






一、案例背景
在图像分类任务中,需要将图像准确地划分到不同的类别中。例如,在一个自然场景图像分类系统中,要区分图像是森林、海滩、城市街道还是山脉等类别;或者在一个工业产品检测场景中,要判断产品图像是否存在缺陷以及缺陷的类型。HOG 算法作为一种有效的特征描述符,在这些图像分类任务中发挥着重要作用。
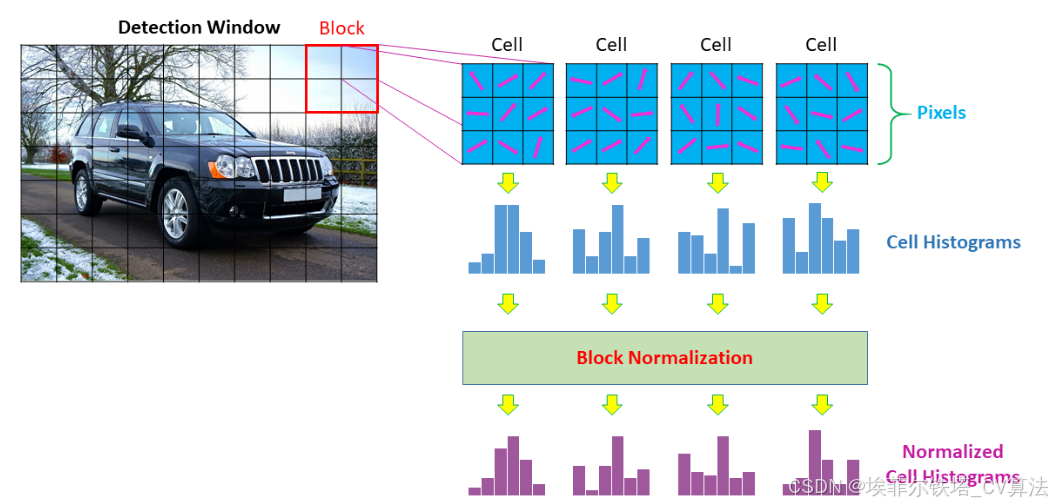
二、数据集介绍
- Caltech 101 数据集
- 这是一个常用的图像分类数据集,包含 101 个不同的类别,如飞机、人脸、汽车等,大约有 9000 多幅图像。图像的尺寸和内容复杂度各不相同,有简单的物体图像,也有包含多个物体的复杂场景图像。
- 对于 HOG 算法应用来说,这个数据集的多样性可以很好地测试算法在不同类别图像上的特征提取和分类能力。例如,在对动物类别(如狮子、大象等)进行分类时,HOG 算法可以提取动物的轮廓和纹理特征来区分不同种类的动物;在对人造物体(如汽车、飞机等)分类时,它可以捕捉物体的形状和部件特征。
- MNIST 数据集(手写数字图像)
- 包含 0 - 9 的手写数字图像,训练集有 60000 幅图像,测试集有 10000 幅图像。图像是 28×28 的灰度图像。
- 尽管图像内容相对简单(只有手写数字),但 HOG 算法在这个数据集上仍然有很好的应用价值。它可以通过提取数字笔画的方向和边缘特征来进行数字分类。例如,数字 “1” 主要是垂直方向的笔画,HOG 算法可以很好地捕捉这种方向特征;数字 “8” 具有复杂的环形结构,HOG 算法可以提取其边缘和内部纹理特征来与其他数字区分开。
三、应用过程
(一)图像预处理
- 灰度化
- 对于 Caltech 101 和 MNIST 数据集的彩色图像(Caltech 101 中有彩色图像),首先进行灰度化处理。以 RGB 彩色图像为例,通过加权平均法(如
)将其转换为灰度图像。这样做的目的是简化后续的计算,因为 HOG 算法主要是基于灰度图像的梯度信息进行特征提取的。
- 对于 Caltech 101 和 MNIST 数据集的彩色图像(Caltech 101 中有彩色图像),首先进行灰度化处理。以 RGB 彩色图像为例,通过加权平均法(如
- 归一化
- 采用伽马校正对图像进行归一化。例如,对于 MNIST 手写数字图像,通过调整伽马值(如
)来减少光照变化对特征提取的影响。伽马校正公式为
,其中
是原始图像像素值,
是校正后的像素值。在 Caltech 101 数据集的应用中,这种归一化可以使不同光照条件下拍摄的同类别图像具有更相似的特征表示,提高分类的准确性。
- 采用伽马校正对图像进行归一化。例如,对于 MNIST 手写数字图像,通过调整伽马值(如
(二)特征提取
- 梯度计算
- 使用 Sobel 算子计算图像的梯度幅值和梯度方向。对于一个像素点,Sobel 算子在水平方向(
)和垂直方向(
)的计算公式分别为:
- 其中*表示卷积运算,I(x,y)是图像在(x,y)处的像素值。梯度幅值
,梯度方向
。
- 在 MNIST 数据集上,通过这种方式可以清晰地获取手写数字笔画的边缘方向和强度特征。例如,数字 “7” 的斜向笔画边缘会有明显的梯度方向变化,这些梯度信息可以被 HOG 算法用于特征提取。在 Caltech 101 数据集的物体图像中,如汽车的轮廓边缘和表面纹理变化也可以通过梯度计算来捕捉。
- 使用 Sobel 算子计算图像的梯度幅值和梯度方向。对于一个像素点,Sobel 算子在水平方向(
- 细胞单元划分和直方图统计
- 将图像划分为多个细胞单元,以 8×8 像素的细胞单元为例。在每个细胞单元内,统计梯度方向直方图。将梯度方向划分为 9 个 bins,范围是 0° - 180°。
