







一文掌握Pytorch-onnx-tensorrt模型转换
pytorch转onnx
对于实际部署的需求,很多时候pytorch是不满足的,所以需要转成其他模型格式来加快推理。常用的就是onnx,onnx天然支持很多框架模型的转换,
如Pytorch,tf,darknet,caffe等。而pytorch也给我们提供了对应的接口,就是torch.onnx.export。下面具体到每一步。
首先,环境和依赖:onnx包,cuda和cudnn,我用的版本号分别是1.7.0, 10.1, 7.5.4。
我们需要提供一个pytorch的模型,然后调用torch.onnx.export,同时还需要提供另外一些参数。我们一个个来分析,一是我们要给一个dummy input,
就是随便指定一个和我们实际输入时尺寸相同的一个随机数,是Tensor类型的,然后我们要指定转换的device,即是在gpu还是cpu。
然后我们要给一个input_names和output_names,这是绑定输入和输出,当然输入和输出可能不止一个,那就根据实际的输入和输出个数来给出name列表,
如果我们指定的输入和输出名和实际的网络结构不一致的话,onnx会自动给我们设置一个名字。一般是数字字符串。
输入和输出的绑定之后,我我们们可以看到还有一个参数叫做dynamic_axes,这是做什么的呢?哦,这是指定动态输入的,为了满足我们实际推理过程中,
可能每张图片的分辨率不一样,所以允许我们给每个维度设置动态输入,这样是不是灵活多了?然后,设置完这些参数和输入,我们就可以开始转换模型了,
如果不报错就是成功了,会在当前目录下生成一个.onnx文件。

在完成onnx模型的转换后,为了验证精度是否对齐,我们可以跑一下这个模型,我们需要安装onnxruntime和onnxruntime-gpu(pip安装即可),后者是为了在gpu上运行模型,这个需要注意一些,就是两者的安装顺序可能会影响实际的运行,以至于出现一些奇怪的现象,一般先装cpu版再装gpu版。还有就是如果转换的onnxruntime的版本和推理时不一致,也可能出现问题。调用代码如下。

到这一步,模型转换成功了,精度也没问题,但是到底怎么转的,可能还有同学一头雾水,为什么要给一个dummy input等等,其实是这样的,因为我们知道pytorch模型和tf模型是不一样的,前者是动态计算图,后者是静态的,所以就会导致一个问题,对于pytorch模型,在运行之前是不知道各结点的状态和计算关系的,所以我们在转onnx的时候,需要实际地跑一下网络,得到每层和每个节点的计算图,这样才能转换模型,所以我们需要随便指定一个满足要求的输入即可。由于这种实际运行才能得到转换结果的情况,也使得pytorch转模型相对较慢,而tf则不需要,tf模型就是保存静态计算图,所以直接转就行了。
Pytorch的这种属性也会带来一些问题,就是当我们在网络中嵌入一些if选择性的语句时,不好意思,模型不会考虑这些,它只会记录下运行时走过的节点,不会根据if的实际情况来选择走哪条路,所以势必会丢弃一部分节点,而丢弃哪些则是根据我们转模型时的输入来定的,一旦指定了,后面运行onnx模型都会如此。另一个问题就是,我们在代码中有一些循环或者迭代的操作时,要注意,尤其是我们的迭代次数是根据输入不同会有变化时,也会因为这些操作导致后面的推理出现意外错误,正像前面说的,模型转换不喜欢不确定的东西,它会把这些变量dump成常量,所以会导致推理错误,这点要尤为注意(2022.3.23.注:用tensor去索引列表之类的结构,会导致tensor强制转换为python scalar,从而导致后续错误,而用tensor去索引tensor变量则不会)。有同学可能会问了,那我们在之前转换时指定的动态维度是怎么回事,不可以这样吗,这是可以的,我们可以告诉模型我们哪些维度是变化的,但是这是在网络的参数层面是这样,但是对于一些我们自己写的代码,则要注意。笔者在这里就踩过坑。
在这里给大家推荐一个onnx模型的可视化工具,我们可以可视化出转换好的模型,实际看一下,到底哪些操作是转换了的,网络结构长啥样。
点这里在网页上操作
这就是可视化的结果。
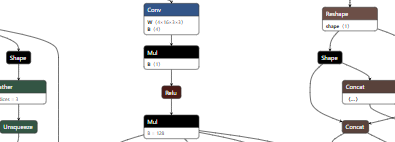
2022.4
pytorch(1.11)原生onnx接口已经支持对tensor进行inplace操作,即不能对切片对象赋值,但会出现一大堆的等效操作,如下图,后期转其他模型可能会有困难,建议应改为cat。
2021.6.24-----------------------分割线
记录一下一个转模型时的小细节,就是对Onnx模型可以进行简化,直接给工具吧,就是onnx simplier,这有个帖子讲得很清楚就是把conv和bn合在一块,以及一些计算出来是常量的模块直接折叠之类的,可以加快onnx模型推理。but,如果你需要的时tensorrt,那么可能不太需要这步,因为tensorrt也做了这些优化。
还有一个小坑,利用torch.onnx转的onnx模型在cuda10.2下不能使用Onnxruntime来推理,具体原因还不清楚,可能是opset的原因?亦或是torch的原因?有搞清楚的小伙伴可以评论一波。。
onnx转tensorrt
转换
到了第二步了,把onnx模型转成tensorrt,这里简单提下,tensorrt是经过推理优化的框架,是nvidia自家优化过的,所以很受部署端的青睐。tensorrt也支持很多框架,我们这里只讲Onnx转trt。
tensorrt模型转换需要参考nvidia给出的samples,链接如下,需要安装cuda10.2以上,cudnn8.0,然后tensorrt给了pip安装包,在python文件夹下,可直接安装。
trt转换链接
然后,我们接着讲如何转换,首先需要了解trt框架的几个对象,分别是builder, engine, network, parser,config,分别是做什么的呢,builder是构建engine的,engine就是模型,network是网络设置,parser则是解析onnx模型的工具,config则是指定一些模型的设置。我们直接上代码,方便理解。
在tensorrt给出的sample中有一个onnx_to_tensorrt脚本,里面有一个get_engine函数,这便是从Onnx模型构建trt engine的过程。下面我们详细来解析这份代码。


