







 本文利用时间序列分析方法对1969-2018年中国社会消费品零售总额进行分析和预测,建立ARIMA模型,对未来几年的零售总额做出预测。模型检验显示较好的拟合效果,有助于理解零售市场变化趋势。
本文利用时间序列分析方法对1969-2018年中国社会消费品零售总额进行分析和预测,建立ARIMA模型,对未来几年的零售总额做出预测。模型检验显示较好的拟合效果,有助于理解零售市场变化趋势。
摘 要
社会消费品零售总额是指企业通过交易售给个人、社会集团,非生产、非经营用的实物商品金额,以及提供餐饮服务所取得的收入金额。社会消费品零售总额是表现国内消费需求最直接的数据。社会消费品零售总额是国民经济各行业直接售给城乡居民和社会集团的消费品总额。它是反映各行业通过多种商品流通渠道向居民和社会集团供应的生活消费品总量,是研究国内零售市场变动情况、反映经济景气程度的重要指标。本文以我国社会品零售总额的预测为背景,利用时间序列分析对我国1969-2018年社会消费品零售总额建立AMIMA模型,较好的刻画序列变化趋势,并利用该模型对未来几年的社会消费品零售总额做出预测。最后通过预测的数据发现该模型有较好的拟合效果。
关键词:时间序列分析;社会消费品总额;预测;
Abstract
Total retail sales of social consumer goods refer to the amount of physical goods sold to individuals and social groups by enterprises through transactions, which are not used for production or operation, and the amount of income obtained by providing catering services. The total retail sales of social consumer goods is the most direct data of domestic consumer demand. Total retail sales of social consumer goods is the total amount of consumer goods sold directly to urban and rural residents and social groups in various industries of the national economy. It reflects the total amount of consumer goods that various industries supply to residents and social groups through various commodity circulation channels. It is an important indicator to study the changes of domestic retail market and reflect the economic prosperity. Based on the prediction of the total retail sales of social goods in China, this paper uses time series analysis to establish ARIMA model for the total retail sales of social consumer goods in China from 1969 to 2018, which can better describe the change trend of the series, and use this model to predict the total retail sales of social consumer goods in the next few years. Finally, through the predicted data, it is found that the model has a good fitting effect.
Keywords: Time series analysis; total amount of social consumer goods; prediction
目录
1 引言
1.1选题背景
