







总结
本系列是机器学习课程的系列课程,主要介绍机器学习中无监督算法,包括层次和密度聚类等。
参考
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合
+算法评估+持续调优+工程化接口实现
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用:
对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。

无监督算法
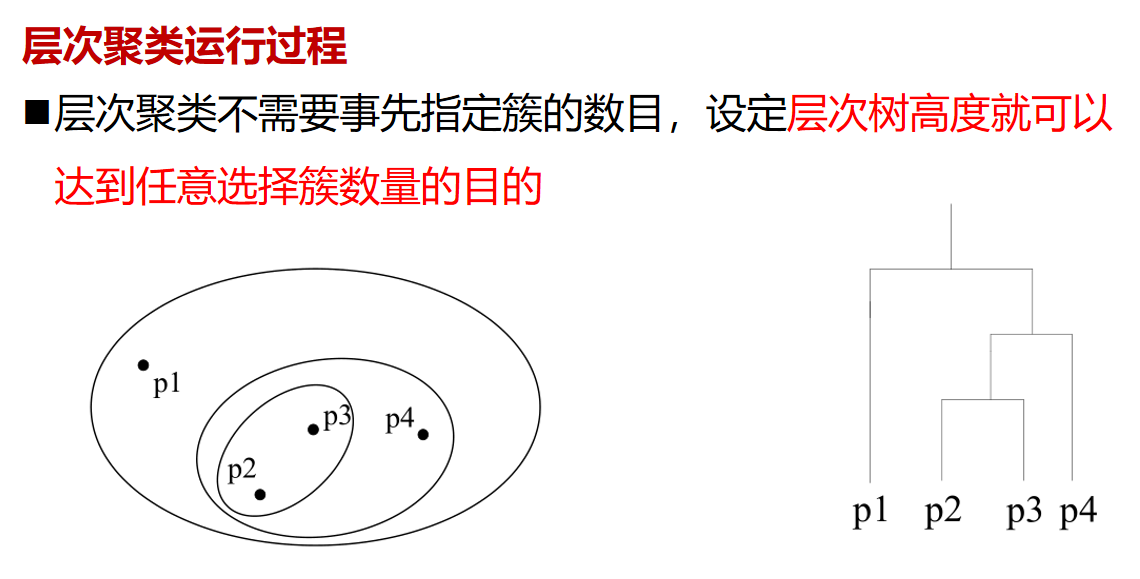
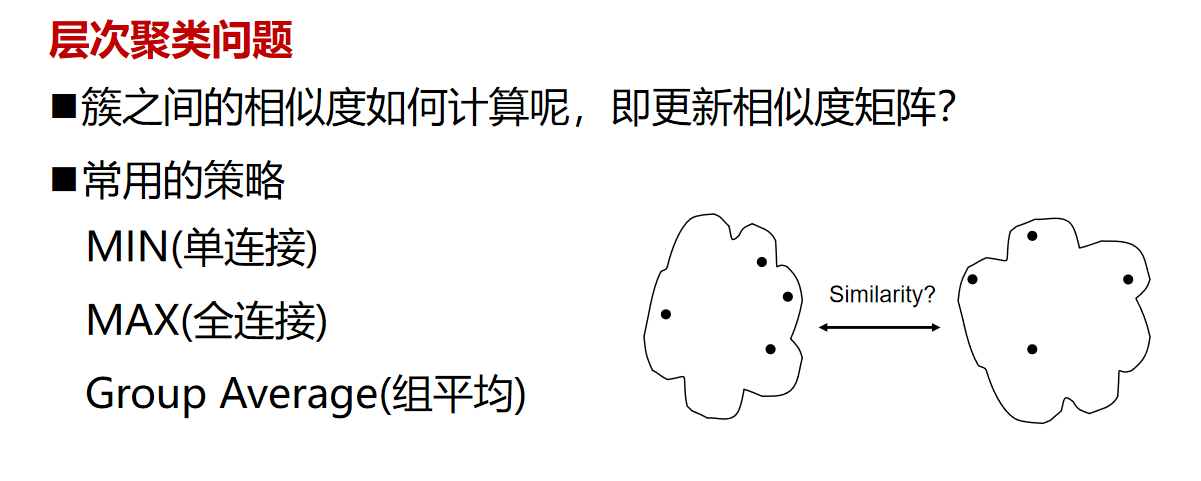
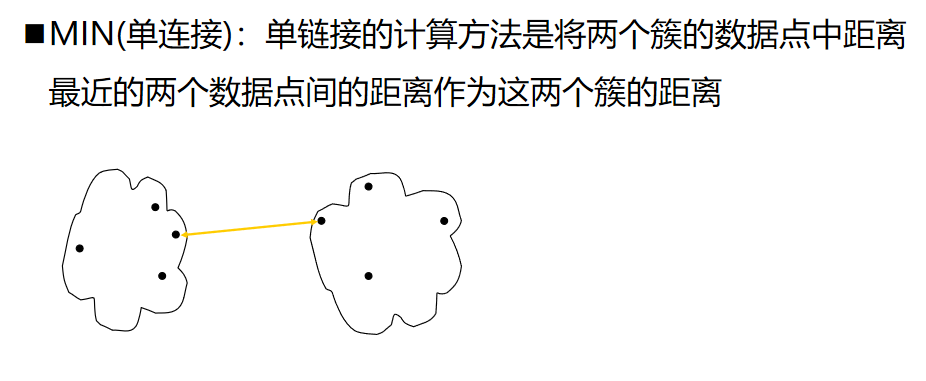
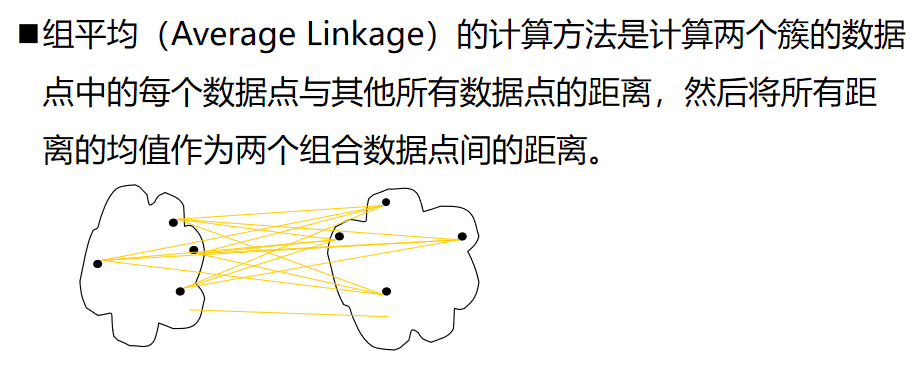
层次聚类









from scipy.cluster.hierarchy import dendrogram, ward, single
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
X = load_iris().data[:150]
linkage_matrix = ward(X)
dendrogram(linkage_matrix)
plt.show()
输出如下:
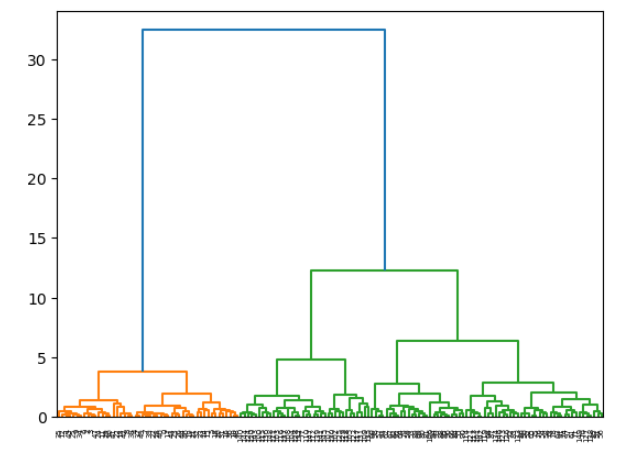
这段代码是Python脚本,用于通过Scipy和Scikit-learn库绘制层次聚类的谱系图(dendrogram)。下面是逐行解释:
