










redis简介:
1、redis是单线程
2、安装完成之后默认16个数据库,默认使用0号数据库
切换数据库使用select命令,如"select 2"就是切换到2号数据库
3、16个库的密码都是一样的,要么一个都连不上,要么全能连上(redis默认没有密码)
一、redis安装
二、redis设置外网访问
redis默认开启了保护模式,在保护模式下只有本地可以访问(因为bind配的是127.0.0.1),所以redis默认没有密码
设置外网访问的两个相关配置:
- 配置redis.conf文件中的bind 设置但是可以通过哪个IP来访问(这个IP可以是redis安装的服务器的IP,也可以是自定义的IP),如果bind 设置为192.168.1.117,那么只能通过192.168.1.117来访问,在Java代码中实例化jedis的时候就要写Jedis jedis = new Jedis(“192.168.1.117”,6379),如果bind 设置为0.0.0.0,则可以通过哪个IP来访问。

- protected-mode 保护模式(除本机外,其他的都无法连接上),默认是开启的,要设置外网访问需要将它改为no。

设置外网访问的3种方法
- 注释掉bind并把protected-mode设置为no
- 使用bind
- 设置密码
- redis五大数据类型
String、List、Set、Hash、Zset
String
命令行:
Set key value 设置key value
Get key 查看当前key的值
Del key 删除key
Append key value 如果key存在,则指定的key末尾添加,如果key不存在则类似set 命令
Strlen key 返回此key的长度
Java代码:
Mset:连续操作,jedis.mset(“k1”,”v1”,”k2”,”v2”,”k3”,”v3”)
等同于jedis.mset(“k1”,”v1”),jedis.mset(”k2”,”v2”),jedis.mset(”k3”,”v3”),mset比set效率要高
Mget: 连续操作,jedis.mget(“k1”,”k2”,”k3”)
等同于jedis.mget(“k1”),jedis.mget(”k2”),jedis.mget(”k3”)
Setnx: 这个key存在就不设置了,不存在就设置
Setex: 设置过期时间jedis.setex(“k1”,60,”v1”)单位是秒,60秒之后key就被自动删除
Ttl: jedis.ttl(“k1”),查询key还有多久过期,返回-1是永不过期,-2已经过期
List
Lpush: jedis.lpush(“lpush”,”v1”,”v2”,”v3”,”v4”)给左边添加,结果是v4,v3,v2,v1
Rpush: jedis.rpush(“rpush”,”v1”,”v2”,”v3”,”v4”)给右边添加,结果是v1,v2,v3,v4
Lpop: jedis.lpop(“lpush”)从左边出栈,删除左边第一个
Rpop: jedis.rpop(“rpush”)从右边出栈,删除右边第一个
set 无序不重复
Jedis.sadd(“set1”,”v1”,”v2”,”v3”,”v4”)
Jedis.smember(“set1”):查看set1的所有元素
Jedis.sismember(“set1”,”v1”):判断v1是否存在于set1当中
Jedis.sdiff(“set1”,”set2”):差集,存在于set1,不存在于set2
Jedis.sinser(“set1”,”set2”):交集
Jedis.sunion(“set1”,”set2”):并集并去重
zset有序不重复
Value后面加d就可以实现排序
Map<String,Double> map = new HashMap<>();
Map.put(“k1”,10d);
Map.put(“k2”,20d);
Map.put(“k3”,30d);
Map.put(“k4”,40d);
Jedis.zadd(“zset”,map);
Jedis.zrangWithScores(“zset”,0,-1);//输出一下zset的所有元素
[[k1,10.0],[k2,20.0],[k3,30.0],[k4,40.0]]
Hash
value本身就是一个map,那么就是map套map
- Pipeline管道
Pipeline可以大幅度提高给redis写入数据的速度,如果用如下的方法进行写数据的话,10000条数据需要7分钟。因为Jedis.hset方法要连接10000次redis,写入10000次。
For(int =0;i<10000;i++){
Jedis.hset(“aaaa”+i,”aaaa”+i,”aaaa”+i);
}
如果采用管道,把每100条数据打成一个包,总共打成100个包,存入100个管道,提交100次,那么10000条只需要7秒钟时间。因为pipeline只需要连接100次redis,提交100次,写入10000次。
For(int =0;i<10000;i++){
Pipeline pipeline = jedis.pipelined();
For(int j=i+100;j<(i+1)*100;j++){
pipeline .hset(“bbbb”+j,”bbbb”+j,”bbbb”+j);
}
Pipeline.syncAndRetuenAll();
}
- redis持久化
就是在指定时间间隔内,将内存当中的数据集快照写入磁盘,它恢复时将持久化文件直接读取到内存。
Redis提供两种持久化方式。
一种是默认的RDB持久化;
一种是AOF持久化。
RBD持久化
- 什么是RDB?
Redis启动时会自动调用fork方法创建一个与redis进程一模一样的fork进程,这个进程的所有数据(变量,环境变量、程序计数器等)都和原进程一模一样。Fork进程会先将数据写入到一个临时文件,待持久化结束了,在用这个临时文件替换上一次持久化好的文件。整个过程中,主进程不进行任何IO操作,这就确保主进程性能不受影响。
- 持久化文件在哪?
Redis启动目录是哪里,持久化文件就默认生成在哪里
3、它什么时候fork子进程?什么时候触发RDB持久化机制?
Redis启动时会自动创建
- shutdown时,如果没有配置aof,则会触发RDB
- 配置文件中默认的快照配置(在redis集群中通常会注释掉master配置文件中save配置)

