







文章目录
前言
软件测试有50年的历史,自动化测试的历史也在20年以上。尽管如此,端到端的、彻底的自动化测试仍然是一个十分难以企及的梦想。
存在问题: 测试执行的自动化易(理解:测试工作的流程执行起来,可以实现自动化),测试生成的自动化难(理解:很难自动生成测试用例),测试判定(oracle)的自动化则难上加难(理解:自动实现判断,是否存在问题,很难实现。)。可以说,我们基本上仍停留在测试执行的自动化阶段。没有测试生成和测试判定的自动化,就没有端到端、彻底的自动化测试。要实现端到端、彻底的自动化测试,需要我们突破 测试生成 和 测试判定 自动化这两大瓶颈。
1.软件测试
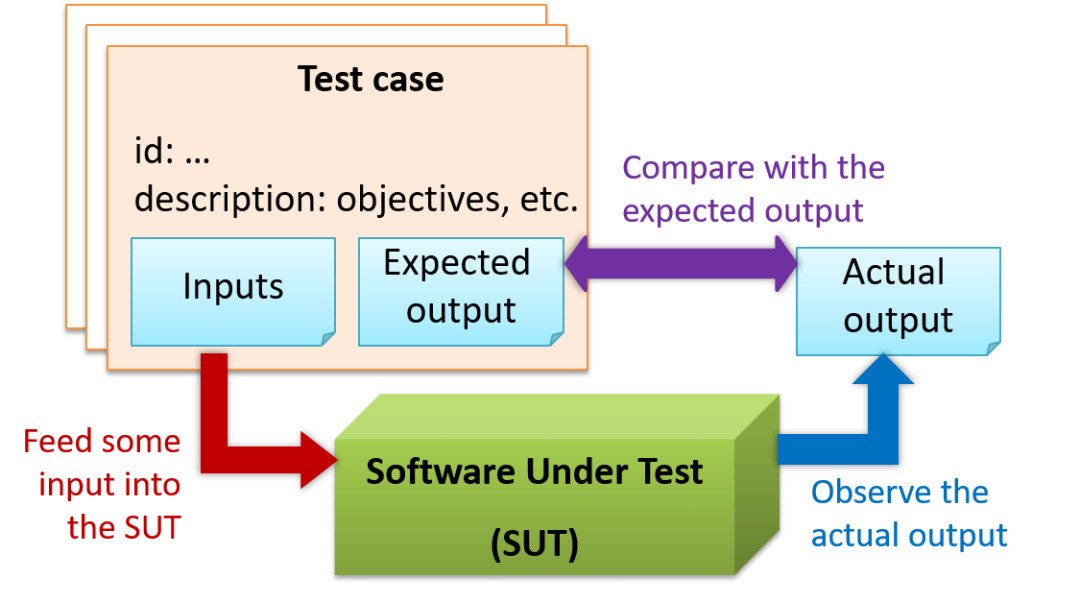
软件测试: 就是构造输入(input),并作用于被测系统(Software Under Test, SUT),然后观察其实际输出(actual output),并与期望输出(expected output)进行比较的过程。
2.随机测试
随机测试:就是用随机的方式产生 测试输入(input) 。
举几个例子:
- 当被测对象是函数时,测试输入是函数的入参,随机测试就是 随机生成入参;
- 当测试对象是API接口时,测试输入是请求消息,随机测试就是 随机生成请求消息;
- 当测试对象是用户界面时,测试输入是操作序列,随机测试就是 随机生成操作序列。
随机测试的优缺点:
优点:
- 容易实现和使用。随机测试并不需要知晓程序细节(黑盒测试),并且输入也通过随机生成。
- 对程序不存在偏见。由于随机测试的输入都是随机生成的,不存在人为因素影响,也就不会因为对程序某一部分信任而忽略掉潜在的漏洞。
- 能快速查找漏洞。随机测试的测试速度快,通过快速和大量的测试,能够在短时间内找到大量的候选漏洞(注意,对漏洞的确认还需要人工参与)。
缺点:
- 寻找漏洞的精度不高。由于随机测试的完全随机性,寻找到的漏洞很可能是一些无关紧要的错误。
- 过于随机导致对程序的代码覆盖率不高。大部分人认为对程序的测试过于依赖随机,不如通过人工白盒测试的方式来更精确地测试程序。
3.模糊测试
模糊测试产生的背景:
在1988年的一个风雨交加的夜晚,威斯康星大学的Barton Miller教授在自己的公寓中通过一条电话线连接他在学校中的计算机。暴风雨引发了电话线中的信号错乱,以至于所连接的Unix终端不断接收到糟糕的命令输入,最终导致了系统崩溃。频发的崩溃使这位讲授操作系统课程的教授感到惊讶,因此他脑海中浮现了一个对Unix系统进行鲁棒性测试的念头。于是他在给学生的课程作业中写道:
The goal of this project is to evaluate the robustness of various UNIX utility programs, given an unpredictable input stream. This project has two parts. First, you will build a fuzz generator… Second, you will take the fuzz generator and use it to attack as many UNIX utilities as possible, with the goal of trying to break them… [2]
教授在作业中要求学生开发一个模糊生成器(fuzz generator),这个生成器可以产生不可预测的输入流,然后将这些杂乱的输入给到Unix系统设施,然后试图攻陷这些设施并找到和分析引发错误的随机输入和原因。这就是模糊测试的诞生,教授在作业中使用的fuzz一词也就被用来命名这一技术。
模糊测试 在诞生之初和随机测试十分相似,都是通过 随机的输入 来对计算机程序进行功能行为测试。所以最原始的模糊测试和随机测试拥有相同的优缺点。
因此,用于发现 软件漏洞 的特殊随机测试技术叫做模糊测试。
模糊测试具有两个特点:
- 主要应用于软件安全性测试
- 提供一些随机、非法的输入去攻击软件,使得软件发生崩溃。
3.1.基于覆盖率的模糊测试(Coverage-Based Fuzzing)
