






 本文介绍了如何使用pandarallel库来并行处理pandas的map和apply操作,以提高数据处理速度。通过pip安装pandarallel并在Windows的Linux子系统上运行,设置内存大小和CPU核心数,然后使用parallel_apply和parallel_map替代原有的pandas函数。实例如何使用pandarallel进行数据处理,并展示了并行计算相比于串行计算的时间优势。
本文介绍了如何使用pandarallel库来并行处理pandas的map和apply操作,以提高数据处理速度。通过pip安装pandarallel并在Windows的Linux子系统上运行,设置内存大小和CPU核心数,然后使用parallel_apply和parallel_map替代原有的pandas函数。实例如何使用pandarallel进行数据处理,并展示了并行计算相比于串行计算的时间优势。
使用pandarallel 对数据进行并行处理,加速 pandas中的map,apply。
pandas做数据分析很好用,map、apply使用的也比较多,非常的耗时间。虽然map性能优于apply,但是在处理大量数据的时候处理速度依然很慢。下面介绍几个加速map,apply的方法。
一、pandarallel 包(多进程)并行加速
1、安装pandarallel
pip install pandarallel
对于windows用户,有一个不好的消息是,它只能在Windows的linux子系统上运行(WSL),你可以在微软官网上找到安装教程:
https://docs.microsoft.com/zh-cn/windows/wsl/about
2、使用pandarallel
1、导入包
from pandarallel import pandarallel
2、初始化
初始化函数为 pandarallel.initialize(shm_size_mb,nb_workers,progress_bar)
参数:
shm_size_mb:是给pandarallel的内存空间分配的大小
nb_workers:设置使用多少个CPU的核数
progress_bar:设置是否显示每个CPU的进度条

# 查看计算机cpu核数
import multiprocessing
cup_num = multiprocessing.cpu_count()
print(f"计算机cpu核数:{cup_num}")
pandarallel.initialize(nb_workers=nb_workers,progress_bar=True) # 初始化该这个b...并行库
4、使用方法
pandas 中的替换
apply替换parallel_apply
map替换parallel_map

样例:
import time
import pandas as pd
import numpy as np
import multiprocessing
cup_num = multiprocessing.cpu_count()
print(f"计算机cup核数:{cup_num}")
from pandarallel import pandarallel # 导入pandaralle
pandarallel.initialize(nb_workers=cup_num-2,progress_bar=True) # 初始化该这个b...并行库
# 调用的函数
def func(x):
import math
return math.sin(x.a**2) + math.sin(x.b**2)
df_size = int(5e6)
if __name__ == '__main__':
# 需要在
time_start = time.time()
df = pd.DataFrame(dict(a=np.random.randint(1, 8, df_size),
b=np.random.rand(df_size)))
res_parallel = df.parallel_apply(func, axis=1)
time_end = time.time()
print("并行代码耗时 %f s" % (time_end - time_start))
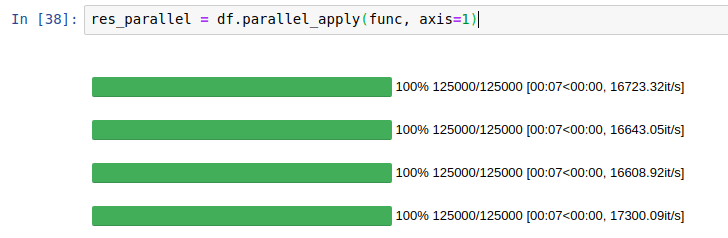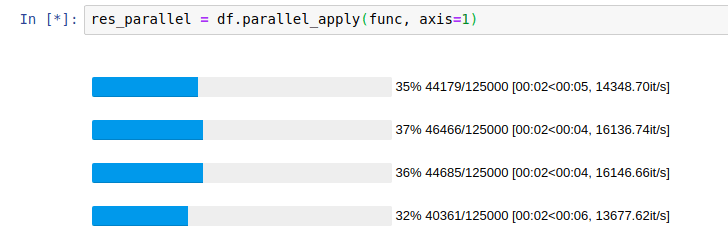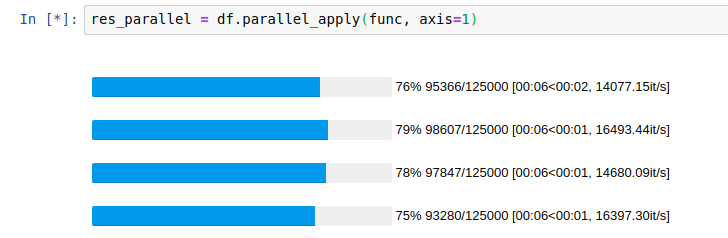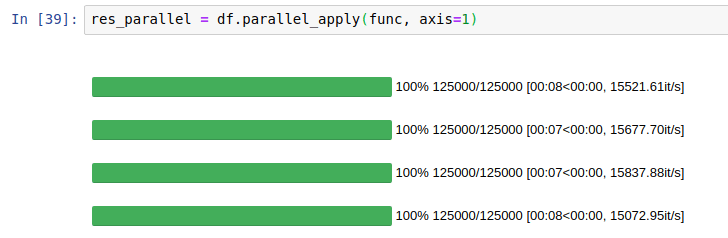
效果:
使用pandarallel并行计算
不使用pandarallel并行计算

参考
https://blog.csdn.net/u010751000/article/details/121391796
https://blog.csdn.net/weixin_45631815/article/details/124085118

















 2429
2429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









