






 本文分享了作者使用矩池云平台租用GPU进行大规模数据集卷积神经网络训练的经验,详细介绍了从注册账号到利用GPU进行模型训练的全过程,并对比了GPU与CPU训练效率。
本文分享了作者使用矩池云平台租用GPU进行大规模数据集卷积神经网络训练的经验,详细介绍了从注册账号到利用GPU进行模型训练的全过程,并对比了GPU与CPU训练效率。
刚入门机器学习,跟着一些博主训练了几个卷积神经网络,使用的比较小的数据集,但在CPU训练神经网络的速度可以说是龟速,一个3000多张图片的数据集都要训练十几分钟。
最近我也把自己毕业设计需要的数据集制作完成了,训练集图片数量大概有13w张,验证集差不多2w张,用CPU训练根本是不可实现的。除了更换GPU显卡,我还在网上了解到可以在云平台上租用GPU来训练自己的神经网络,经过几天的摸索,终于掌握了其中一个云平台的使用方法,特来分享。
一、云平台的选取与注册
通过网上查找,现在使用比较多的云平台主要有Google Colab,MistGPU,矩池云等等,矩池云是国内的云平台,而且操作相对简单,所以我选择了矩池云。其链接如下:矩池云官网。注册的时候可以选择填写邀请码,双方都可以得到118元大礼包,大家开心的话就可以填写我的邀请码:PMl2Q2ZUmiYxeJd。
注册完成后进入个人首页如下图所示:

左侧就是各种功能,以及网盘等等。那如何租用机器呢,可以看到上图我的机器后面有启动新机器,进入租赁机器的页面,选择左侧GPU行列,那个默认的NGPU是多块GPU共同训练,我还没用过这个,选择需要租赁的机器。

选择合适的机器,点击红框部分就可以租用相应的机器了。由于矩池云的机器数量有限,有时可能没有机器可以租,全部都是灰色的,可能是机器都被租完了,一般可以等待一会,或者在早上或晚上租用机器,这个时段用的人少一些。

选择合适的镜像,如果你的代码是来自于GitHub,那么上传者一般会说明cuda版本,Pytorch或者TensorFlow版本等信息,如果不知道选择什么,就选择python3.7_多框架,里面一般什么都有。然后点击立即租赁。一般需要等待数十秒,机器才能启动,启动完成后,即如下图所示。

如图即租赁完成,可以看到有两个链接,一个是SSH链接,一个是JupyterLab链接,简单理解就是链接远程主机的,在JupyterLab中可以直接运行相关代码,进行训练操作等。但是我觉得在JupyterLab中进行操作,可视化也不是很好,而且可能由于网络原因,不能稳定地进行长期训练,就选择了使用SSH链接的方法。
二、如何远程链接并登录矩池云
我们通常使用的IDE是Pycharm,而Pycharm是可以通过SSH链接远程登录矩池云的。我在网上查找方法并按照步骤进行时,进行到最后一步,无论怎么操作,总是找不到文件,而且操作步骤也略微复杂,有兴趣的伙伴可以看一下这个方法进行操作,也可以分享你的经验。这篇博文清晰的介绍了这个方法,可惜我一直成功不了:
Pycharm使用SSH链接远程连接矩池云的方法
我在矩池云助手那里了解到,矩池云对Pycharm2019.2以及2019.3推出了插件,利用插件可以很快,很方便地连接矩池云。如果你的Pycharm不是这两个版本的,或许你只能学习下上面的方法。下面介绍插件的下载以及导入:
点击下载Pycharm矩池云内侧插件
接下来打开你的IDE,File-Settings-Plugins,点击设置小图标,选择Install Plugin from Disk,选择你刚刚下载的mp-connect-tool.zip文件,点击确定,随后重启你的IDE即可,如图所示:

重启你的IDE后,如果插件安装成功, 可以在右下角看到你刚刚安装好的插件,点击即可登录,登录的用户名和密码就是你注册时使用的用户名以及密码,我已经登录完成如图所示:

