







一 窗口的概述
如下图所示,在Flink中,窗口可以把流切割成有限大小的多个“存储桶”(bucket);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
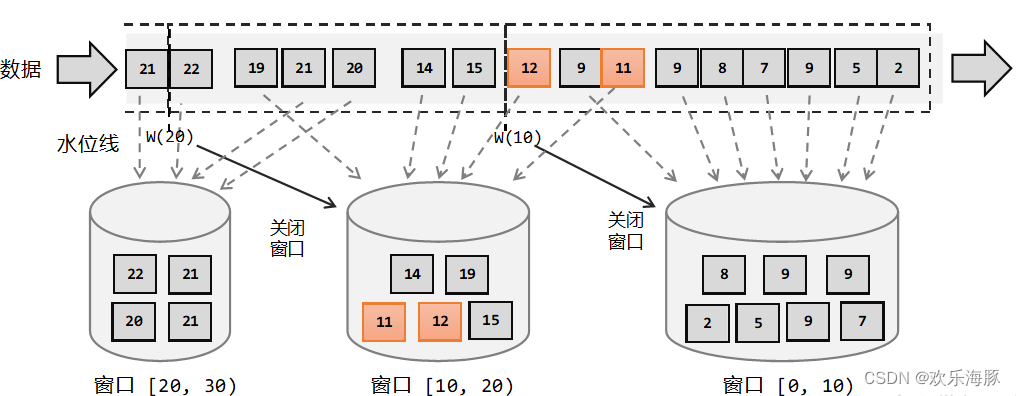
注意:Flink中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。另外,这里我们认为到达窗口结束时间时,窗口就触发计算并关闭,事实上“触发计算”和“窗口关闭”两个行为也可以分开,这部分内容我们会在后面详述。
二 窗口的分类
1 按照驱动类型分类
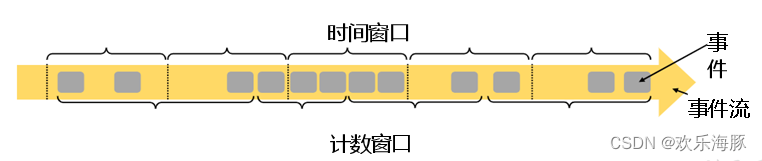
1)时间窗口(Time Window)
时间窗口以时间点来定义窗口的开始(start)和结束(end),所以接取出来的就是某一时间段的数据。到达结束时间时,窗口就不再收集数据,触发计算结果,并将窗口关闭销毁。基本思路是“定点发车”。
2)计数窗口(Count Window)
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。每个窗口截取数据的个数,及时窗口的大小。基本思路是“人齐发车”。
2 按照窗口分配的规则分类
根据分配数据的规则,窗口的具体实现可以分为4类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。
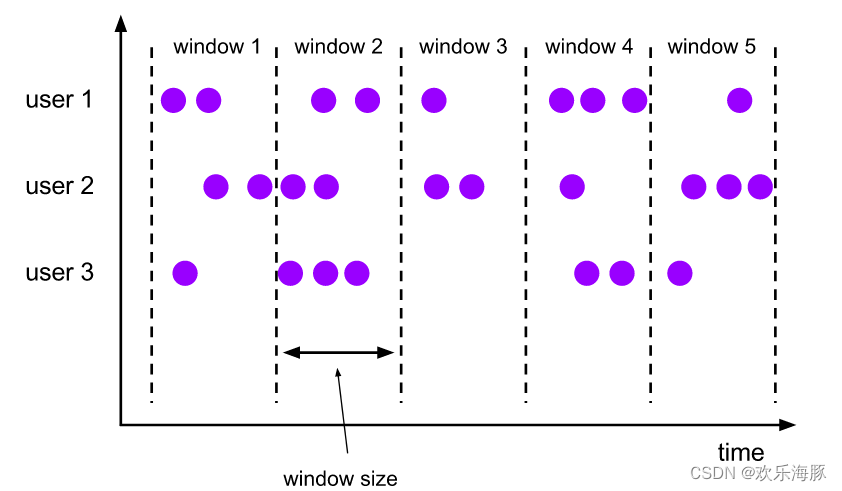
1)滚动窗口(Tumbling Window)
有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。每个数据都会分配到一个窗口,而且只会属于一个窗口。滚动窗口可以基于时间定义,也可以基于数据的个数定义,需要的参数只有一个,就是窗口的大小(window size)。
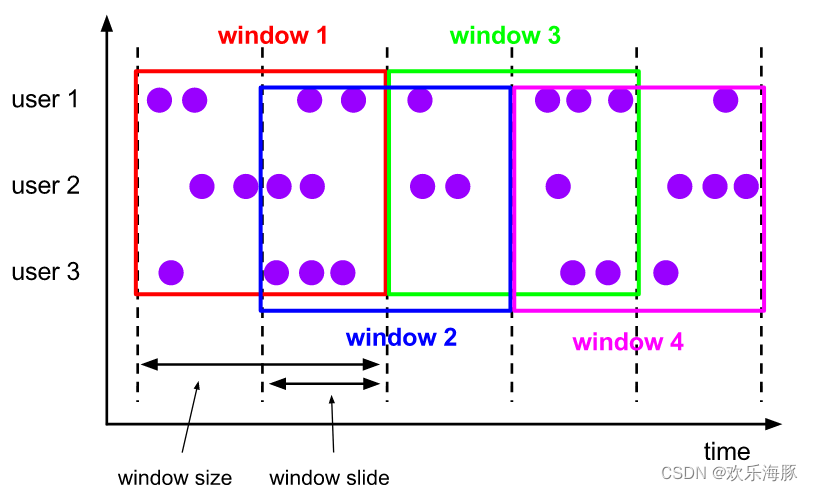
2)滑动窗口(Sliding Window)
大小是固定的,但是窗口之间不是收尾相接的,而是可以“错开”一定的位置。定义滑动窗口的参数有2个:窗口大小(window size)和滑动步长(window slide),滑动步长代表了窗口计算的频率。因此,如果 slide 小于窗口大小,滑动窗口可以允许窗口重叠。这种情况下,一个元素可能会被分发到多个窗口。
3)会话窗口(Session Windows)
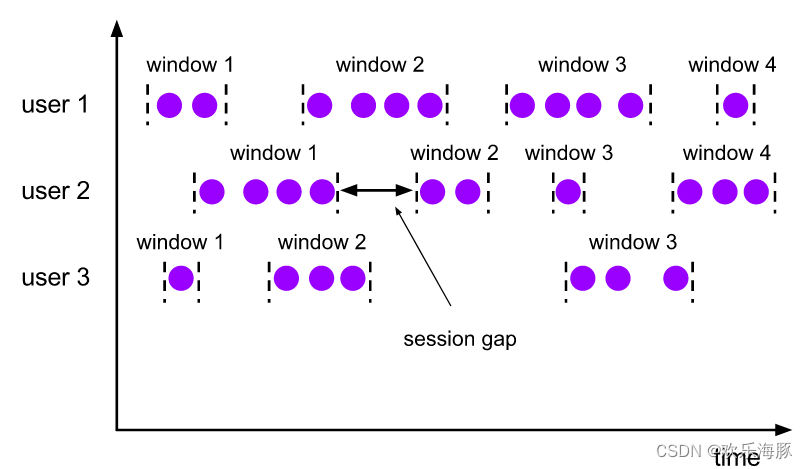
