







前言
对于ai训练来说,处理训练集是模型训练的重要环节。训练集的质量对最终模型的质量影响巨大。这里以二次元角色为例,记录下训练集处理的流程和一些心得。
素材准备
素材准备有以下几个需要注意的点:
- 通常训练二次元角色需要30张以上的图片,训练三次元角色需要50张以上的图片。原因是三次元图像里面包含的细节更多。
- 训练集最关键的是“质”而不是“量”。单纯堆图片数量并不能保证好的训练效果。
- 训练集图片需要保证图片中仅包含训练角色一个人物,其他人物需要裁剪掉。
- 训练集图片中人物尽可能包含不同的角度,动作,服饰,风格。
- 训练集图片中一些有负面影响的元素需要适当删改掉,比如文字,水印等。不好处理可以涂抹掉。
素材裁剪
stable diffusion常用的模型是基于SD1.5的,建议尺寸不要高于768,不小于512。尺寸过大对于显存的要求会很高。

素材裁剪可以使用【分割过大的图像】,重叠比例可以适当调高,这样裁剪出来的图像更多,更适合挑选。
素材打标
素材打标通常是先自动打标,再根据一定的规则进行手动删改。
自动打标
自动打标可以使用WD1.4反推工具。
简单介绍WD1.4的用法
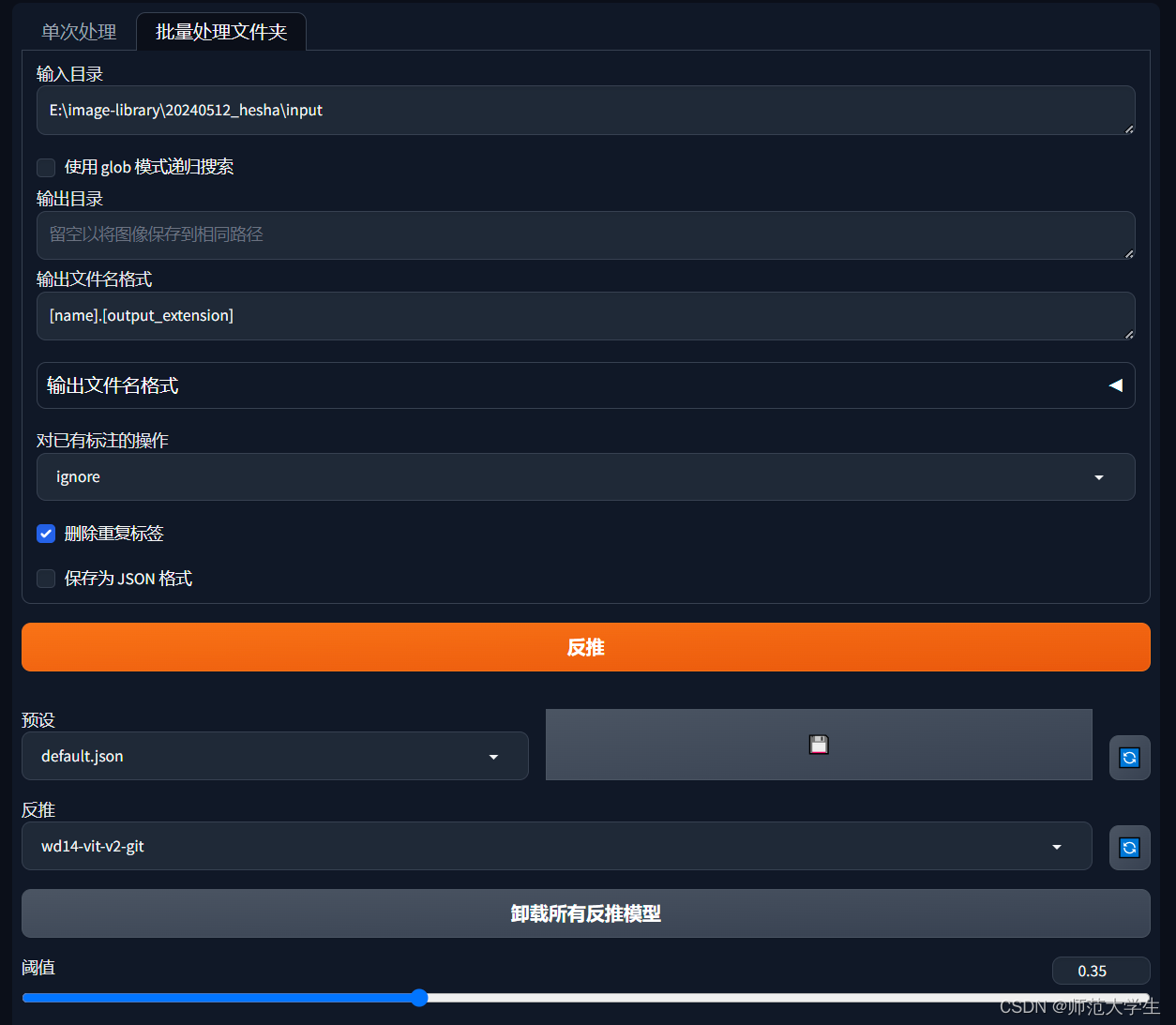