可以看到我刚刚在矩池云租用的机器,选择连接,此时就已经连接完成了。
三、利用矩池云租用的GPU训练一个具体的卷积神经网络并与CPU训练进行对比
首先我们要明白,我们所做的任何训练,包括文件的读取与保存都是在云端进行的,所以我们第一步需要做的,就是先向矩池云的云盘中传入我们的代码以及数据集。
step1:上传文件并进行压缩包解压
一般来说,你的代码和数据集都是存在本地的,如图所示,我是这样安排的。
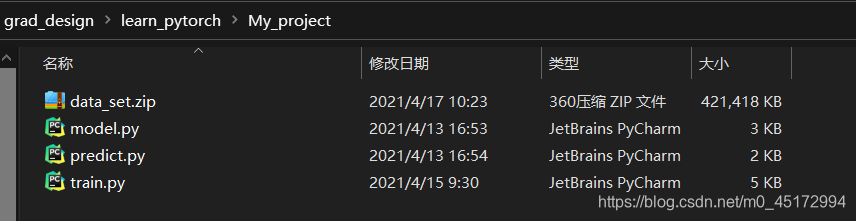
可以看到,我这个工程的名字是My_project,里面包含数据集的压缩包以及模型,训练以及预测脚本。因为连接了云服务器以后,本地的文件会自动同步到云,所以这里建议在向云盘上传文件时,工程也命名为My_project,以避免不必要的麻烦。
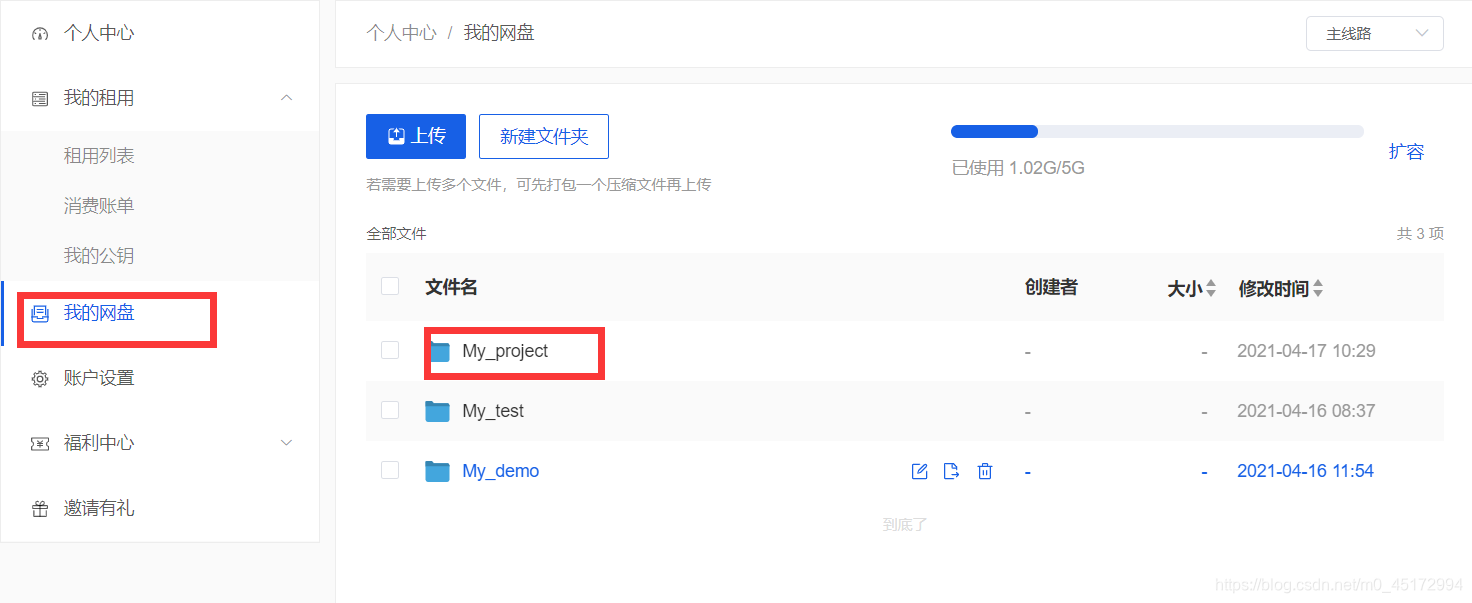
如上图,进入矩池云,点击左侧我的网盘,建立一个同名文件件,然后进入文件夹,将刚刚的三个脚本以及压缩文件传至该文件夹中。
上传完成后,需要对压缩文件进行解压。在网盘里面是无法解压文件的,对矩池云而言,需要进入JupyterLab进行文件的解压。进入JupyterLab的地址在你的租用列表的第二个地址,直接使用浏览器就可以打开。
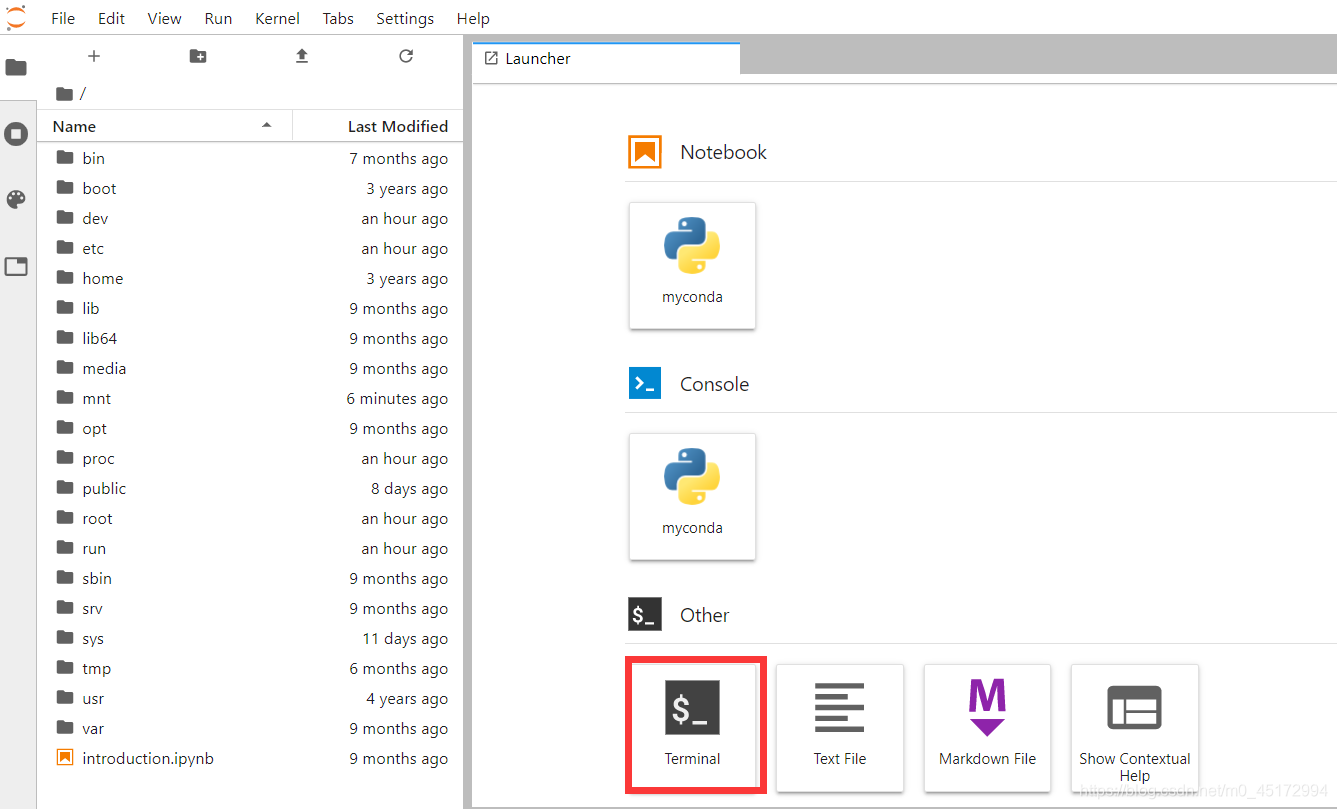
进入Terminal,这个就好比我们平时进入的命令窗口,输入相应指令就可以进行解压操作。矩池云网盘默认我的保存文件路径为/mnt,你可以在JupyterLab的左侧点击mnt文件夹,确认里面是否有你刚刚传入的文件。下面我以我的路径为例,来解压缩data_set.zip压缩文件。输入以下命令:
cd /mnt/My_project
然后输入:
ls
就可以显示该文件目录下的所有文件,如果你的压缩文件是zip文件,此时就可以输入:
unzip data_set.zip
整体如图所示,然后就开始解压了。