是基于会话来对数据进行分组的。会话窗口只能基于时间来定义。会话窗口中,最重要的参数就是会话的超时时间,也就是两个会话窗口之间的最小距离。如果相邻两个数据到来的时间间隔(Gap)小于指定的大小(size),那说明还在保持会话,他们就属于同一个窗口;如果gap大于Size,那么新来的数据就应该属于新的会话窗口,而前一个窗口就应该关闭了。会话窗口的长度不固定,起始和结束时间也不是确定的,各个分区之间窗口没有任何关联。会话窗口之间一定不会重叠的,而且会保留至少size的间隔。
4)全局窗口(Global Window)
这种窗口全局有效,会把相同key的所有数据都分配到同一个窗口中。这种窗口没有结束的时候,默认是不会触发计算的。如果希望它能对数据进行计算,还需要自定义“触发器”(Trigger)。全局窗口没有结束的时间点,所以一般在希望做更加灵活的窗口处理时自定义使用。Flink中的计数窗口(Count Window)底层就是用全局窗口实现的。

三 窗口的API
在定义窗口操作之前,首先需要确定,到底是基于按键分区(Keyed)的数据流KeyedStream来开窗,还是直接在没有按键分区的DataStream上开窗。也就是说,在调用窗口算子之前,是否有keyBy操作。
1 按键分区窗口(Keyed Windows)
经过按键分区keyBy操作后,数据流会按照key被分为多条逻辑流(logical streams),这就是KeyedStream。基于KeyedStream进行窗口操作时,窗口计算会在多个并行子任务上同时执行。相同key的数据会被发送到同一个并行子任务,而窗口操作会基于每个key进行单独的处理。所以可以认为,每个key上都定义了一组窗口,各自独立地进行统计计算。
在代码实现上,我们需要先对DataStream调用.keyBy()进行按键分区,然后再调用.window()定义窗口。
stream
.keyBy(...) <- 仅 keyed 窗口需要
.window(...) <- 必填项:"assigner"
[.trigger(...)] <- 可选项:"trigger" (省略则使用默认 trigger)
[.evictor(...)] <- 可选项:"evictor" (省略则不使用 evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (省略则为 0)
[.sideOutputLateData(...)] <- 可选项:"output tag" (省略则不对迟到数据使用 side output)
.reduce/aggregate/apply() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
2 非按键分区(Non-Keyed Windows)
如果没有进行keyBy,那么原始的DataStream就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了1。
在代码中,直接基于DataStream调用.windowAll()定义窗口。