from scipy.cluster.hierarchy import dendrogram, ward, single
这一行导入了Scipy库中层次聚类相关的三个函数:dendrogram用于绘制谱系图,ward用于计算ward聚类算法所需的距离矩阵,single是连接准则的一种,用于确定聚类时的距离。from sklearn.datasets import load_iris
这一行从Scikit-learn的datasets模块中导入load_iris函数,用于加载著名的Iris数据集。import matplotlib.pyplot as plt
这一行导入matplotlib的pyplot模块,并给它一个别名plt。pyplot是matplotlib库中用于绘图的一个模块。X = load_iris().data[:150]
这一行首先调用load_iris()函数加载Iris数据集,然后获取该数据集的特征数据(data),并选择前150个样本。linkage_matrix = ward(X)
这一行使用ward聚类算法对特征数据X进行聚类,并将生成的连接矩阵(linkage matrix)赋值给变量linkage_matrix。dendrogram(linkage_matrix)
这一行使用linkage_matrix作为参数调用dendrogram函数,绘制基于这个连接矩阵的谱系图。plt.show()
这一行调用plt.show()函数显示上述绘制的谱系图。
执行这段代码,会展示出Iris数据集前150个样本的层次聚类谱系图。
DBSCAN







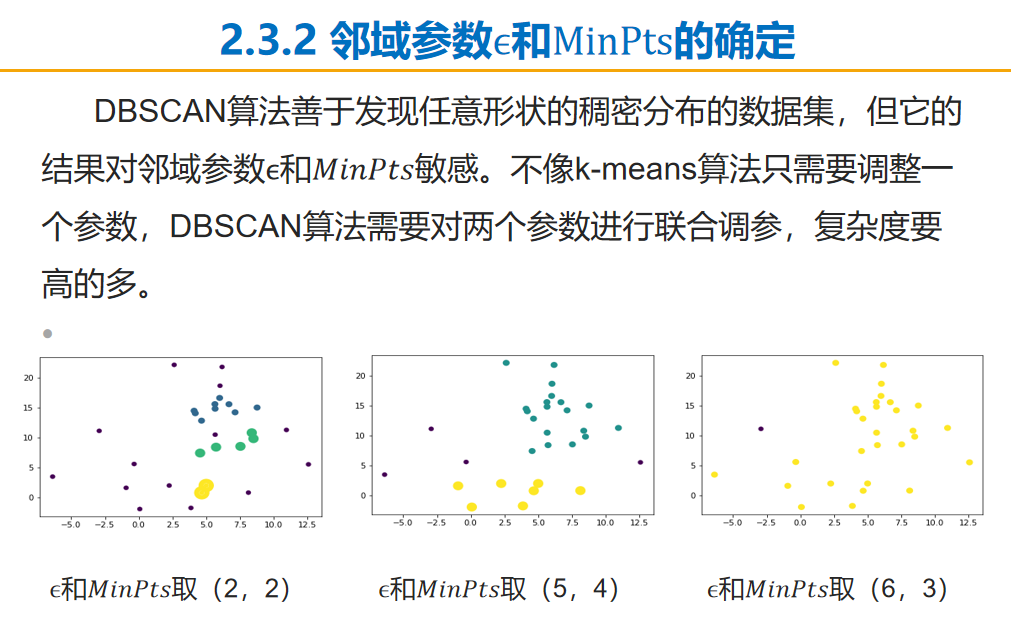



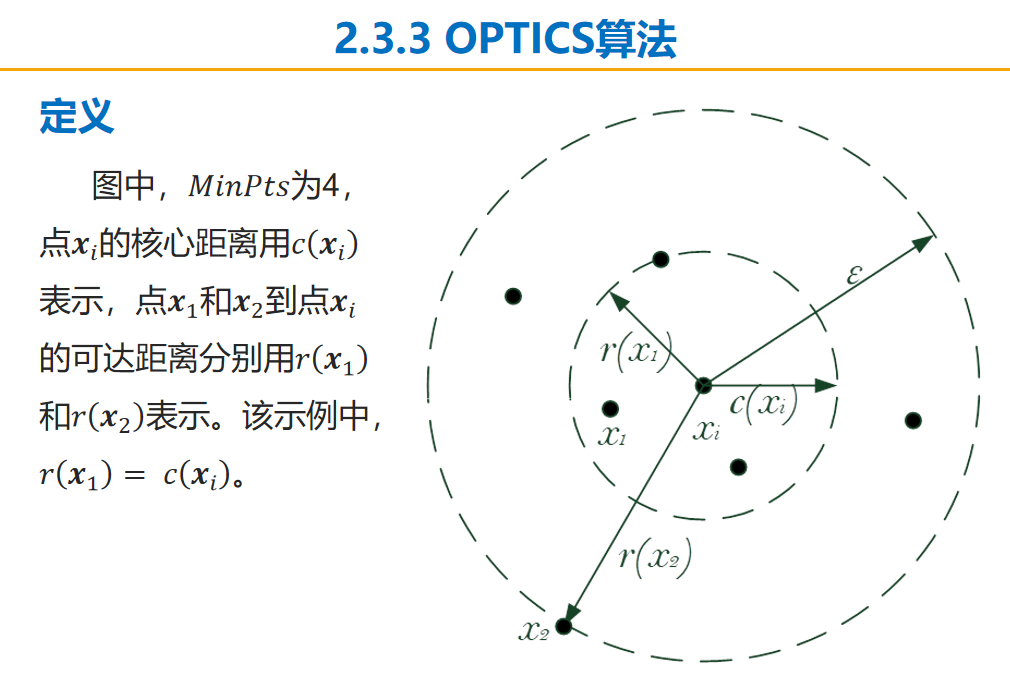
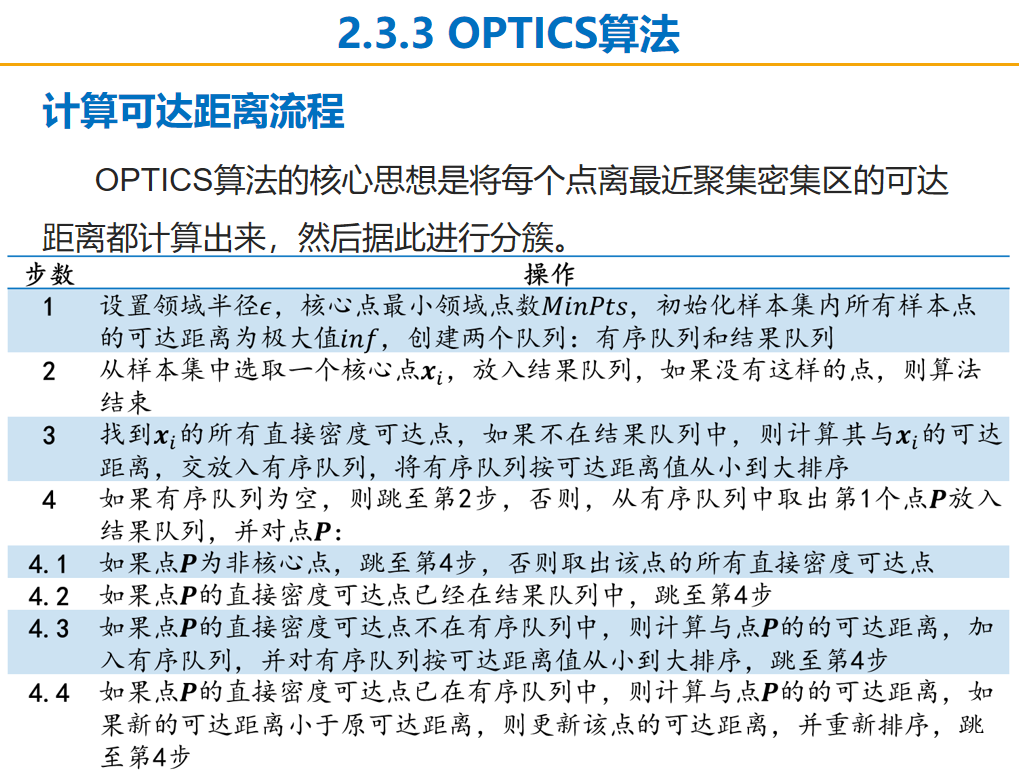

# DBSCAN clustering algorithm
print(__doc__)
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
# from sklearn.datasets.samples_generator import make_blobs
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# Compute DBSCAN
db = DBSCAN(eps=0.1, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print('Estimated number of clusters: %d' % n_clusters_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
#
import matplotlib.pyplot as plt
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
输出为:
Automatically created module for IPython interactive environment
Estimated number of clusters: 12
Homogeneity: 0.313