解压完成后,就可以在当前目录看到一个文件夹了。当然,我们在平时所用到的压缩文件格式不止zip一种,如果是RAR/tar.gz/gz这些压缩包的用户,命令如下:
gz解压
gzip -d file.gz
tar.gz解压
tar -xzvf myetc.tar.gz
rar解压
apt-get update
apt-get install rar unrar
unrar x test.rar
step2:连接云服务器进行神经网络的训练
由于我们所需要的数据集都已经上传至云盘,我建议将本子的数据集压缩包删除,因为等会连接远程服务器的时候,本地文件都会自动上传至云盘,如果数据集压缩包在目录内,也会上传,会导致软件卡顿,影响学习。
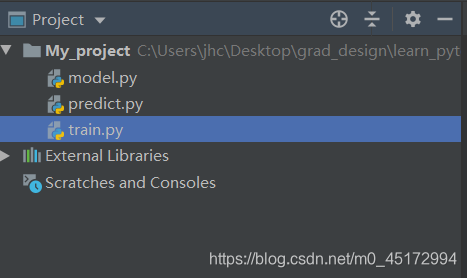
我这里就只保留了几个脚本小文件,方便本地操作。上述所有步骤完成后,就可以打开矩池云插件进行,利用云端GPU,进行神经网络的训练了。