stream
.windowAll(...) <- 必填项:"assigner"
[.trigger(...)] <- 可选项:"trigger" (else default trigger)
[.evictor(...)] <- 可选项:"evictor" (else no evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (else zero)
[.sideOutputLateData(...)] <- 可选项:"output tag" (else no side output for late data)
.reduce/aggregate/apply() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
注意:对于非按键分区的窗口操作,手动调大窗口算子的并行度也是无效的,windowAll本身就是一个非并行的操作
四 窗口分配器
定义窗口分配器(Window Assigners)是构建窗口算子的第一步,它的作用就是定义数据应该被“分配”到哪个窗口。所以可以说,窗口分配器其实就是在指定窗口的类型。
窗口分配器最通用的定义方式,就是调用.window()方法。这个方法需要传入一个WindowAssigner作为参数,返回WindowedStream。如果是非按键分区窗口,那么直接调用.windowAll()方法,同样传入一个WindowAssigner,返回的是AllWindowedStream。
窗口按照驱动类型可以分成时间窗口和计数窗口,而按照具体的分配规则,又有滚动窗口、滑动窗口、会话窗口、全局窗口四种。除去需要自定义的全局窗口外,其他常用的类型Flink中都给出了内置的分配器实现,我们可以方便地调用实现各种需求。
1 时间窗口
时间窗口是最常用的窗口类型,又可以细分为滚动、滑动和会话三种。
1)滚动处理时间窗口
窗口分配器由类TumblingProcessingTimeWindows提供,需要调用它的静态方法.of()。
stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
这里.of()方法需要传入一个Time类型的参数size,表示滚动窗口的大小,我们这里创建了一个长度为5秒的滚动窗口。
另外,.of()还有一个重载方法,可以传入两个Time类型的参数:size和offset。第一个参数当然还是窗口大小,第二个参数则表示窗口起始点的偏移量。
2)滑动处理时间窗口
窗口分配器由类SlidingProcessingTimeWindows提供,同样需要调用它的静态方法.of()。
stream.keyBy(...)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5)))
.aggregate(...)