Completeness: 0.249
V-measure: 0.277
Adjusted Rand Index: 0.024
Adjusted Mutual Information: 0.267
Silhouette Coefficient: -0.366
这段文字似乎是描述在使用IPython交互式环境(一种广泛使用的Python交互式shell)中自动生成的模块进行聚类分析的结果。以下是每个指标的简要解释:
- Automatically created module for IPython interactive environment: 这意味着在IPython环境中自动生成并使用的某个模块(可能是用于数据分析和可视化的自定义脚本或包)。
- Estimated number of clusters: 12: 这是通过某种聚类算法(如K-means, DBSCAN等)估计的最佳聚类数量,即数据应该被分成12个不同的簇。
- Homogeneity: 0.313: 同质性指标是衡量聚类效果的一个标准,它描述了实际的簇分配与预测的簇分配的匹配程度。Homogeneity的值介于0和1之间,0.313表明聚类效果不是很好,因为不是所有数据点都被分配到它们所属的簇中。
- Completeness: 0.249: 完整性指标衡量的是所有的数据点是否都被分配到了某个簇中。Completness的值同样介于0和1之间,0.249也显示了聚类效果并不理想,因为还有很多数据点没有被分配到相应的簇中。
- V-measure: 0.277: V-measure是同质性和完整性的调和平均数,用来综合评估聚类的质量。0.277的值说明聚类结果的整体质量不高。