- 对于 MNIST 数字图像,在每个细胞单元内,数字笔画的梯度方向会被统计到相应的 bins 中。例如,垂直方向的笔画梯度会较多地统计到 0° 或 180° 附近的 bins 中。在 Caltech 101 数据集的图像中,物体的边缘和纹理梯度信息也在细胞单元内进行统计,如树叶的纹理方向和树枝的轮廓方向等。
- 块划分与归一化
- 采用 2×2 个细胞单元组成一个块,对每个块内的特征向量进行 L2 - 范数归一化。例如,对于一个块内的特征向量
(假设每个细胞单元有一个 4 - 维特征向量),L2 - 范数归一化公式为
,其中
。
- 这种归一化在 MNIST 数据集上可以使不同数字书写风格下的数字特征具有可比性。在 Caltech 101 数据集上,它可以增强特征对光照和对比度变化的鲁棒性,使得在不同拍摄条件下的同类别物体图像具有相似的特征表示。
- 采用 2×2 个细胞单元组成一个块,对每个块内的特征向量进行 L2 - 范数归一化。例如,对于一个块内的特征向量
- 特征向量生成
- 将所有块的归一化特征向量串联起来,形成最终的 HOG 特征向量。例如,在一个小尺寸的 MNIST 数字图像中,经过上述步骤可能会生成一个几百维的 HOG 特征向量;在 Caltech 101 数据集的较大尺寸图像中,特征向量的维度可能会更高。
(三)分类模型构建与训练
- 分类器选择
- 采用支持向量机(SVM)作为分类器。SVM 在处理高维特征空间(如 HOG 特征向量构成的空间)时有很好的性能,并且能够有效地进行线性和非线性分类。
- 训练过程
- 将提取的 HOG 特征向量和对应的图像类别标签作为训练数据输入到 SVM 中。对于 MNIST 数据集,将手写数字的 HOG 特征向量和其对应的数字标签(0 - 9)进行训练;对于 Caltech 101 数据集,将每个图像的 HOG 特征向量和其所属的 101 个类别标签进行训练。
- 通过调整 SVM 的参数,如核函数(线性核、多项式核或高斯核等)和惩罚参数,来优化分类模型的性能。例如,在 MNIST 数据集训练中,可能会发现线性核函数在简单的数字分类任务中就有很好的效果;而在 Caltech 101 数据集的复杂类别分类中,高斯核函数可能更适合捕捉不同类别图像之间的复杂边界关系。
(四)分类结果评估
- 评估指标选择
- 采用准确率(Accuracy)作为主要评估指标。准确率的计算公式为:

- 对于 MNIST 数据集,通过将测试集图像的 HOG 特征向量输入到训练好的 SVM 分类器中,计算正确分类的手写数字图像数量与测试集总图像数量的比例,得到准确率。在 Caltech 101 数据集上,同样对测试集图像进行分类并计算准确率,以评估 HOG 算法在复杂图像分类任务中的性能。
- 采用准确率(Accuracy)作为主要评估指标。准确率的计算公式为:
- 结果展示
- 在 MNIST 数据集上,使用 HOG 算法结合 SVM 分类器可以达到较高的准确率,例如达到 95% 以上的准确率。这表明 HOG 算法能够有效地提取手写数字的特征,使得 SVM 能够准确地区分不同数字。
- 在 Caltech 101 数据集上,准确率可能会因类别复杂程度和图像多样性而有所不同。对于一些容易区分的类别(如飞机和汽车),准确率可能较高;而对于一些相似类别(如不同种类的花卉),准确率可能会稍低。但总体而言,HOG 算法能够提供有价值的特征信息,帮助 SVM 进行有效的分类,准确率可以达到 70% - 80% 左右(具体准确率会因参数调整和数据预处理等因素而变化)。
四、HOG 算法在图像分类中的优势和劣势
优势
- 对几何和光学形变的不变性:HOG 算法是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。例如在行人检测中,只要行人大体上能够保持直立的姿势,一些细微的肢体动作可以被忽略而不影响检测效果126.
