







Character Region Awareness for Text Detection
https://arxiv.org/abs/1904.01941
思想:
作者提出了一个character-level的文本检测方法,通过对character和affinity between characters的分割,实现对arbitrary shape的word的检测与完美描绘。
重点:
1.通过character-level的detection来实现曲折文本的识别(蛇形文本)
2.通过affinity between characters让文本易于分割
3.采用半监督的方式,让word-level的文本可进行character-level的训练
4.不需要大的感受野,只关心intra-character和inter-character
label的生成

score map 表示的分别是character中心和相连的characters的中心的概率,这里用高斯分布表示
- 画出character box
- 画出character box的对角线,然后取上下两个三角形的中心,中心相连,affinity box
- 用一个各向同性的高级分布通过透视变化到框中
- 将高斯分布放到gt中
弱监督学习

作者在使用具有字符级别标注的合成图片的同时,也用半监督的方式将单词级别标注的数据库用于训练。具体的思路是使用网络生成的score map生成伪标注作为真实标签进行训练

考虑到标签的真实性:
用word标注的长度l(w)判断标签的质量
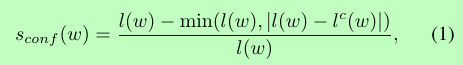

从scoremap生成box的两种方式

- 构建一个二值图,其中Sr和Sa大于阈值的为1,其余为0
- 用CCL分块
- 找最小外接四边形或者用如下方法
① 找到分块的局部最长线(蓝)
② 将它们的中点相连(黄),并让最长线与中心线垂直(红)
③ 给每个红线留些余量,然后相连
思考
character level detection 和 affinity between characters 的本质都是pixel 级别的检测,不过label的方式是以character和affinity为单位生成的高斯矩阵给的,所以所用的网络主体还是U-net,但是和之前的网络不同的地方在于三个点
- 把文本框中的内容分的更为细致,分为了character level的标注,和affinity的标注,这对于网络而言是一种任务的降维,也更容易回归正确
- affinity的引入,使得text line和text line的划分变得更为简单,不容易混淆
- character level 得到的结果如最后的图所示的话,这种圆盘连线的方式对于任意性状 的长条形文本的回归更贴切















 4052
4052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