这里.of()方法需要传入两个Time类型的参数:size和slide,前者表示滑动窗口的大小,后者表示滑动窗口的滑动步长。我们这里创建了一个长度为10秒、滑动步长为5秒的滑动窗口。
滑动窗口同样可以追加第三个参数,用于指定窗口起始点的偏移量,用法与滚动窗口完全一致。
3)处理时间会话窗口
窗口分配器由类ProcessingTimeSessionWindows提供,需要调用它的静态方法.withGap()或者.withDynamicGap()。
stream.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
这里.withGap()方法需要传入一个Time类型的参数size,表示会话的超时时间,也就是最小间隔session gap。我们这里创建了静态会话超时时间为10秒的会话窗口。
另外,还可以调用withDynamicGap()方法定义session gap的动态提取逻辑。
4)滚动事件时间窗口
窗口分配器由类TumblingEventTimeWindows提供,用法与滚动处理事件窗口完全一致。
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(...)
5)滑动事件时间窗口
窗口分配器由类SlidingEventTimeWindows提供,用法与滑动处理事件窗口完全一致。
stream.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)))
.aggregate(...)
6)事件时间会话窗口
窗口分配器由类EventTimeSessionWindows提供,用法与处理事件会话窗口完全一致。
stream.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
2 计算窗口
计数窗口概念非常简单,本身底层是基于全局窗口(Global Window)实现的。Flink为我们提供了非常方便的接口:直接调用.countWindow()方法。根据分配规则的不同,又可以分为滚动计数窗口和滑动计数窗口两类,下面我们就来看它们的具体实现。
1)滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数size,表示窗口的大小,以下是定义一个长度为10的滚动计数窗口,当窗口中元素数量达到10的时候,就会触发计算执行并关闭窗口。
stream.keyBy(...)
.countWindow(10)
2)滑动计数窗口
与滚动计数窗口类似,不过需要在.countWindow()调用时传入两个参数:size和slide,前者表示窗口大小,后者表示滑动步长。以下是定义了一个长度为10、滑动步长为3的滑动计数窗口。每个窗口统计10个数据,每隔3个数据就统计输出一次结果。
stream.keyBy(...)
.countWindow(10,3)
3)全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调用.window(),分配器由GlobalWindows类提供。需要注意使用全局窗口,必须自行定义触发器才能实现窗口计算,否则起不到任何作用。
stream.keyBy(...)
.window(GlobalWindows.create());
五 窗口函数(Window Functions)
定义了窗口分配器,我们可以把数据按照窗口收集起来了。在窗口分配器之后,必须调用窗口函数,来定义窗口是如何进行计算的操作。窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数。
1 增量聚合函数(ReduceFunction / AggregateFunction)
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。我们可以每来一个数据就在之前结果上聚合一次,这就是“增量聚合”。
典型的增量聚合函数有两个:ReduceFunction和AggregateFunction。
1)归约函数(ReduceFunction)
public class WindowReduceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("hadoop201", 6666)
.map(new MapFunction<String, WaterSensor>() {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
});
KeyedStream<WaterSensor, String> sensorKeyedDS = sensorDS.keyBy(sensor -> sensor.getId());
// 1. 窗口分配器
WindowedStream<WaterSensor, String, TimeWindow> sensorWS = sensorKeyedDS.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
// 2. 窗口函数,增量聚合
SingleOutputStreamOperator<WaterSensor> reduce = sensorWS.reduce(new ReduceFunction<WaterSensor>() {
@Override
public WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception {
System.out.println("调用reduce方法,value1=" + value1 + ",value2=" + value2);
return new WaterSensor(value1.getId(), value2.getTs(), value1.getVc() + value2.getVc());
}
});
reduce.print();
env.execute();
}
}
2)聚合函数(AggregateFunction)
ReduceFunction可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。
Flink Window API中的aggregate就突破了这个限制,可以定义更加灵活的窗口聚合操作。这个方法需要传入一个AggregateFunction的实现类作为参数。
AggregateFunction可以看作是ReduceFunction的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。输入类型IN就是输入流中元素的数据类型;累加器类型ACC则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
接口中有四个方法:
- createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
- add():将输入的元素添加到累加器中。
- getResult():从累加器中提取聚合的输出结果。
- merge():合并两个累加器,并将合并后的状态作为一个累加器返回。
所以可以看到,AggregateFunction的工作原理是:首先调用createAccumulator()为任务初始化一个状态(累加器);而后每来一个数据就调用一次add()方法,对数据进行聚合,得到的结果保存在状态中;等到了窗口需要输出时,再调用getResult()方法得到计算结果。很明显,与ReduceFunction相同,AggregateFunction也是增量式的聚合;而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便
public class WindowAggregateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop201", 6666)
.map(new MapFunction<String, WaterSensor>() {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
});
KeyedStream<WaterSensor, String> sensorKeyedDS = sensorDS.keyBy(sensor -> sensor.getId());
// 1. 窗口分配器
WindowedStream<WaterSensor, String, TimeWindow> sensorWS = sensorKeyedDS.