- 有效捕捉局部形状信息:通过计算图像局部区域的梯度方向直方图来构成特征,能够很好地描述物体的轮廓和形状信息,对于刚性物体的特征提取具有良好的特性,可用于各种需要对物体形状进行识别和分类的任务,如行人检测、车辆识别等126.
- 对光照变化的鲁棒性:在计算 HOG 特征时,先对图像进行色彩和伽马归一化等预处理,减少光照因素的影响。并且在构建块描述符时进行归一化处理,进一步对光照、阴影等进行压缩,使得该算法对光照变化具有一定的鲁棒性,能够在不同光照条件下较好地提取特征235.
- 特征描述能力强:HOG 特征结合 SVM 分类器等机器学习算法,在图像识别中表现出色,能够提供较为准确的分类结果,被广泛应用于多种图像分类任务中,并取得了较好的效果247.
劣势
- 无旋转和尺度不变性:HOG 算法本身不具有旋转不变性和尺度不变性,对于图像的旋转和尺度变化比较敏感。虽然可以通过采用不同旋转方向的训练样本或改变检测图像的尺寸等方法来实现一定程度的旋转和尺度不变性,但这增加了计算复杂度和数据量.
- 特征维度大:HOG 特征向量的维度相对较高,例如对于 63x128 像素的图片,其特征维度可能有 3780 个,这导致在存储和计算时需要较大的空间和时间开销,尤其在处理大规模图像数据时,会影响算法的效率和实时性.
- 计算量大:计算图像梯度、构建方向直方图以及进行归一化等操作,使得 HOG 算法的计算复杂度较高,处理速度较慢,实时性较差,难以满足对实时性要求较高的应用场景,如实时视频监控中的目标检测等.
- 难以处理遮挡问题:当目标物体被部分遮挡时,HOG 算法难以准确地提取和描述物体的特征,从而导致分类性能下降,例如在行人检测中,如果行人被其他物体遮挡一部分,可能会出现漏检或误检的情况.
- 对噪点敏感:由于梯度的性质,HOG 描述子对噪点相当敏感,图像中的噪点可能会干扰梯度的计算和直方图的构建,影响特征的准确性和稳定性,进而降低图像分类的性能.
针对以上计算量大,速度慢,有以下解决方法:
- 优化梯度计算方法
- 采用快速梯度算子:传统的 Sobel 算子等在计算梯度时需要进行卷积运算,计算量较大。可以采用一些更高效的梯度算子近似方法。例如,有限差分法来近似计算梯度,这种方法通过简单的像素差值计算来估计梯度,减少了卷积运算的时间开销。
- 减少梯度计算的精度:在对精度要求不是极高的场景下,可以适当降低梯度计算的精度。例如,将梯度幅值和方向的计算结果进行量化,使用较低的数据类型(如从 32 位浮点数转换为 16 位整数)来存储和处理梯度信息,从而加快计算速度,同时在一定程度上保留特征的有效性。
- 改进分块和细胞单元策略
- 增大细胞单元和块的尺寸:适当增大细胞单元和块的尺寸可以减少计算量。例如,将传统的 8×8 像素的细胞单元增大到 16×16 像素,相应地减少了需要处理的细胞单元数量。不过,这可能会在一定程度上损失特征的细节信息,需要在速度和精度之间进行权衡。
- 采用稀疏分块策略:设计一种稀疏的块划分方式,即不是对整个图像进行密集的块划分,而是有选择性地在可能包含目标物体的区域或者具有丰富纹理的区域进行块划分和特征提取。通过这种方式,可以避免在背景等无关区域浪费计算资源。
- 利用并行计算技术
- GPU 加速:利用图形处理器(GPU)的并行计算能力来加速 HOG 算法的计算。GPU 具有大量的计算核心,可以同时处理多个像素的梯度计算、直方图统计等操作。例如,将图像划分成多个子区域,每个子区域的梯度计算和特征提取任务分配到 GPU 的不同线程中进行并行处理,从而显著提高计算速度。
- 多核 CPU 并行计算:对于多核 CPU 系统,采用多线程编程技术来并行计算。例如,将图像按行或按列划分为多个部分,每个部分的 HOG 特征计算分配到不同的 CPU 核心上,通过并行执行来缩短计算时间。
- 特征降维技术
- 主成分分析(PCA):对提取的 HOG 特征向量应用 PCA 技术进行降维。PCA 可以找到数据中的主要成分,将高维的 HOG 特征向量投影到低维空间,在减少特征维度的同时尽可能保留特征的主要信息。这样在后续的分类或检测任务中,可以减少计算量,提高算法的运行速度。
- 线性判别分析(LDA):LDA 是一种有监督的降维方法,它可以根据类别标签信息来寻找最优的投影方向,使得不同类别之间的特征区分度最大。通过 LDA 降维后的 HOG 特征不仅可以降低计算复杂度,还可能提高分类的准确性。
- 预计算和缓存策略
- 梯度预计算:如果图像数据集的部分内容是固定或者变化不大的(如在视频监控中,背景区域在短时间内基本不变),可以预先计算这些区域的梯度信息并缓存起来。在后续的处理中,直接使用缓存的梯度信息,减少重复计算。
- 特征缓存:对于已经计算过的图像块或细胞单元的特征,将其缓存。当再次需要这些特征时(例如在滑动窗口检测中,相邻窗口可能有部分重叠区域),直接从缓存中获取,避免重新计算,从而提高计算效率。
五、代码分析
以下是一个使用 HOG 算法结合 SVM 进行图像分类的完整案例代码,包括训练和预测两个部分2:
import os
import cv2
import numpy as np
from skimage.feature import hog
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
### 函数:从图像数据集中提取HOG特征和标签
def extract_features_labels(dataset_path):