点击覆盖,此时你对这几个脚本做的任何操作都会自动同步到云盘。当然你也要选择同步目录,来确保这些文件能同步到正确的位置。

接下来的操作就是更改IDE的解释器为远程解释器。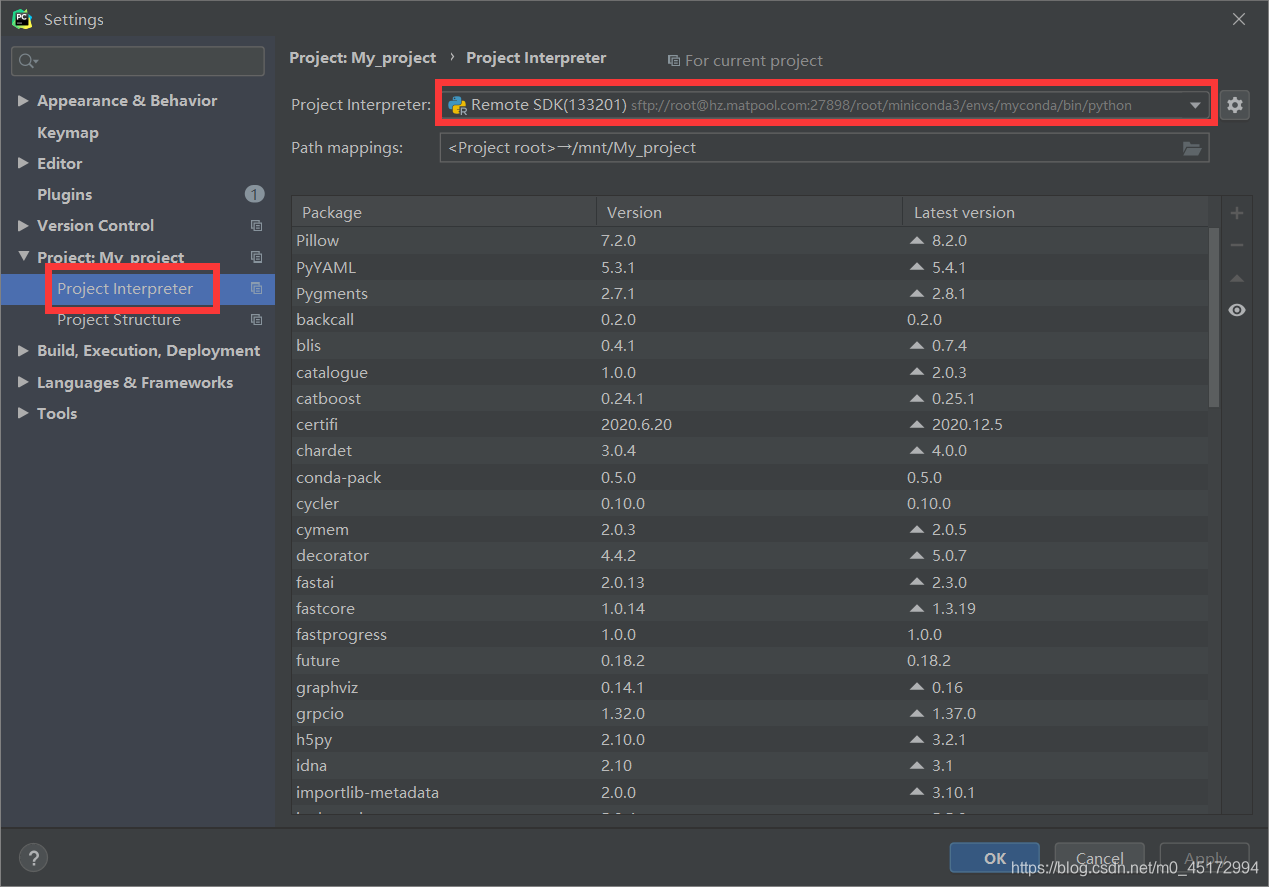
在File-Settings将解释器更改为Remote SDK,邮件单击,点击Run,就可以开始训练你的卷积神经网络了。训练完成的时间非常快,我使用的网络是AlexNet,数据集中大概有3000多张图片,只用了1分钟不到就训练了10个epoch,下图是其中一个epoch所使用的时间。