社会消费品零售总额是指各种经济类型的批发零售贸易业、餐饮业、制造业和其他行业对城乡居民和社会集团的消费品零售额和农民对非农业居民零售额的总和。它反映了一定时期内人民物质文化生活水平的提高情况,反映了社会商品购买了的实现程度,以及零售市场的规模状况。它是由社会商品供给和有支付能力的商品需求的规模所决定,是研究国民生活水平、社会零售商品购买了、社会生产、货币流通和无价的发展变化趋势的重要资料。
预测[1]是人们根据事物之间的相互联系,事物发展的历史数据及相关信息,利用己经掌握的科学知识和手段,对客观事物的未来发展状况或趋势进行事前分析和推断的科学与艺术。预测的科学性在于,它有科学基础,包括理论、资料、方法、计算等因素,依赖于对客观经济规律的认识和掌握。预测的艺术特征在于,它依赖于预测者提出假设、选择方法、利用资料的技巧和运用自己的学识、经验、 获得的情报进行判断的能力。预测的目的在于为制定计划或进行决策提供客观依据。事物是发展变化的,其结果具有不确定性,与人们的生产活动密切相连。
我国是一个经济大国,经济一直保持平稳较快增长,城乡居民收入越来越乐观,消费品需求旺盛,人们生活水平逐年上升。其中社会消费品零售总额是反映人民生活水平的提高的一个很好的指标。所以对社会消费品零售总额做分析预测就比较重要。本文利用时间序列分析方法对我国社会消费品零售总额进行分析和预测。时间序列分析是根据动态数据揭示系统动态结构的规律的统计方法。其基本思想是根据系统的有限长度的运行记录(观察数据), 建立能够比较准确地反映时间序列中所包含的动态依存关系的数学模型,并借以对系统的未来行为进行预报。
1.2国内外关于时间序列相关研究
1.2.1国外相关研究
时间系列分析[2]方法最先起源于1927年英国统计学家(G. U. Yule)建立的自回归(AR)模型,在此基础上,数学家(G. T. Walker)在同一年发现了移动平均(MA)模型,同时在1931年首先创造了自回归移动平均(ARMA)模型,进一步奠定了时间序列分析方法的基础。20 世纪70年代初,全称为差分自回归移动平均模型(Autoregressive Integrated Moving Average Model, 简记ARIMA)的 ARIMA模型,是由Box和Jenkins在随机理论的基础上提出的著名时间序列预测方法,同时使时间序列分析理论又上升了一个新高度。下面是关于时间序列在应用中的研究。
对于季节性时间序列,为了消除原始序列的季节性因素,美国普查局
(U. s. Census Bureau) 所提出的X-12方法及其变种被采用的次数较多,也有采用德国联邦统计局(Federal Sta. tistleal 0fice) 提出的BV4方法。
为了进一步改进时间序列两端的不对称性,加拿大统计局在X-12方法的基础上进行了改进,最终提出了 X-12-ARIMA方法。换种说法就是在采用X-12方法前,先使用ARIMA模型对时间序列的两端进行了延伸。
在韩国,韩国政府在对韩国的经济时间序列进行季节调整时发现,X-12-ARINA方法仅仅考虑西方国家的节假日因素,而对于韩国的少许特定节假日因素不能精准地分离,造成对经济时间序列研究分析的误差。所以,为了反映韩国的特殊节假日因素,引人了哑元(dummy variables). 在X-12-ARIMA方法的基础上,开发出了拥有韩国风格的季节调整程序B0K-X-12-ARIMA,并将其应用在韩国的GDP序列的季节调整。
1.2.2国内相关研究
近年来我国学者对于时间序列的研究取得了极其丰硕的成果,主要体现在基础理论研究的不断加强(某些领域已经达到了国际前沿水平,而不再只是纯粹的吸收引进国外的先进成果) ;应用领域的不断拓展,在应用中求创新求发展,在部分应用领域中我们已经跟上了国际步伐。
汤家豪教授将有关非线性时间序列分析的研究与动力系统科学的模型连接而备受赞赏。现在他着眼于非参数时间序列模型的发展,并与生态学家进行大量的合作研究。
姚琦伟教授基于信息量,首次提出了描述一般随机系统对初始条件敏感性的度量及估计方法。在高维模型领域,姚琦伟教授提出用复系数线性模型近似高维非线性回归函数的新方法,以此克服高维非参数回归中样本量短缺的困难问题。此方法在生物、经济、金融等应用中获得了成功。在时间序列.模型的最大似然估计方法的研究中,他完整地建立了在金融风险管理中有直接应用的ARCH和GARCH模型为最大似然估计的极限理论。对于重尾部(heavy-tailed) 分布模型,提出了基于boostrap的新的估计方法以及稳健统计方法。他还首次建立了在空间域,上空间ARMA过程的最大似然估计理论,这一工作同时也对Hannan1973年给出的关于时间序列的最大似然估计理论首次给出了一个完整的时域_上的证明。