对于如何提高模糊测试精度和深度的探索,其中一种是利用了 代码覆盖率(code coverage) 这一概念。
代码覆盖率包括:函数覆盖率(function coverage) 、 语句覆盖率(statement coverage) 、 边覆盖率(edge coverage) 、 条件覆盖率(condition coverage) 等多种覆盖准则,这些覆盖率都在一定程度上反映了测试用例对于程序代码的测试程度,即 代码覆盖率越高,测试用例对代码的测试程度越高。
在模糊测试中对于覆盖率的利用,主要是在 测试用例的生成过程 中。模糊器首先生成一定个数的随机输入,这些输入被称为种子(seed)。接着模糊器将这些种子输入程序,回收程序执行的结果和预先选定的覆盖率指标。接下来模糊器会根据覆盖率高低,将覆盖率低的种子丢弃,将覆盖率高的种子保留并对这些种子进行操作生成一批新种子再作为输入运行程序。重复上述过程到覆盖率不能够更进一步提高时,终止测试用例的生成。
即: 随机生成种子——输入程序——回收程序执行结果,计算覆盖率——覆盖率高的保留,低的丢弃——利用覆盖率高的种子进行某种操作重新生成种子——循环往复(当覆盖率不能进一步提高时,终止测试用例的生成)。
理解: 基于覆盖率的模糊测试,实际上是想生成一些具有较高覆盖率的种子。因为最开始是通过"随机生成"的方式产生的种子,所以种子需要和被测的软件系统进行交互,当种子满足需求、达到预定的测试覆盖率时,系统也随之完成了测试。
3.2.基于变异的模糊测试(Mutation-Based Fuzzing)
由于最初的模糊器完全靠随机生成程序输入,模糊测试很难生成出符合程序要求的合法输入,以至于很难测试到程序的核心功能,同时这也是 代码覆盖率极低 的一个原因。于是基于变异的模糊测试被提出来解决这个问题。
变异的核心思想:对现有的种子(种子可以合法也可以不合法,但大多数情况下会使用合法的种子,这样通过变异得到的种子后代质量较高)以及通过变异得到种子后代进行操作来生成测试输入。注意,具体的变异操作需要测试人员执行制定。
例如:针对一个计算机程序的一个合法的程序输入“3+0”进行变异操作,指定的变异操作(由程序员人为指定的)为:
- 随机增加某个字符
- 随机删除某个字符
- 随机替换某个字符
那么合法输入“3+0”变异之后的输入为:
- 3+ - 0 (增加了一个字符“-”)
- 3+ (删除了一个字符“0”)
- 3 / 0 (替换了一个字符,把 “+” 变成 “/”)
以上就是基于变异的模糊测试。
变异操作可以被设计为更加复杂精细的过程,例如 结合其他种子质量评估指标进行变异或者进行某种针对性变异操作 。上一小节末尾描述的将变异操作和覆盖率指标进行结合来反复对程序进行测试,这样可以很好地利用这两种方法的优势,从而增强模糊测试的有效性。著名的模糊测试工具AFL就是基于这样的思路开发的。
理解: 基于变异的模糊测试,实际上也是要生成种子。只不过通过这种方式生成的种子更具有针对性(随机测试生成的种子,盲目性太大了)。
3.3.基于搜索的模糊测试(Search-Based Fuzzing)
基于搜索的模糊测试主要依赖于搜索算法。搜索算法也被称为启发式算法(heuristic algorithm),其核心思想是通过某些程序信息来启发和引导算法执行。之所以被称为搜索算法,是因为执行这些算法可以在较大的搜索空间中比随机算法或遍历算法更高效。
理解: 模糊测试的本质,就是在不断的探索输入空间。通过测试来挖掘程序隐藏的缺陷,就是在输入空间中搜索得到特定的输入,使得该程序在运行时出现异常行为;想要满足更广的程序覆盖率,就是在输入空间中搜索到特定的输入使得让该程序运行时执行更多的程序语句。
总结
目前,虽然克服了随机测试和模糊测试诞生之初的缺陷和问题,但当下的模糊测试仍然有待提高进步,例如: 对模糊测试过程中对触发的程序错误的类型进行识别、整理和分类,以及对引发错误的根源诱因的分析 等。学界和工业界也对传统静态分析工具如符号执行技术和模糊测试技术相结合的道路在不断地探索。



















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











