一个包含以 hello 开始的行之间的所有行
3 awk
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理
1)基本用法
awk [选项参数] ‘pattern1{action1} pattern2{action2}...’ filename
pattern:表示AWK在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令
2)选项参数说明
- -F:指定输入文件拆分分隔符
- -v:赋值一个用户定义变量
3)awk的内置变量
- FILENAME:文件名
- NR:已读的记录数
- NF:浏览记录的域的个数(切割后,列的个数)
4)案例实操
a 搜索passwd文件以root关键字开头的所有行,并输出该行的第7列
[mayx@hadoop206 ~]$ awk -F: '/^root/{print $7}' /etc/passwd
/bin/bash
b 搜索passwd文件以root关键字开头的所有行,并输出该行的第1列和第7列,中间以“,”号分割
[mayx@hadoop206 ~]$ awk -F: '/^root/{print $1","$7}' /etc/passwd
root,/bin/bash
c 只显示/etc/passwd的第一列和第七列,以逗号分割,且在所有行前面添加列名user,shell在最后一行添加"end,/end"
awk -F: 'BEGIN{print "user,shell"} {print $1","$7} END{print "end,/end"}' /etc/passwd
user,shell
root,/bin/bash
bin,/sbin/nologin
daemon,/sbin/nologin
adm,/sbin/nologin
mayx,/bin/bash
end,/end
d 将passwd文件中的用户id增加数值1并输出
[mayx@hadoop206 ~]$ awk -v i=1 -F: '{print $3+i}' /etc/passwd
1
2
3
e 统计passwd文件名,每行的行号,每行的列数
awk -F: '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF}' /etc/passwd
filename:/etc/passwd,linenumber:1,columns:7
filename:/etc/passwd,linenumber:2,columns:7
filename:/etc/passwd,linenumber:3,columns:7
filename:/etc/passwd,linenumber:4,columns:7
filename:/etc/passwd,linenumber:5,columns:7
filename:/etc/passwd,linenumber:6,columns:7
f 切割IP
[mayx@hadoop206 ~]$ ifconfig eth0 | grep "inet addr" | awk -F: '{print $2}' | awk -F " " '{print $1}'
192.168.206.206
g 查询sed.txt中空行所在的行号
[mayx@hadoop206 ~]$ awk '/^$/{print NR}' sed.txt
4
4 sort
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出
1)基本语法
sort(选项)(参数)
2)选项
- -n:依照数值的大小排序
- -r:以相反的顺序来排序
- -t:设置排序时所用的分割字符
- -k:指定需要排序的列
- 参数:指定待排序的文件列表
3)案例实操
数据准备
[mayx@hadoop206 ~]$ cat sort.txt
aa:56:23
bb:23:12
cc:23:09
dd:23:78
df:43:23
rg:17:23
a 按照“:”分割后的第三列倒序排序
[mayx@hadoop206 ~]$ sort -t: -nrk 3 sort.txt
dd:23:78
rg:17:23
df:43:23
aa:56:23
bb:23:12
cc:23:09
5 常用正则
^word 搜索以 word 开头的。vi/vim 中 ^ 代表一行的开头。
word$ 搜索以 word 结尾的。vi/vim 中 $ 代表一行的结尾。
^$ 以结尾开头,以开头结尾,表示空行
. 代表且只能代表任意一个字符
\ 转义符号,让有特殊身份意义的字符,脱掉马甲,还原原型。例:\. 只代表
点本身。
* 重复 0 个或多个前面的字符。
.* 匹配所有字符。例:^.* 以任意多个字符开头,.*$以任意多个字符结尾。
[abc] 匹配字符集内的任意一个字符。
[^abc] 匹配不包含 ^ 后的任意字符的内容。中括号里的 ^ 为取反。
a\{n,m\} 重复 n 到 m 次前一个重复的字符。若用 egrep、sed -r 可以去掉斜线。
\{n,\} 重复至少 n 次前一个重复的字符。若用 egrep、sed -r 可以去掉斜线。
\{n\} 重复 n 次前一个重复的字符。若用 egrep、sed -r 可以去掉斜线。
\{,m\} 重复最多 m 次
扩展正则:
+ 重复一个或一个以上前面的字符。
? 重复 0 个或一个前面的字符。
| (或者的意思)用或的方式查找多个符合的字符串。
() 找出括号内的字符串
6 应用
1)统计dd.txt文件的某一行字段的个数,假设字段分隔符为“||”
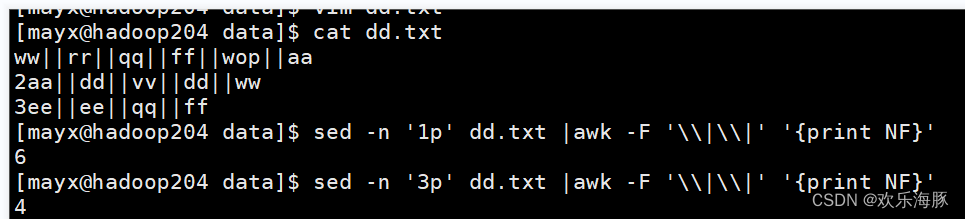

2)将指定内容替换
grep 'hello' -rl --include="test.txt" | xargs sed -i "s/hi/g"
3)将统计csv文件除首行外的字段数
cat a.csv |awk -F'","' 'NR>1{print NF}' |sort|uniq















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