- 手动执行save或者bgsave命令。save命令不会fork子进程,只管保存,其他不管,全部阻塞。bgsave会fork子进程,子进程会在后台异步进行快照操作,同时可以响应客户端的的请求。
AOF持久化
- 什么是aof?
将redis的操作日志以追加的方式写入文件,读操作是不记录的。这样当redis宕机了下次重启时候会去读这个文件,然后将命令执行
- Aof持久化文件是哪里?
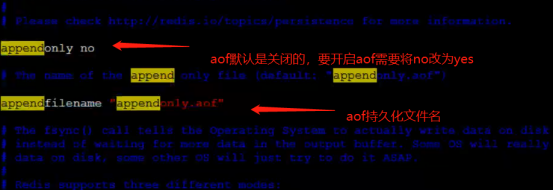
- Aof持久化的3种策略

- no表示等操作系统进行缓存同步到磁盘,速度快但是不安全,不推荐使用
- Always同步持久化,每次发生数据变更时,立刻记录到磁盘,速度慢(太小号redis性能)但是安全
- EverySec表示每秒同步一次,redis默认是EverySec,很快但是可能丢失一秒以内的数据
3、aof重写机制
当AOF文件增大到一定大小的时候redis能够调用bgrewriteaof对持久化文件进行重写。重写的对象主要是重复性的操作
- RDB和AOF持久化对比总结
- redis提供了RDB为什么还要AOF?
优化数据丢失的问题,rdb会丢失最后一次快照以后的数据,aof不会丢失超过2秒的数据(因为aof可以配置每秒备份一次)
- 如果RDB和AOF同时存在,听谁的?
听aof,因为aof数据准确率更高。
- rdb和aof优势劣势
(1)rdb适合大规模的数据恢复,对数据的完整性和一致性不高,在一定时间间隔内做一次备份,如果redis意外down机的话,就会丢失最后一次快照之后的所有操作。
(2)aof根据配置项而定(比如always、everySec)。
官方建议,两种持久化机制同时开启。如果两个同时开启,则优先使用aof。
性能建议(这里只针对单机版redis持久化做性能建议)
因为RDB文件只用作后备用途,只需要15分钟备份一次就够了,只保留”save 900 1 “这条规则。
如果Enable AOF,好处实在最恶劣的情况下只会丢失不超过两秒的数据,启动脚本较简单,值load自己的AOF文件就可以了。
减少AOF重写的频率,“auto-aof-write-min-size 64mb”太小了,如果硬盘许可,可以将它设置为5G。
如果是redis集群或者哨兵的话,建议主机关掉RDB,开启AOF,有必要的话配置一下”save 900 1”。
- 缓存穿透
缓存的基本用法(如查询接口):先在缓存当中查,如果有就返回,如果没有就去数据库查。简单示例代码如下图

缓存穿透:数据库当中没有这条数据,缓存当中也没有这条数据。
缓存穿透的解决办法:
- 缓存空对象:
以上图的代码来说假如查询一个缓存和数据库中都不存在的数据,每查询一次都会去请求数据库,为了不使它频繁查询数据库,就可以在第一次查询完数据库后,如果没查到就返回一个空对象,代码如下

2、布隆过滤器(相当于一个集合)
以上的解决办法会产生一个问题,就是redis中存在大量的空对象。使用布隆过滤器时候,如果按照ID查询,如果这个ID可能存在于布隆过滤器中,接着往下执行。绝对不存在于布隆过滤器中,就直接返回,不查询数据库。

缓存击穿:数据库当中有这条数据,缓存当中没有这条数据,原因可能是这条数据根本没有加入到缓存,或者这条数据失效了。
缓存击穿的解决办法:使用互斥锁?分布式锁?ReantreeLock?
假设有100个线程查询,如果不加锁在高并发情况下会查询100次数据库,枷加锁之后只会查询1次数据库。

- 缓存雪崩
缓存雪崩:redis宕机,或者大部分缓存在同一时间失效
雪崩的解决办法:
- 搭建redis高可用集群,目前最流行的就是cluster
- 设置不同的过期时间,不让数据在同一时间失效
官方推荐redission实现分布式锁
核心代码如下,这个代码支持redis单实例、redis哨兵、redis cluster、redis master-slave等各种部署架构,都可以给你完美实现
(1)加锁机制:
如果该客户端面对的是一个redis cluster集群,某个客户端要加锁,他首先会根据hash节点选择一台机器。仅仅只是选择一台机器!
紧接着,就会发送一段lua脚本到redis上。
如果客户端1要加锁的那个锁key不存在的话,就进行加锁。接着会执行“pexpire myLock 30000”命令,设置myLock这个锁key的生存时间是30秒。好了,到此为止,ok,加锁完成了。
(2)锁互斥机制
客户端1已经获取锁了,那么在这个时候,如果客户端2来尝试加锁,执行了同样的一段lua脚本,会咋样呢?很简单,第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在了。
所以,客户端2会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间。比如还剩15000毫秒的生存时间。此时客户端2会进入一个while循环,不停的尝试加锁。
(3)watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
(4)可重入加锁机制
那如果客户端1都已经持有了这把锁了,结果可重入的加锁会怎么样呢?执行lua,会对客户端1的加锁次数,累加1。
5)释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。其实说白了,就是每次都对myLock数据结构中的那个加锁次数减1。如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:“del myLock”命令,从redis里删除这个key。
然后呢,另外的客户端2就可以尝试完成加锁了。
(6)上述Redis分布式锁的缺点
其实上面那种方案最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
















 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