安鸿志、朱力行、陈敏关于非线性自回归模型的平稳性、遍历性和高阶矩的成果,获得了有这些性质的最弱条件。关于回归或自回归的非线性检验问题,具有重要的实际意义。他们首次给出了完全对立的假设检验方法,无论从原理和应用都表明此方法有明显优点。他们研究了条件方差为非常数的回归和自回归模型的平稳性、遍历性和检验方法。
2.模型介绍
随机时间序列分析模型分为三种类型:自回归模型(Auto-regressive model, AR)、
移动平均模型(Moving Average model, MA)和自回归移动平均模型(Auto-regressive Moving model, ARMA)。ARIMA模型全称是差分自回归移动平均模型,简记为ARIMA,是由博克思和詹金斯与70年代初提出的一个著名时间的序列预测方法,所以又称为box- jenkins模型、博克思-詹金斯法。其中ARIMA(p, d, q)称为差分自回归移动平均模型,AR是自回归,p为自回归项;MA是移动平均,q为移动平均项,d是时间序列成为平稳是的差分次数。所谓ARIMA模型,是指将非平稳的时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。ARIMA模型根据原序列是否平稳以及回归中所含部分的不同,包括自回归过程(AR)、移动平均过程(MA)、自回归移动平均过程(ARMA)以及ARIMA过程。
(一)自回归模型AR
如果时间序列{}满足:
其中:是独立同分布的随机变量序列,并且对于任意的t,E(
)=0,
,则称时间序列{
}服从p阶自回归模型,记为AR(P)。
(二)移动平均模型MA
如果时间序列{}满足:
则称时间序列{}服从q阶移动平均模型,记为MA(q),
是q阶移动平均模型的系数。
(三)自回归移动平均模型ARMA
如果时间序列{}满足:
此模型是模型AR(p)与模型MA(q)的组合形式,记作ARMA(p, q)。
(四)ARIMA(p, d, q)模型
ARIMA模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。这个模型一旦被识别后就可以从时间序列的过去值及现在值来预测未来值。
(五)ARIMA模型的具体步骤
1.观察时间序列。根据时间序的散点图自相关函数(ACF)图和偏自相关函(PACF)图以及ADF单位根检验观察其方差、趋势及其季节性变化规律,识别该序列的平稳性。
2.对序列进行平稳化处理。如果数据序列是非平稳的,并存在一定的增长或下降趋势,则需对数据进行差分处理;如果数据序列存在异方差性,则需对数据进行对数转换或者开方处理,直到处理后数据的自相关函数值和偏相关函数值无显著地异于零。
3.模型识别。若平稳时间序列的偏相关函数是截尾的,而自相关函数是拖尾的,则可断定此序列适合AR模型; 若平稳时间序列的偏相关函数是拖尾的,而自相关函数是截尾的,则可断定此序列适合MA模型; 若平稳时间序列的偏相关函数和自相关函数均是拖尾的,则此序列适合ARMA模型。
4.对ARIMA(p, d, q)模型定阶,估计参数。
5.模型检验。进行假设检验,诊断白噪声检验假设模型残差的ACF值和PACF值在早期或季节性延迟点处不得大于置信区间,同时残差应理想化为0 均值。 可观察残差的ACF图、PACF图,并辅以D-w值、t值等检验法。
6.预测分析。时间序列分析包括以下步骤:分析时间序列的随机特性;用实际统计序列构造预测模型;根据所得模型做出最佳的预测值。
3. 实证分析
3.1 数据来源
本文选自1969-2017年的每年的社会消费品零售总额数据,总计49观测值,数据全部来源于国家统计局官网。利用1969年到2017年的数据作为时间序列分析的数据,建立模型对2018年、2019年的数据做出预测,并判断模型的预测方面的准确性。数据如表3.1所示:
表3.1中国1997-2018社会消费品零售总额 单位:亿元
| 年份 | 1969 | 1970 | 1971 | 1972 | 1973 | 1974 | 1975 |
| 总额 | 801.5 | 858 | 929.2 | 1023.3 | 1106.7 | 1163.6 | 1271.1 |
| 年份 | 1976 | 1977 | 1978 | 1979 | 1980 | 1981 | 1982 |
| 总额 | 1339.4 | 1432.8 | 1558.6 | 1800 | 2140 | 2350 | 2570 |
| 年份 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 |