首先,函数的输入是两个路径,onnx和trt模型的路径,前者是必须的,后者如果不存在则构建,如果存在则直接反序列化导入。
我们一开始就会建立builder,network和parser,三者的作用前面讲了,然后我们需要设置一些参数,max_batch_size是指网络的最大batch,为什么要设定这个呢,想必于实际的优化有关,我们记得设置这个,推理的时候要保证batch小于等于设置的最大batch。
然后,这里要提一下,我在这里改动了代码,原来的代码是固定尺寸输入的,也就是我注释掉的部分代码,所以我下面也将按动态输入来讲。
接着,我们建立一个config,通过config设置最大内存占用,一般1G吧,这点是trt特有的,一切都与优化有关,在固定尺寸输入是,这个是在builder里边设置,有点不太一样。
然后我们用parser取导入并解析onnx模型,若失败会报错。接着我们建立一个profile来表示动态优化的,然后就是比较关键的一步,就是我们得设置一个动态的尺寸范围,这个在profile里边设置,并加载到config,这里要求输入三个尺寸,分别是最小的,常用的,和最大的,三者是依次增大的,不这样会报错。我们在推理时输入也要求在这个范围。
最后,我们通过builder加载network和config就构建了一个engine,而固定尺寸是不需要config的。
推理
trt模型转换成功后,我们会在本地看到一个.trt文件,然后我们可以导入解析,在导入时,需要加上这句话,初始化plugin,trt.init_libnvinfer_plugins(None, “”)。原demo中没有。
我们继续分析代码,在推理时,有一个比较关键的对象就是context,表示推理环境的上下文,我们需要在这个context下面来进行相关的推理操作。

第一步就是分配buffer memory,拿来做什么呢?是拿来存放input和output的,这个函数在common.py中,,我截图如下

这个函数主要完成这些事,给binds,binds就是绑定的输入和输出,在cpu和gpu分配一些memory,并返回内存地址。
由于我们是动态输入,所以我们每次分配的memory就是不一样的,为了避免每次都去分配,我们直接分配一个最大尺寸所需要的内存即可,所以我们的输入是max_binding_shape,在前面的代码段我们可以找到这个输入,就是我们将最大input_shape和最大的output_shape合在一起的。有同学不禁想问,最大的input_shape这个不难理解,就是我们设置的嘛,那最大output_shape呢,这个怎么计算呢,难道要实现根据网路结构来计算吗,大可不必,我们这里利用context的一个接口,get_binding_shape()即可,我们找到输出的binding号,就可在对应的最大input_shape下得到output_shape。好了,我们分配好memory后,之后就不用再分配了。
我们现在可以利用engine和分配的memory来进行前向推理了,下面这部分代码就是在做这件事,我们每次都需要指定context的input_shape,然后把img赋值给inputs的host,前面说了host是cpu,那这步就是把img放在input的memory中,然后我们就可以进行inference了。

我们继续深究,看一看inference的代码,在做那些事呢: 把cpu上的input导入gpu,在gpu上完成推理,再把gpu上的输出导出到cpu,并返回。

好了,推理也完成了,一切看似结束了,但是还差一步。细心的小伙伴会发现输出的尺寸不对啊,为什么对于不同尺寸的输入,输出都是一样的尺寸啊?
答案就是,我们得到的输出并不是合理的输出,什么意思,我们只是拿到了分配给output的那部分内存的值,而分配的内存是按最大尺寸来的,所以我们想要的输出只是其中的一部分,所以我们要根据实际的输入尺寸来决定使用output的哪一部分,还好我们之前说过,context有个可以得到实际输入尺寸的接口,我们在代码里也调用了这个接口,然后我们截取了output的一部分,在reshape成我们想要的shape,就ok了。
现在,一切才能完成。
---------------------------------------------------------------(分割线)
最近又发现一些东西:
只有我们的Onnx模型是设置为动态输入时,转出的trt才支持动态输出,但是trt的输入不一定和onnx一致,但必须固定。
就是在构造engine时,可以通过network.get_input(0).shape来设置。
另外,我们申请的内存和实际的图片不一定刚好相等,大一些也可以,因为在计算时,Tr会根据context.get_input_shape来确定真正用于计算的那部分,输出内存也是如此,但只能更大不能更小。记住一个原则,分配的内存必须比context要求的输入输出尺寸要大。
+1:yolov3转onnx时,在cfg文件中将dimension置为-1,可实现动态输入。















 2763
2763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