features = []
labels = []
for class_folder in os.listdir(dataset_path):
class_path = os.path.join(dataset_path, class_folder)
if os.path.isdir(class_path):
label = class_folder
for image_file in os.listdir(class_path):
image_path = os.path.join(class_path, image_file)
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
hog_features = hog(image, orientations=9, pixels_per_cell=(8, 8), cells_per_block=(3, 3), block_norm='L2-Hys')
features.append(hog_features)
labels.append(label)
return np.array(features), np.array(labels)
### 数据集路径
dataset_path = 'your_dataset_path'
### 提取特征和标签
X, y = extract_features_labels(dataset_path)
### 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
### 创建并训练SVM分类器
svm_classifier = SVC(kernel='linear', C=1.0, probability=True)
svm_classifier.fit(X_train, y_train)
### 在测试集上进行预测
y_pred = svm_classifier.predict(X_test)
### 评估分类器性能
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
print(classification_report(y_test, y_pred))
上述代码的详细解释如下:
extract_features_labels函数:用于从给定的数据集路径中读取图像数据,并提取每张图像的 HOG 特征以及对应的标签。它遍历数据集中的每个类别文件夹,读取其中的图像文件,计算 HOG 特征,并将特征和标签分别存储到features和labels列表中,最后返回为numpy数组。- 划分训练集和测试集:使用
train_test_split函数将提取到的特征和标签划分为训练集和测试集,其中测试集占总数据集的 20%,随机种子设置为 42,以确保每次划分的结果一致。 - 创建并训练 SVM 分类器:创建一个线性核的 SVM 分类器,设置惩罚参数
C为 1.0,并启用概率估计。然后使用训练集数据对分类器进行训练。 - 预测和评估:使用训练好的 SVM 分类器对测试集数据进行预测,并通过计算准确率和打印分类报告来评估分类器的性能,其中准确率表示预测正确的样本占总测试样本的比例,分类报告则更详细地展示了每个类别的精确率、召回率、F1 值等指标。
以下是另一个基于 HOG 特征和 SVM 的图像分类的 Python 代码示例,重点展示了如何对单个图像进行分类预测:
import cv2
import numpy as np
from skimage.feature import hog
from sklearn.svm import SVC
### 加载训练好的SVM模型
svm_model = SVC(kernel='linear', C=1.0, probability=True)
svm_model.load('trained_svm_model.joblib')
### 读取待分类的图像
image_path = 'path_to_your_image.jpg'
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
### 提取图像的HOG特征
hog_features = hog(image, orientations=9, pixels_per_cell=(8, 8), cells_per_block=(3, 3), block_norm='L2-Hys')
### 进行分类预测
predicted_label = svm_model.predict([hog_features])[0]
print("Predicted label:", predicted_label)
这段代码的关键步骤解释如下:
- 首先加载之前训练好的 SVM 模型,这里假设模型已经保存为
trained_svm_model.joblib文件,可以使用joblib库的load函数进行加载。 - 读取待分类的图像,并将其转换为灰度图。然后按照与训练时相同的参数设置,提取该图像的 HOG 特征。
- 最后使用加载的 SVM 模型对提取的 HOG 特征进行预测,得到图像的分类标签,并打印输出。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