| 总额 | 2849.4 | 3376.4 | 4305 | 4950 | 5820 | 7440 | 8101.4 |
| 年份 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 |
| 总额 | 8300.1 | 9415.6 | 10993.7 | 14270.4 | 18622.9 | 23613.8 | 28360.2 |
| 年份 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 |
| 总额 | 31252.9 | 33378.1 | 35647.9 | 39105.7 | 43055.4 | 48135.9 | 52516.3 |
| 年份 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 |
| 总额 | 59501 | 68352.6 | 79145.2 | 93571.6 | 114830.1 | 133048.2 | 158008 |
| 年份 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 |
| 总额 | 187205.8 | 214432.7 | 242842.8 | 271896.1 | 300930.8 | 332316.3 | 366261.6 |
3.2 模型建立
3.2.1数据录入
打开 Eviews 软件,将从事先准备好的数据导入到Eviews软件中,如下图3-1所示:
图3-1 实验数据
3.2.2时序图判断平稳性
做出该序列的时序图 3-2,看出该序列呈指数上升趋势,直观来看,显著非平稳。
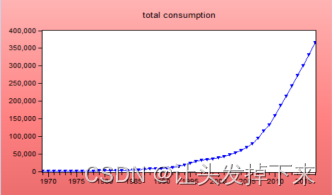
图3-2 全国社会消费品零售总额时序图
3.2.3原始数据的对数处理
因为数据有指数上升趋势,为了减小波动,对其对数化,在 Eviews 命令框中输入相应的 命令“series y=log(total_consumption)”就得到对数序列,其时序图见图 3-3,对数化后的序列远没有原始 序列波动剧烈:

图3-3 对数社会消费品零售总额时序图
从图上仍然直观看出序列不平稳,进一步考察其自相关图和偏自相关图 3-4:
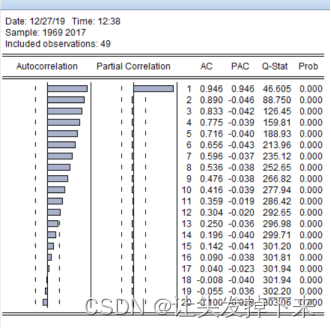
图 3-4 对数序列 y 自相关图
从自相关系数可以看出,衰减到零的速度非常缓慢,所以断定 y 序列非平稳。为了证实这个结论,进一步对其做 ADF 检验,结果见图 3-5,可以看出在显著性水平 0.05 下,接受存在一个单位根的原假设,进一步验证了原序列不平稳。为了找出其非平稳的阶数,需要对其一阶差分序列和二阶差分序列等进行 ADF 检验。

图 3-5 序列 y 的 ADF 检验结果
3.2.4差分次数 d 的确定
y 序列显著非平稳,现对其一阶差分序列进行 ADF 检验,在图 3-6 中的对话框中选择 “ difference”,检验结果见图 3-7,可以看出在显著性水平 0.05 下显著拒绝存在单位根的原假设,说明一阶差分序列是平稳的,因此 d=1。
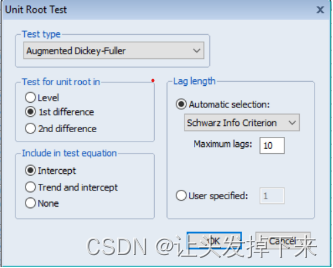
图 3-6
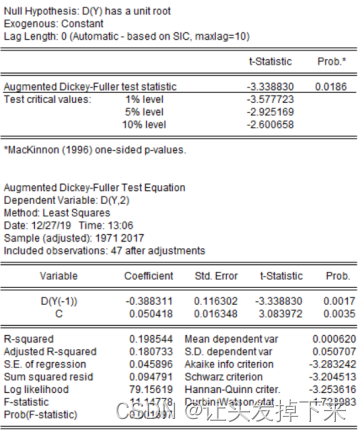
图 3-7 一阶差分序列平稳性检验
3.2.5建立一阶差分序列
在 Eviews 对话框中输入“series z=y-y(-1)”,便得到了经过一阶差分处理后的新序列 z,其时序图见图 3-8,从直观上来看,序列 z也是平稳的,这就可以对 z 序列进行模型分析了。
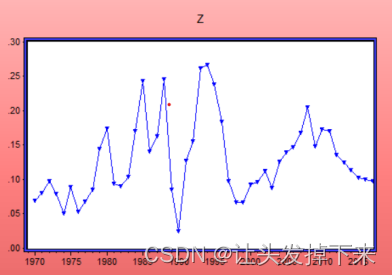
图 3-8 z序列时序图
3.2.6模型的识别
做平稳序列 z的自相关图 3-9:
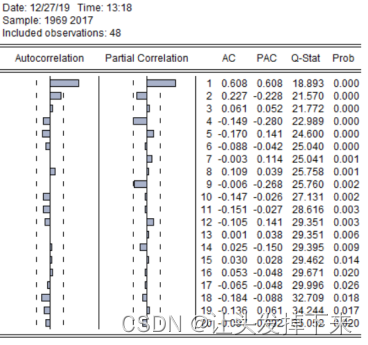
图 3-9 z的自相关-偏自相关图
从 z的自相关函数图和偏自相关函数图中我们可以看到,偏自相关系数在 k=4 后在两倍的标准差内,即 4 阶截尾,尝试拟合 AR(4);自相关系数在 k=1 处显著不为 0,当 k=2 时在 2 倍标准差的置信带边缘,又因为由图3-7可知,序列平稳,因此可以对模型进行参数估计。
3.2.7 模型参数估计
尝试 ARIMA 模型 由模型定阶发现,p 可能等于1,q 可能等于2 ,我们根据各种组合来选择最优模型,经过进一步筛选,逐步剔除不显著的滞后项或移动平均项,最后得到如下 ARIMA(1,1,2)模型:在主窗口命令栏输入 ls z AR(1) MA(1) MA(2),按回车,即得到参数估计结果见图 3-10:
