看到了这个不错的博客,,就转载了,如有侵权,请及时告知
什么是线性模型
相信大多数人,刚开始接触机器学习的时候,就会接触到线性模型。来看一个简单的例子:通过人的年龄、受教育年数、工作年限等信息,可以预测出一个人的基本收入水平,预测方法就是对前面的限定特征赋予不同的权值,最后计算出工资;此外,线性模型也可以用于分类,例如逻辑回归就是一种典型的线性分类器。
相对于其他的复杂模型来说,线性模型主要有以下几个优点:
- 训练速度快
- 大量特征集的时候工作的很好
- 方便解释和debug,参数调节比较方便
tf.learn关于线性模型的一些API
- FeatureColumn
- sparse_column 用于解决类别特征的稀疏问题,对于类别型的特征,一般使用的One hot方法,会导致矩阵稀疏的问题。
eye_color = tf.contrib.layers.sparse_column_with_keys(
column_name="eye_color", keys=["blue", "brown", "green"])
education = tf.contrib.layers.sparse_column_with_hash_bucket(\
"education", hash_bucket_size=1000)#不知道所有的可能值的时候用这个接口
- Feature Crosses 可以用来合并不同的特征
sport = tf.contrib.layers.sparse_column_with_hash_bucket(\
"sport", hash_bucket_size=1000)
city = tf.contrib.layers.sparse_column_with_hash_bucket(\
"city", hash_bucket_size=1000)
sport_x_city = tf.contrib.layers.crossed_column(
[sport, city], hash_bucket_size=int(1e4))
- Continuous columns 用于连续的变量特征
age = tf.contrib.layers.real_valued_column(“age”)
- Bucketization 将连续的变量变成类别标签
age_buckets = tf.contrib.layers.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
tf.contrib.learn.LinearClassifier和LinearRegressor
这两个一个用于分类,一个用于回归,使用步骤如下
- 创建对象实例,在构造函数中传入featureColumns
- 用fit训练模型
- 用evaluate评估
下面是一段示例代码:
e = tf.contrib.learn.LinearClassifier(feature_columns=[
native_country, education, occupation, workclass, marital_status,
race, age_buckets, education_x_occupation, age_buckets_x_race_x_occupation],
model_dir=YOUR_MODEL_DIRECTORY)
e.fit(input_fn=input_fn_train, steps=200)
# Evaluate for one step (one pass through the test data).
results = e.evaluate(input_fn=input_fn_test, steps=1)
# Print the stats for the evaluation.
for key in sorted(results):
print "%s: %s" % (key, results[key])
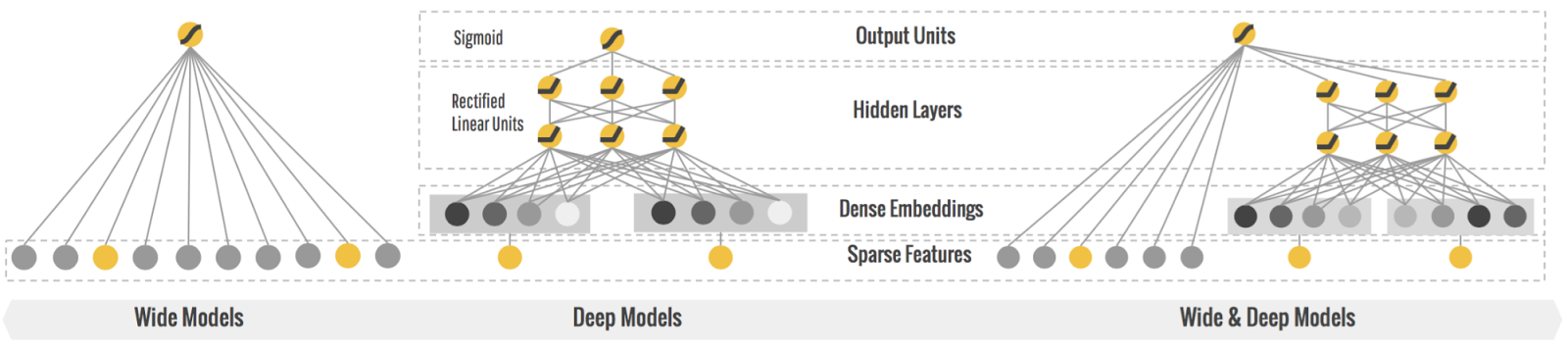
Wide and deep learning
最近刚看了这篇论文,打算专门写一章来详细讲解,这个训练模型的出现是为了结合memorization和generalization。下面推荐几篇文章:
模型结构如下:
数据描述
下面我们用具体的示例来演示如何使用线性模型:通过统计数据,从一个人的年龄、性别、教育背景、职业来判断这个人的年收入是否超过50000元,如果超过就为1,否则输出0.下面是我从官网截取的数据描述:
- Listing of attributes: >50K, <=50K.