- Adjusted Rand Index: 0.024: 调整后的兰德指数(ARI)是一个校正后的指标,用来衡量两个聚类结果的一致性,其值介于-1和1之间,0.024是一个非常低的值,表明聚类结果与真实的簇分配相比,一致性非常差。
- Adjusted Mutual Information: 0.267: 调整后的互信息(AMI)是衡量两个聚类结果之间互信息的一个指标,通过考虑簇的大小进行校正。0.267表明聚类结果在一定程度上反映了数据的自然结构,但是这个值也不是很高,表明聚类效果仍有提升空间。
- Silhouette Coefficient: -0.366: 轮廓系数是衡量聚类质量的另一个指标,它基于样本与其自身簇内的其他样本的相似度与其他簇的不相似度之间的比值。Silhouette Coefficient的值介于-1和1之间,-0.366表明聚类效果不佳,因为值越接近1表示样本更清晰地分配在一个簇中。
综上所述,这些指标表明当前的聚类分析结果并不理想,可能需要调整聚类算法、参数或者尝试其他方法来改进聚类效果。
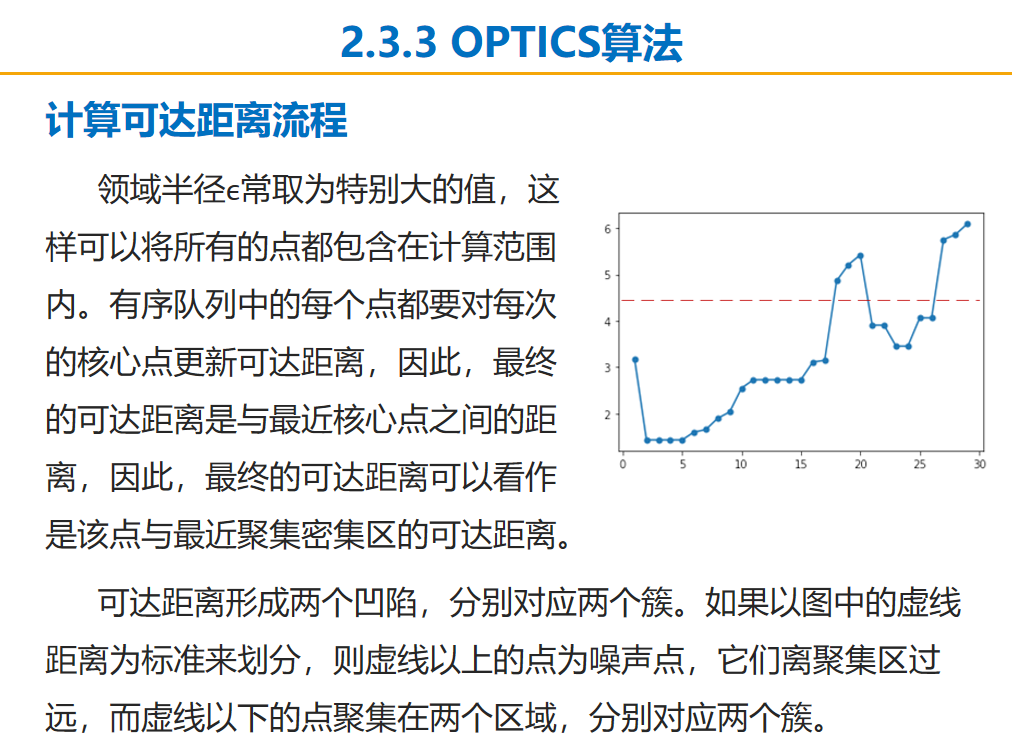
确定方向过程
针对完全没有基础的同学们
1.确定机器学习的应用领域有哪些
2.查找机器学习的算法应用有哪些
3.确定想要研究的领域极其对应的算法
4.通过招聘网站和论文等确定具体的技术
5.了解业务流程,查找数据
6.复现经典算法
7.持续优化,并尝试与对应企业人员沟通心得
8.企业给出反馈















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