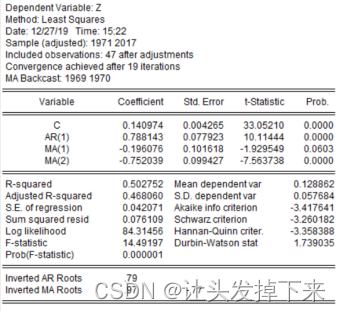
3.3 模型检验
参数估计后,应对拟合模型的适应性进行检验,实质是对模型残差序列进行白噪声检 验。若残差序列不是白噪声,说明还有一些重要信息没被提取,应重新设定模型。可以对残 差进行纯随机性检验,也可用针对残差的 2 x 检验。 通常有两种方法进行 2 x检验。当一个模型估计完毕之后,会自动生成一个对象 resid, 它便是估计模型的残差序列值,对其进行相关图分析便可看出检验结果;另一种方法是在方程输出窗口中点击 View/Residual Tests/Correlogram-Q-Statistics,输入相应的滞后阶数 20,即出现残差的相关图 3-11,相关图显示,残差为白噪声,也显示拟合模型有效,模型拟合图见图 3-12。
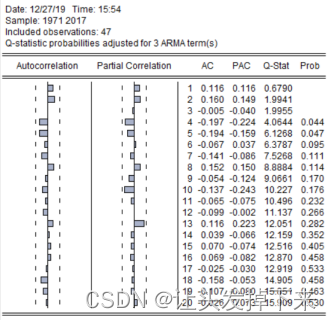
图3-11 残差的自相关-偏自相关图
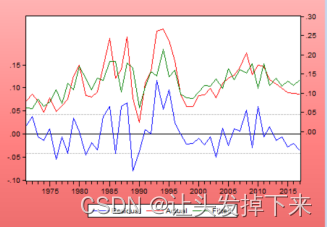
图 3-12 模型拟合图
3.4 模型预测
点击“Forecast”,会弹出如图3-13所示的窗口。在Eviews中有两种预测方式:“Dynamic” 和“Static”,前者是根据所选择的一定的估计区间,进行多步向前预测;后者是只滚动的进 行向前一步预测,即每预测一次,用真实值代替预测值,加入到估计区间,再进行向前一步 预测。我们选择Static forecast,结果见图 3-14:
图3-13
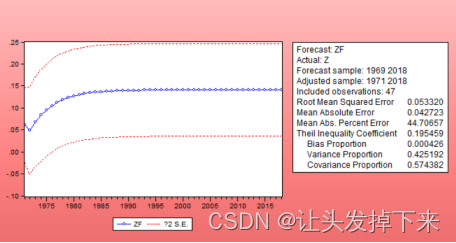
图3-14
图中实线代表的是 z 的预测值,两条虚线则提供了 2 倍标准差的置信区间。可以看到, 随着预测时间的增长,预测值很快趋向于序列的均值(接近 0)。图的右边列出的是评价预 测的一些标准,如平均预测误差平方和的平方根(RMSE),Theil 不相等系数及其分解。可 以看到,Theil 不相等系数为 0.195,表明模型的预测能力不太好,而对它的分解表明偏误 比例很小,方差比例较大,说明实际序列的波动较大,而模拟序列的波动较小,这可能是由 于预测时间过长。 下面我们再利用“Static”方法来预测,得到如图 3-15 所示的结果。从图中可以看到, “Static”方法得到的预测值波动性要大;同时,方差比例的下降也表明较好的模拟了实际序列的波动 ,Theil 不相等系数为 0.1475,其中协方差比例为 0.73,表明模型的预测结果较理想。
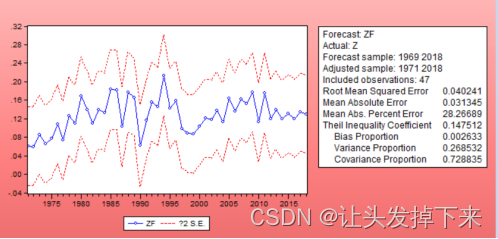
图3-15
综合上述分析过程,实际上我们是针对原序列(EX):1969年-2017年我国数额会消费品零售总额数据序列,建立了一个 ARIMA(1, 1, 2)模型进行拟合,模型形式如下:
根据最终模型,未来几年,全国社会消费品零售总额稳定增长。
小结
在解决一个问题的时候,确定一个合理的模型和方法对解决问题有很大的帮助,这次研究利用ARIMA模型和EVIEWS软件,对全国消费品零售总额时间序列进行预测分析。对于对大规模指数型增长数据根据均值得到的最后预测数据误差很大,需要对对数、差分处理后的平稳性时间序列的预测数据进行还原。
随着人们对实际问题的讨论越来越精确,使得在实际预测工作中,采用时变参数模型和自适应预测技术的时间序列方法称为必然,出于研究不同变量间动态关系的需要以及计算机硬件的发展,多元模型在向量ARIMA 模型中或在状态空间模型中应用也会日益增加。
参考文献
[1]徐国祥.统计预测与决策[M].上海:上海财经大学出版社,2008.11:23-25.
[2] Anderson T. W.,The Statistical Analysis of Time Series [M]. New York: John Wiley & Sons, 1971: 3-5
[3] Don M. Miller, Dan Williams. Damping seasonal factors: Shrinkage estimators for the X-12 ARIMA program [J]. International Journal of Forecasting, 2004, 21(3): 204-210
[4]张利. 基于时间序列ARIMA模型的分析预测算法研究及系统实现[D]. 江苏大学,2008.


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