单次处理和批量处理的原理是一样的。这里主要涉及两个概念,反推模型与阈值。
反推模型:反推模型的作用是将一幅图片的提示词推理出来,推荐反推模型中的wd14-vit-v2-git、wd14-convnextv2-v2-git和wd14-swinv2-v2-git,其中wd14-vit-v2-git最快,wd14-swinv2-v2-git最准确。
阈值:低于阈值则删除这个关键词,三次元建议0.35,二次元动漫人物建议0.5。
标签修改
自动打标的标签可以直接使用,但是通常我们会基于自身需求对TAG做一些删改。删改的原则如下:
- 自动打标识别出的角色词要删除,比如“野比大雄”这种。保留自动打标的角色词会导致生成图片的时候,会触发大模型(底模型)里的提示词,进而调用大模型里面的特征。
- 不想让模型训练到的特征建议保留。比如一个角色在很多图片里面都握着一把剑,但是我不想生成图片时该角色默认拥有“持剑”的特征,所以,类似于“holding weapon”,“sword”这种提示词建议保留。
- 希望让模型训练到的特征建议删除。比如一个角色是黑头发,戴着眼镜。我希望生成图片时该角色默认就是黑头发和戴眼镜,我不会调整他的发色或者不戴眼镜。所以,“black hair”,“wearing glasses”这种提示词建议删除。当然这样的操作有优点也有缺点。优点是减少了必要的提示词数量;缺点是降低了模型的泛化性,在上文提到的场景中,如果我在生成图片时额外设置提示词“green hair”,可能效果不明显,因为“黑头发”这个特征已经被该模型学习到了。
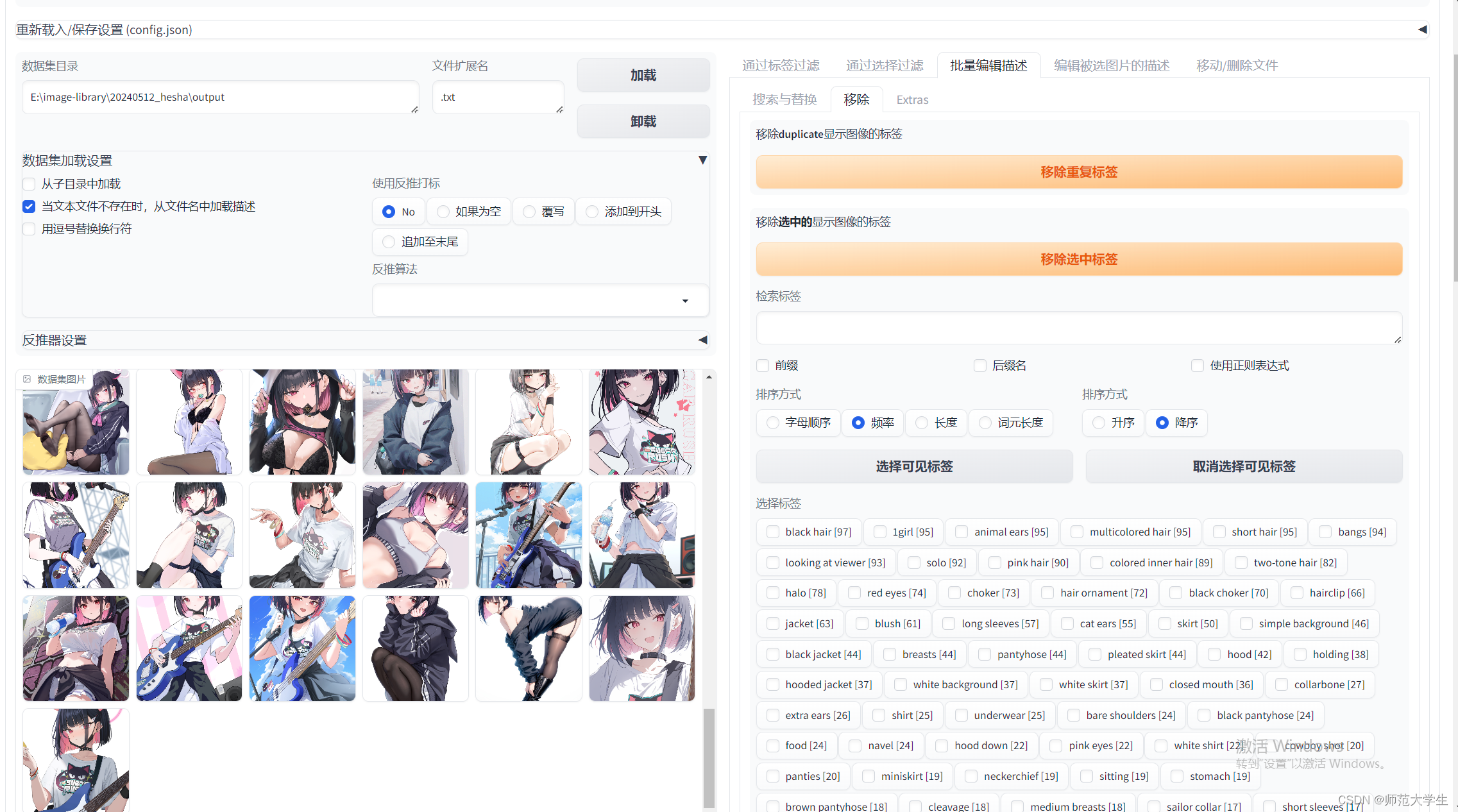
标签编辑器如上图所示。在批量编辑描述中,可以选择特定的TAG进行删除。
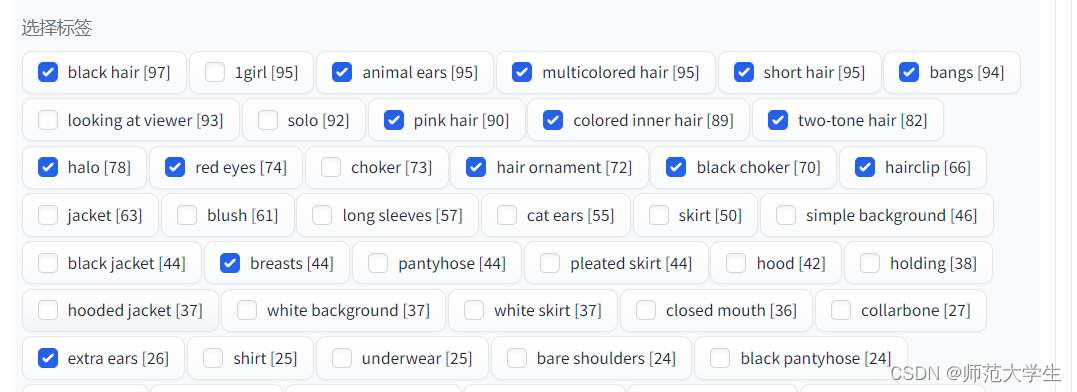
比如这次训练的一个角色,我将她的固有特征TAG进行删除,这样就可以让模型学习到这些特征,比如“短发”,“兽耳”,“红眼”。因为这些特征希望生成图片时默认存在。
衣服,动作,表情之类的TAG全部进行了保留,这样用提示词为人物更换衣服,动作,表情效果会更明显。
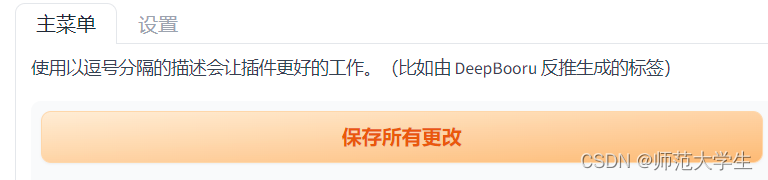
修改完后点击保存所有更改,并在文件夹中删除所有的过程文件即可。















 7667
7667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









