







机器学习考试方式说明
一、开课情况
考查课 082116406
70人,0864221,1-14单双周 理论学时28 实验学时14
上课地点:周三 1-2节(10#B206) 周四1-2节(10#A210/212)
二、考试方式
本学期的课程围绕机器学习的相关内容,因此采用以“机器学习”为主题的大作业作为本学期考核。
1)选题说明
大作业分为二个主题,学生任选其一:
主题一:XX领域机器学习算法应用与工程实践,如:
1.电商领域的商品推荐与用户划分实践。
2.教育领域的考研成绩预测。
主题二:竞赛类或自拟机器学习相关的题目
该类问题,不限制具体流程,流程合理,有现实意义,符合题目要求即可,如:
1.基于大模型接口的文档评分实现。
2.XX数据的时序分析。
3.CV或NLP方向的相关题目
2)大作业报告要求:
下文以选题一方向要求:
报告内容涵盖:
1.确定业务领域,并对业务领域进行说明。
2.技术算法说明,包括采用的算法和语言工具,以及同类型数据集的采用的算法(参考5篇以上的博客或文献)。
3.数据获取:体现数据的获取过程,并对数据集进行详细说明,要求数据集与业务领域吻合度较高。
4.数据处理:包含数据探索,数据预处理,特征工程等步骤
5.算法选择:依据数据集和业务,选择合适的算法,包括分类,回归,聚类,关联,图像分类,图像检测,文本翻译等。
6.模型训练:进行多个模型的训练,并生成对应的模型。
7.模型评估:选择合适的评估函数评估模型,并对结果进行分析。
8.模型优化:对比模型效果,结合集成学习,算法融合等优化模型。
9.模型保存与加载:保存模型参数,并加载模型进行测试
10.基于Flask或是其它框架,完成模型接口服务实现。
11.个人总结
12.提供完整的checklist。可参考做机器学习项目的checklist
下文以选题二方向要求:
报告内容涵盖:
1.选题概述
2.技术选型
3.数据介绍
4.功能实现
5.效果展示
6.部署文档
7.个人总结
3)报告格式要求:
(1)正文,标题参考报告模板。
(2)每个图要有标号和图名(例:图1 XXX流程图),标号和图名在图下标识。每个表要有标号和表名(例:表1 XX表),标号和表名在表上方标注。
三、考试说明
第14周为考试审核周,共留两周时间给学生完成。大作业的最终评判将参考以下标准:
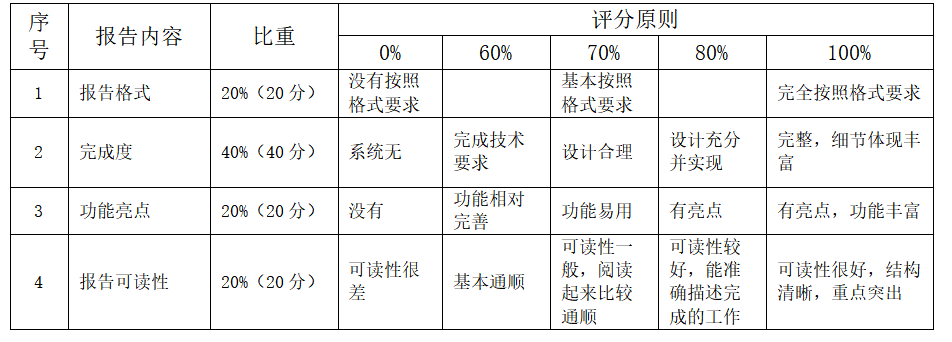
四、资料保存方式
每人上交一份电子档,同时上交一份打印档。
以下为完善的机器学习大作业考核标准(含拓展说明):
考试说明拓展说明
1. 业务领域确定(10%)
- 要求:选择金融、医疗、电商、教育等具体领域,说明行业痛点与机器学习应用价值
- 示例:电商用户流失预测、医疗影像分类、金融风控评分
- 拓展:需明确领域特征(如数据敏感性、时效性要求)与项目目标关联性
2. 技术算法说明(15%)
- 核心要求:
- 语言工具:Python(sklearn/pytorch)+ Jupyter Notebook
- 算法说明需包含:经典算法(如逻辑回归、随机森林)与前沿方法(如LightGBM、Transformer)对比
- 文献支撑:引用近3年顶会论文(CVPR/ICML等)或CSDN/Medium优质技术博客
- 拓展:需制作算法对比表格,说明各方法适用场景
3. 数据获取(10%)
- 数据要求:
- 来源标注:Kaggle/UCI等开放平台或自制爬虫(需附代码),也可以自己收集数据(如学校的学生考研数据)
- 数据量级:结构化数据>1000条,非结构化数据>500条
- 字段说明:需包含数据字典(字段名、类型、业务含义)
- 重点检查:数据与业务场景的匹配度(如金融场景需含交易特征)
4. 数据处理(15%)
- 流程规范:
- 创新点:需包含可视化分析(如Seaborn绘制的特征分布热力图)
- 特征工程要充分体现,参考:https://blog.csdn.net/m0_38139250/article/details/136828851
5. 算法选择(10%)
- 决策矩阵:
数据类型 问题类型 推荐算法 小样本 分类 SVM 高维度 回归 Lasso 时序数据 预测 LSTM
6. 模型训练(10%)
- 技术要求:
- 至少训练3种不同原理的模型
- 超参数设置需说明依据(网格搜索/贝叶斯优化)
- 保存训练日志(含loss曲线等可视化记录)
- 可视化训练日志
- 可参考:
- 机器学习-05-回归算法-python动画展示
- 机器学习-12-sklearn案例02-集成学习
7. 模型评估(10%)
- 评估体系:
- 分类:Accuracy+F1+ROC-AUC三角评估
- 回归:MAE+R²+可解释性分析
- 对比测试:在不同数据子集上的稳定性验证
- 可参考:
- 机器学习-07-分类回归和聚类算法评估函数及案例
8. 模型优化(10%)
- 进阶方法:
- 集成策略:Stacking融合(基模型需差异度>40%)
- 优化案例:XGBoost+早停机制+特征重要性筛选
- 效果验证:优化后指标提升需≥5%
- 可参考:
- 机器学习-12-sklearn案例02-集成学习
- 机器学习12-集成学习-案例
9. 模型部署(5%)
- 实现要求:
- 保存格式:.pkl或ONNX标准化格式
- 加载测试:需包含完整推理demo(输入输出样例)
- API规范:RESTful接口设计,POST请求示例
- 可参考:
- 机器学习-12-sklearn案例03-flask对外提供服务
10. 系统实现(5%)
- 技术栈:
# Flask示例核心代码 app = Flask(__name__) @app.route('/predict', methods=['POST']) def predict(): data = request.json return jsonify(model.predict(data)) - 验收标准:需提供Postman测试截图
- 可参考:
- 机器学习-12-sklearn案例03-flask对外提供服务
11. 个人总结(5%)
- 深度要求:
- 技术反思:算法选择偏差分析
- 工程思考:从实验到生产的挑战
- 改进方向:列举3个可优化维度
评分细则
- 优秀(90+):实现技术前沿性+完整可视化方案+可落地部署
- 良好(80+):流程完整+有优化过程+文档规范
- 合格(60+):基础流程完整但缺乏深度分析
- 不及格(<60):基础流程不完整或非自己完成
注意事项
- 代码重复率需<30%
- 实验数据需包含原始数据和处理后数据双版本
- 严禁直接调用AutoML工具包
该方案强化了工程实践要求,突出"数据驱动→模型优化→服务部署"的完整链路,建议配合提供的《机器学习项目checklist》文档使用。
机器学习项目的checklist
导读
这个checklist能帮助你迈出做一个成功的机器学习项目第一步。
避免混淆,用这个简单的清单来计划你的 AI 项目。
做机器学习项目的checklist

