







文献原文地址:https://www.sciencedirect.com/science/article/pii/S0167865518301065?via%3Dihub
文献:Deep generative video prediction
该文献介绍了一种深度生成视频预测模型,主要由运动编码器,帧生成器,帧鉴别器组成。还使用了一种跨通道颜色梯度损失方式处理模糊。
1)运动编码器:给定一个动态时间序列,生成预测运动表征(使用LSTM和3D卷积)
2)帧生成器:给定和最后一帧视频帧Xt,生成
帧预测视频(伪反双流网络,动态流用于高频【边缘信息】动态评估,静态流用来维护低频信息)
3)帧鉴别器:(使用3D卷积网络)因为2D卷积网络不能对多个重叠图像进行识别
训练算法:

误差:
1)重构误差:使用L1型损失(L2型损失可能导致运动表征模糊化)
2)对抗误差:鉴别器D和生成器G对抗训练,达到纳什平衡
3)跨通道颜色梯度损失误差:相同位置两个通道之间的差值
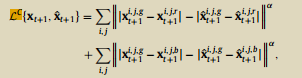
4)组合:
![]()
数据集:
moving minst,UCF-101,Ms.pac-Man














 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