- age: continuous.
- workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked.
- fnlwgt: continuous.
- education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool.
- education-num: continuous.
- marital-status: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse.
- occupation: Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, * * Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces.
- relationship: Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried.
- race: White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black.
- sex: Female, Male.
- capital-gain: continuous.
- capital-loss: continuous.
- hours-per-week: continuous.
- native-country: United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands.
数据源
代码实现
注意事项,请在Linux上运行该段代码!window会出现下面的错误:
AttributeError: ‘NoneType’ object has no attribute ‘bucketize’
如果确实想运行在windows上,请将model_type,修改为deep:
flags.DEFINE_string(“model_type”,”deep”,”valid model types:{‘wide’,’deep’, ‘wide_n_deep’”)
follow this issue
import tempfile
import tensorflow as tf
from six.moves import urllib
import pandas as pd
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_string("model_dir","","Base directory for output models.")
flags.DEFINE_string("model_type","wide_n_deep","valid model types:{'wide','deep', 'wide_n_deep'")
flags.DEFINE_integer("train_steps",200,"Number of training steps.")
flags.DEFINE_string("train_data","", "Path to the training data.")
flags.DEFINE_string("test_data", "", "path to the test data")
COLUMNS = ["age", "workclass", "fnlwgt", "education", "education_num",
"marital_status", "occupation", "relationship", "race", "gender",
"capital_gain", "capital_loss", "hours_per_week", "native_country",
"income_bracket"]
LABEL_COLUMN = "label"
CATEGORICAL_COLUMNS = ["workclass", "education", "marital_status", "occupation",
"relationship", "race", "gender", "native_country"]
CONTINUOUS_COLUMNS = ["age", "education_num", "capital_gain", "capital_loss",
"hours_per_week"]
def maybe_download():
if FLAGS.train_data:
train_data_file = FLAGS.train_data
else:
train_file = tempfile.NamedTemporaryFile(delete=False)
urllib.request.urlretrieve("http://mlr.cs.umass.edu/ml/machine-learning-databases/adult/adult.data", train_file.name)
train_file_name = train_file.name
train_file.close()
print("Training data is downloaded to %s" % train_file_name)
if FLAGS.test_data:
test_file_name = FLAGS.test_data
else:
test_file = tempfile.NamedTemporaryFile(delete=False)
urllib.request.urlretrieve("http://mlr.cs.umass.edu/ml/machine-learning-databases/adult/adult.test",
test_file.name)
test_file_name = test_file.name
test_file.close()
print("Test data is downloaded to %s" % test_file_name)
return train_file_name, test_file_name
def build_estimator(model_dir):
gender = tf.contrib.layers.sparse_column_with_keys(column_name="gender", keys=["female","male"])
education = tf.contrib.layers.sparse_column_with_hash_bucket("education", hash_bucket_size = 1000)
relationship = tf.contrib.layers.sparse_column_with_hash_bucket("relationship", hash_bucket_size = 100)
workclass = tf.contrib.layers.sparse_column_with_hash_bucket("workclass", hash_bucket_size=100)
occupation = tf.contrib.layers.sparse_column_with_hash_bucket("occupation", hash_bucket_size=1000)
native_country = tf.contrib.layers.sparse_column_with_hash_bucket( "native_country", hash_bucket_size=1000)
age = tf.contrib.layers.real_valued_column("age")
education_num = tf.contrib.layers.real_valued_column("education_num")
capital_gain = tf.contrib.layers.real_valued_column("capital_gain")
capital_loss = tf.contrib.layers.real_valued_column("capital_loss")
hours_per_week = tf.contrib.layers.real_valued_column("hours_per_week")
age_buckets = tf.contrib.layers.bucketized_column(age, boundaries= [18,25, 30, 35, 40, 45, 50, 55, 60, 65])