window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
// 2. 窗口函数: 增量聚合 Aggregate
/**
* 1、属于本窗口的第一条数据来,创建窗口,创建累加器
* 2、增量聚合: 来一条计算一条, 调用一次add方法
* 3、窗口输出时调用一次getresult方法
* 4、输入、中间累加器、输出 类型可以不一样,非常灵活
*/
SingleOutputStreamOperator<String> aggregate = sensorWS.aggregate(
new AggregateFunction<WaterSensor, Integer, String>() {
/**
* 创建累加器,初始化累加器
* @return
*/
@Override
public Integer createAccumulator() {
return 0;
}
/**
* 聚合逻辑
* @param value 输入
* @param accumulator 增量聚合
* @return 聚合结果
*/
@Override
public Integer add(WaterSensor value, Integer accumulator) {
System.out.println("调用add方法,value=" + value);
return accumulator + value.getVc();
}
/**
* 获取最终结果,窗口触发时输出
* @param accumulator
* @return
*/
@Override
public String getResult(Integer accumulator) {
System.out.println("调用getResult方法");
return accumulator.toString();
}
@Override
public Integer merge(Integer integer, Integer acc1) {
// 只有会话窗口才会用到
System.out.println("调用merge方法");
return null;
}
}
);
aggregate.print();
env.execute();
}
}
另外,Flink也为窗口的聚合提供了一系列预定义的简单聚合方法,可以直接基于WindowedStream调用。主要包括.sum()/max()/maxBy()/min()/minBy(),与KeyedStream的简单聚合非常相似。它们的底层,其实都是通过AggregateFunction来实现的。
2 全窗口函数(full window functions)
有些场景下,我们要做的计算必须基于全部的数据才有效,这时做增量聚合就没什么意义了;另外,输出的结果有可能要包含上下文中的一些信息(比如窗口的起始时间),这是增量聚合函数做不到的。
所以,我们还需要有更丰富的窗口计算方式。窗口操作中的另一大类就是全窗口函数。与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
在Flink中,全窗口函数也有两种:WindowFunction和ProcessWindowFunction。其中WindowFunction已过时
1) 处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction是Window API中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得ProcessWindowFunction更加灵活、功能更加丰富,其实就是一个增强版的WindowFunction。
public class WindowProcessDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("hadoop201", 6666)
.map(new MapFunction<String, WaterSensor>() {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
});
KeyedStream<WaterSensor, String> sensorKeyedDS = sensorDS.keyBy(sensor -> sensor.getId());
// 1. 窗口分配器
WindowedStream<WaterSensor, String, TimeWindow> sensorWS = sensorKeyedDS
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
SingleOutputStreamOperator<String> process = sensorWS
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
* 全窗口函数计算逻辑: 窗口触发时才会调用一次,统一计算窗口的所有数据
* @param s 分组的key
* @param context 上下文
* @param elements 存储的数据
* @param out 采集器
* @throws Exception
*/
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
// 上下文可以拿到window对象,还有其他东西:侧输出流 等等
long startTs = context.window().getStart();
long endTs = context.window().getEnd();
String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS");
String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
Integer vc = 0;
Iterator<WaterSensor> iterator = elements.iterator();
while (iterator.hasNext()) {
WaterSensor sensor = iterator.next();
vc = sensor.getVc() + vc;
WaterSensor waterSensor = new WaterSensor(sensor.getId(), sensor.getTs(), vc);
System.out.println(waterSensor);
}
out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + "]包含" + count + "条数据===>" + elements.toString());
