







 思想本论文与Unet方法不同,用Mask R-CNN类的方法来实现任意形状文本的检测,其中,它借用FPN网络的对矩形框的优异的检测性能,很好的找出文本的区域的矩形框,而后,通过一个基于LSTM的refine proposal模块来细致的描绘文本区,这巧妙的通过roi-pooling layer得到的特征进行任意形状框的回归(将feature作为LSTM每个step的输入,然后回归出任意长度点的序...
思想本论文与Unet方法不同,用Mask R-CNN类的方法来实现任意形状文本的检测,其中,它借用FPN网络的对矩形框的优异的检测性能,很好的找出文本的区域的矩形框,而后,通过一个基于LSTM的refine proposal模块来细致的描绘文本区,这巧妙的通过roi-pooling layer得到的特征进行任意形状框的回归(将feature作为LSTM每个step的输入,然后回归出任意长度点的序...
思想
本论文与Unet方法不同,用Mask R-CNN类的方法来实现任意形状文本的检测,其中,它借用FPN网络的对矩形框的优异的检测性能,很好的找出文本的区域的矩形框,而后,通过一个基于LSTM的refine proposal模块来细致的描绘文本区,这巧妙的通过roi-pooling layer得到的特征进行任意形状框的回归(将feature作为LSTM每个step的输入,然后回归出任意长度点的序列)。这相对于Unet等的方法,有效解决了混淆文本的问题,且可能对小文本较友好。但是,对于长宽比极端的文本不太好。同时,LSTM的使用,使得它变成了一种自适应的形式,可以不拘泥与固定的输出长度,对实际检测中因有不同长度的文本的情况更友好
具体实现
1.网络结构

2.流程
FPN的RPN部分检测出文本框,roi-pooling的输出分为两个branch,第一个branch经过全连接卷层得到更精准的是否文本的分类和边界框回归,第二个branch则将通过LSTM得到任意长度的点序列,构成任意形状的文本框
3.具体实现
3.1 RPN部分
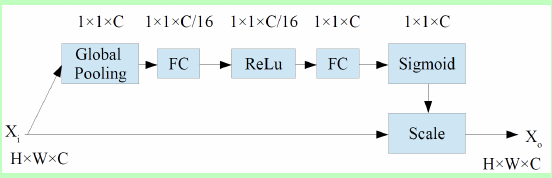
主体网络为SE-VGG16,在VGG16的基础上,在每个level的feature map的尾端加上SE block,这个block是channel attention的思想,计算出每个channel的重要程度,进行调整
3.2 Proposal refinement
这里只说关于refine的这一个branch,先补充一个先验,就是作者发现大部分的文本为长条状的,上下的边界点是具有一种近似的对称性的,所以对于文本边界点的预测可以采用上下点同时预测的形式,而不是采用顺顺时针预测的形式,这种预测的方法更贴近文本的几何特征和对LSTM的理解

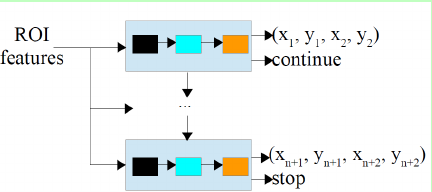
roi pooling提取到的特征会被全部输入到每个step中,而得到两种参数,第一种是对当前step的上下点的预测,第二种是对是否停止预测点的预测。分为两种类型的输出是因为这两种类型的数据形式差异比较大,所以分成两路输出。
其中( x 1 x_{1} x1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