wide_columns = [gender, native_country,education, occupation, workclass, relationship, age_buckets,
tf.contrib.layers.crossed_column([education, occupation], hash_bucket_size=int(1e4)),
tf.contrib.layers.crossed_column([age_buckets, education, occupation], hash_bucket_size=int(1e6)),
tf.contrib.layers.crossed_column([native_country, occupation],hash_bucket_size=int(1e4))]
deep_columns = [tf.contrib.layers.embedding_column(workclass, dimension=8),
tf.contrib.layers.embedding_column(education, dimension=8),
tf.contrib.layers.embedding_column(gender, dimension=8),
tf.contrib.layers.embedding_column(relationship, dimension=8),
tf.contrib.layers.embedding_column(native_country,dimension=8),
tf.contrib.layers.embedding_column(occupation, dimension=8),
age,education_num,capital_gain,capital_loss,hours_per_week,]
if FLAGS.model_type =="wide":
m = tf.contrib.learn.LinearClassifier(model_dir=model_dir,feature_columns=wide_columns)
elif FLAGS.model_type == "deep":
m = tf.contrib.learn.DNNClassifier(model_dir=model_dir, feature_columns=deep_columns, hidden_units=[100,50])
else:
m = tf.contrib.learn.DNNLinearCombinedClassifier(model_dir=model_dir, linear_feature_columns=wide_columns, dnn_feature_columns = deep_columns, dnn_hidden_units=[100,50])
return m
def input_fn(df):
continuous_cols = {k: tf.constant(df[k].values) for k in CONTINUOUS_COLUMNS}
categorical_cols = {k: tf.SparseTensor(indices=[[i,0] for i in range( df[k].size)], values = df[k].values, shape=[df[k].size,1]) for k in CATEGORICAL_COLUMNS}
feature_cols = dict(continuous_cols)
feature_cols.update(categorical_cols)
label = tf.constant(df[LABEL_COLUMN].values)
return feature_cols, label
def train_and_eval():
train_file_name, test_file_name = maybe_download()
df_train = pd.read_csv(
tf.gfile.Open(train_file_name),
names=COLUMNS,
skipinitialspace=True,
engine="python"
)
df_test = pd.read_csv(
tf.gfile.Open(test_file_name),
names=COLUMNS,
skipinitialspace=True,
skiprows=1,
engine="python"
)
df_train = df_train.dropna(how='any',axis=0)
df_test = df_test.dropna(how='any', axis=0)
df_train[LABEL_COLUMN] = (
df_train["income_bracket"].apply(lambda x: ">50" in x).astype(int)
)
df_test[LABEL_COLUMN] = (
df_test["income_bracket"].apply(lambda x: ">50K" in x)).astype(int)
model_dir = tempfile.mkdtemp() if not FLAGS.model_dir else FLAGS.model_dir
print("model dir = %s" % model_dir)
m = build_estimator(model_dir)
print (FLAGS.train_steps)
m.fit(input_fn=lambda: input_fn(df_train),
steps=FLAGS.train_steps)
results = m.evaluate(input_fn=lambda: input_fn(df_test), steps=1)
for key in sorted(results):
print("%s: %s"%(key, results[key]))
def main(_):
train_and_eval()
if __name__ == "__main__":
tf.app.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
运行结果:
- accuracy: 0.825686
- accuracy/baseline_label_mean: 0.236226
- accuracy/threshold_0.500000_mean: 0.825686
- auc: 0.820967
- global_step: 202
- labels/actual_label_mean: 0.236226
- labels/prediction_mean: 0.199659
- loss: 0.443123
- precision/positive_threshold_0.500000_mean: 0.766385
- recall/positive_threshold_0.500000_mean: 0.377015
可以将model_type切换为deep,wide,deep_n_wide,查看不同的输出结果!
另外,先将model_type换成wide, 为了防止线性模型的过拟合,可以在LinearClassifier中加上一个optimizer的参数,如下:
m = tf.contrib.learn.LinearClassifier(feature_columns=[
gender, native_country, education, occupation, workclass, marital_status, race,
age_buckets, education_x_occupation, age_buckets_x_education_x_occupation],
optimizer=tf.train.FtrlOptimizer(
learning_rate=0.1,
l1_regularization_strength=1.0,
l2_regularization_strength=1.0),
model_dir=model_dir)
reference
- https://archive.ics.uci.edu/ml/datasets/Census+Income
- https://www.tensorflow.org/tutorials/wide/























 2557
2557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