}
});
process.print();
env.execute();
}
}
3 增量聚合和全窗口函数的结合使用
在实际应用中,我们往往希望兼具这两者的优点,把它们结合在一起使用。Flink的Window API就给我们实现了这样的用法。
我们之前在调用WindowedStream的.reduce()和.aggregate()方法时,只是简单地直接传入了一个ReduceFunction或AggregateFunction进行增量聚合。除此之外,其实还可以传入第二个参数:一个全窗口函数,可以是WindowFunction或者ProcessWindowFunction。
// ReduceFunction与WindowFunction结合
public <R> SingleOutputStreamOperator<R> reduce(
ReduceFunction<T> reduceFunction,WindowFunction<T,R,K,W> function)
// ReduceFunction与ProcessWindowFunction结合
public <R> SingleOutputStreamOperator<R> reduce(
ReduceFunction<T> reduceFunction,ProcessWindowFunction<T,R,K,W> function)
// AggregateFunction与WindowFunction结合
public <ACC,V,R> SingleOutputStreamOperator<R> aggregate(
AggregateFunction<T,ACC,V> aggFunction,WindowFunction<V,R,K,W> windowFunction)
// AggregateFunction与ProcessWindowFunction结合
public <ACC,V,R> SingleOutputStreamOperator<R> aggregate(
AggregateFunction<T,ACC,V> aggFunction,
ProcessWindowFunction<V,R,K,W> windowFunction)
这样调用的处理机制是:基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了Iterable类型的输入。
public class WindowAggregateAndProcessDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("hadoop201", 6666)
.map(new MapFunction<String, WaterSensor>() {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
});
KeyedStream<WaterSensor, String> sensorKeyedDS = sensorDS.keyBy(sensor -> sensor.getId());
// 1. 窗口分配器
WindowedStream<WaterSensor, String, TimeWindow> sensorWS = sensorKeyedDS
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
// 2. 窗口函数:
/**
* 增量聚合 Aggregate + 全窗口 process
* 1、增量聚合函数处理数据: 来一条计算一条
* 2、窗口触发时, 增量聚合的结果(只有一条) 传递给 全窗口函数
* 3、经过全窗口函数的处理包装后,输出
*
* 结合两者的优点:
* 1、增量聚合: 来一条计算一条,存储中间的计算结果,占用的空间少
* 2、全窗口函数: 可以通过 上下文 实现灵活的功能
*/
SingleOutputStreamOperator<String> aggregate = sensorWS.aggregate(
new MyAgg(),
new MyProcess()
);
aggregate.print();
env.execute();
}
public static class MyAgg implements AggregateFunction<WaterSensor, Integer, String>{
@Override
public Integer createAccumulator() {
System.out.println("创建累加器");
return 0;
}
@Override
public Integer add(WaterSensor value, Integer accumulator) {
System.out.println("调用add方法,value="+value);
return accumulator + value.getVc();
}
@Override
public String getResult(Integer accumulator) {
System.out.println("调用getResult方法");
return accumulator.toString();
}
@Override
public Integer merge(Integer a, Integer b) {
System.out.println("调用merge方法");
return null;
}
}
// 全窗口函数的输入类型 = 增量聚合函数的输出类型
public static class MyProcess extends ProcessWindowFunction<String,String,String,TimeWindow>{
@Override
public void process(String s, Context context, Iterable<String> elements, Collector<String> out) throws Exception {
long startTs = context.window().getStart();
long endTs = context.window().getEnd();
String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS");
String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());
}
}
}














 2629
2629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