1. 项目动机
做机器学习项目的checklist
明确你的项目的更广泛的意义。
你要解决的问题是什么?What is the problem you want to solve?
相关联的目标策略是什么?
如果项目团队不理解你的动机,那么他们就很难提出好的建议。
有很多方法可以解决机器学习的问题。所以帮助你的团队以你最感兴趣的方式工作 —— 退一步告诉他们为什么这个项目是重要的。
2. 问题定义
你想要预测的具体输出是什么?
对于给定的输入,你的机器学习模型将理想地学会预测非常具体的输出。
所以这里你要尽可能的清楚。“预测机器故障”可能意味着很多事情 —— “告诉我,在未来 24 小时内,意外停机的风险何时增加 50%以上”更好。
你的算法有什么输入数据?
模型预测输出的唯一方法是从模型的输入因子中派生出来。所以,为了有机会做出好的预测,你必须有与输出相关的数据。数据越多越好。
什么是预测你的具体输出的最相关因素?
算法不能理解我们的世界。重要的是,你要给数据科学家一些提示,告诉他哪些数据实际上是相关的,这样他就可以用算法能够理解的方式选择和分割数据。
你能提供多少训练样本 ?
一个算法需要的练习比一个人要多得多。你最少需要 200 个样本。越多越好。
3. 性能度量
你怎么知道什么是好的结果?
你有一个简单的基准测试来比较你的结果吗?
有没有一种简单的方法来利用你已有的数据进行预测?也许你可以根据去年的数字预测销售额,或者通过计算客户上一次登录后的天数来评估客户离开的风险。一个简单的基准测试可以为你的团队提供有价值的问题洞察力。它给你一些东西来衡量模型。
你将如何衡量预测的准确性 ?
你期望的最低准确度是多少?你希望预测的准确率平均在 5% 以内,还是更重要的是预测误差不超过 10%?你的模型可以以任何一种方式进行调优。哪种方式更好取决于什么对你来说是重要的。
一个完美的解决方案是什么样的?
即使这对你来说是显而易见的,把它写在纸上也能帮助你理清思路。
是否有参考解决方案(如研究论文)?
如果有人以前解决过类似的问题,就把他们的解决方案当作灵感。这为每个人提供了一个共同的起点,这样他们就可以看到要使用哪些数据,可能会出现哪些问题,以及要尝试哪些算法。
4. 时间线
一个性能验证项目的时间线示例。
是否有截止日期需要注意?
你什么时候需要看到第一个结果?
你想什么时候有一个完整的解决方案?
人工智能解决方案可以无限地改进。明确的最后期限有助于让团队集中精力。
5. 联系人
谁负责项目(PM,Project Management)?
谁可以授权访问数据集?
谁能帮助理解当前的流程和/或简单的基准测试(领域专家)?在一个项目的过程中会出现许多问题。明确你的工程师可以向谁求助。
6. 合作
在业务和工程团队之间建立一个双/周的更新。
每周安排一次会议来查看当前的结果,并讨论那些不需要通过电子邮件来回答的问题。
应该涉及谁 ?
他们应该学什么?
在学习如何管理人工智能方面,没有什么比实际项目的实践经验更有价值。如果你想让你的团队的其他成员学习,从一开始就要说清楚。
定义代码和问题的位置以及如何访问代码。
让所有的开发从一开始就透明。这样任何人都可以很容易地加入,给出提示,并检查进展。
回答这个清单上的问题,并与大家分享
世界仍在研究如何最好地运行人工智能/机器学习项目。填写这份清单将会给你所有成功的机器学习项目的要素之一:理解。


















 8339
8339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











