







Attention机制最近几年在NLP中十分火爆,这篇文章主要是对po主在学习过程中的知识做个总结,只涉及比较浅显的概念部分,不涉及具体的数学计算。文章主要参考张俊林大神的知乎专栏:深度学习中的注意力模型(2017版)。
文章目录
简介
注意力机制最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的不同类型任务中,都很容易遇到注意力模型的身影。
发展历史
第一阶段:Attention机制与图像处理
Attention机制一开始更多的是应用于图像领域,最早也是在视觉图像领域提出来的(大约九几年)。但真正火起来是 2014 年 Google Mind 团队的论文 Recurrent Models of Visual Attention ,他们在 RNN 模型上使用了 Attention机制来进行图像分类。
2015年Kelvin Xu的一篇论文 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ,在图像描述生成中引入了Attention,文章提出了两种Attention模式,即Soft Attention 和 Hard Attention。
Soft Attention会考虑所有位置,而Hard Attention会专注于很小的区域。
两者各有优缺点: Soft Attention是参数化的,因此可导,可以被嵌入到模型中去,直接训练。梯度可以经过Attention Mechanism模块,反向传播到模型其他部分。
Hard Attention聚焦于部分区域,实现的方法是依概率采样输入端隐状态的一部分来进行计算,而不是整个encoder的隐状态。所以是一个随机的过程,需要采用蒙特卡洛采样的方法来估计模块的梯度。
目前更多的研究和应用还是更倾向于使用Soft Attention。

上图中,白色部分代表注意力随时间的变化。上面是Soft Attention,可以看到相对分散;下面是Hard Attention,可以看到比较集中。
第二阶段:Attention机制与NLP
2014年,Bahdanau 等人在论文 Neural Machine Translation by Jointly Learning to Align and Translate 中,使用Soft Attention 机制在机器翻译任务上将翻译和对齐同时进行,算是第一个将 Attention 机制应用到 NLP 领域中。

上图是将英语翻译成法语的例子,白色方块代表注意力随翻译过程的分布情况,可以看到基本呈对角线分布。举个例子,翻译‘agreement’这个词时,注意力理所应当放在这个词本身。这也证明了Attention机制的有效性。
2015年,Effective Approaches to Attention-based Neural Machine Translation 是继上一篇论文后,一篇很具代表性的论文。告诉了大家Attention在RNN中可以如何进行扩展。这篇论文对后续各种基于Attention的模型在NLP应用起到了很大的促进作用。在论文中他们提出了两种Attention机制,一种是Global Attention,一种是Local Attention。
Global Attention:
和传统的Attention model一样,所有的隐藏节点状态都被用于计算权重。不同的是在计算attention矩阵值的时候,文章提出了几种简单的扩展版本。
Local Attention:
在计算时并不是去考虑源语言端的所有词,而是根据一个预测函数,先预测当前解码时要对齐的源语言端的位置,然后通过上下文窗口,仅考虑窗口内的词。主要是为了减少Attention计算时的耗费。
2017年,Google机器翻译团队发表了Attention is all you need论文,获得了广泛关注和应用。这篇论文提出一种新型网络结构Transformer,该结构实际上是多层Self Attention堆叠,另外还提出了多头注意力(Multi-headed Attention)机制。
该论文提出的Transformer模型并行性好,又适合捕获长距离特征,未来很有可能取代RNN,因为RNN是序列型结构,并行计算能力受限。Transformer也成为GPT、BERT等预训练模型的特征提取器。
人类的视觉注意力
所以,介绍了这么多Attention机制的历史,Attention到底是什么呢?
其实Attention的思想很简单,和人类的选择性视觉注意力相似。
看下面这张图:
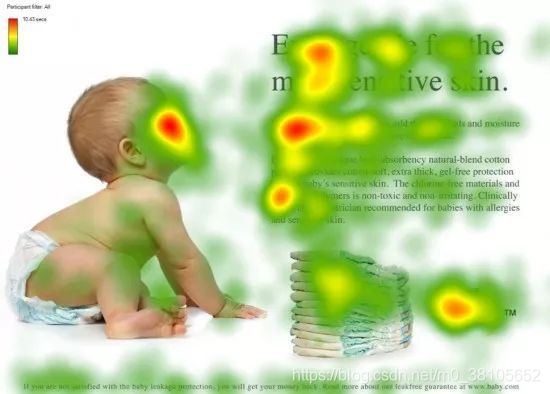
这是一个人在看这张图时的视觉注意力分布的热力图。可以看到,对于婴儿的头部、文章标题、首段落,分配的注意力明显更多。
其实Attention机制也是这个道理,核心目标也是从众多信息中选择出对当前任务目标更关键的信息,抑制其他无用信息。
Encoder-Decoder框架
介绍这个框架的原因是目前大多数注意力模型依附在Encoder-Decoder框架下,并且介绍Attention的各种文章都基于这个展开。但是Attention模型本身是一种独立的思想,要注意!(摘自大佬原话)
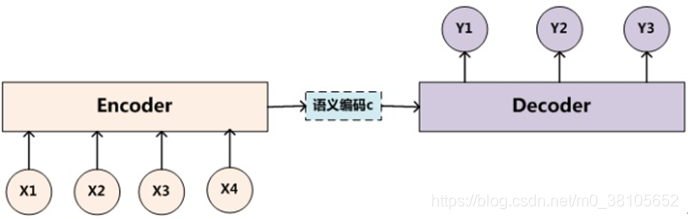
这就是Encoder-Decoder框架的结构,是一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型,是一种用于机器翻译、文本摘要、问答系统的常用框架。
假设,输入 S o u r c e = < x 1 , x 2 , x 3 , x 4 > Source=<x_1,x_2,x_3,x_4> Source=<x1,x2,x3,x4>,通过编码器Encoder就可以转换成中间语义表示 C = F ( x 1 , x 2 , x 3 , x 4 ) C=F(x_1,x_2,x_3,x_4) C=F(x1,x2,x3,x4)(这里的 F F F就是Encoder的某种非线性变换函数)。而Decoder在输出单词 y i y_i yi时,需要根据中间语义表示 C C C和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