训练第一个epoch大概只用了9秒的时间,验证测试集大概是2秒,可能你对这个时间没有概念,可以看一下使用CPU进行训练一个epoch所需要的时间。

此图是使用CPU进行训练的情况,可以看到,训练一个epoch的时间是2分19秒,是使用CPU训练时间的15倍之多。通过对比,我们能明显感受到我们确实成功连接了云上的GPU,并成功地缩短了训练的时间。我对毕设的13张数据集进行训练时,使用CPU几乎不可能,但是使用租用的GPU,一个多小时就训练完成了。
四、一些常见的问题及建议
一、根据我租用的GPU来看,矩池云平台上1元/h和6元/h的GPU,我感受不到差别,或许是网络复杂度比较小,高性能的GPU无法展现他真正的实力吧,所以建议大家合理租赁GPU。
二、租用了GPU,但是训练的速度跟CPU完全一致,根本没有任何提升,是什么问题?
遇到这种情况,可以从以下几方面来考虑解决:第一是你使用的代码是否对cuda,Pytorch版本有着严格的要求,如果有的话,在选择镜像的时候一定要记得选择合适自己的镜像。第二将训练代码中batch_size数值改大一些。我尝试了前两种方案,都没有解决我刚开始遇到的问题,第三种就是增大Data_loader中的num_workers数值,如果你的num_workers设置的是0的话,那么可以更改为2的整数次幂,我更改的32,速度就很明显的提升。这个数据的意义就是让CPU处于多线程工作模式,所以由于内存的限制,num_workers数值不可能无限制增大。为什将CPU设置成多线程工作就能解决这个问题呢,我认为可能是数据的处理在CPU中,而模型的学习是在GPU中,CPU处理的速度太慢了与GPU的速度不匹配,所以设置了多线程可以解决这个问题。
三、运行程序时有时候会报一些奇奇怪怪的错误,你可以先试着将矩池云注销,然后重新登录,如果仍然解决不了,有可能是解释器的问题,将解释器更改一下,一般有两个Remote,有一个是Default,不要选哪个带Default的,一般就可以解决报错问题。
大家可以使用自己神经网络以及数据集试验一下上述的所有步骤是否可行。我也将我自己的数据集放在这里,有需要的朋友可以下载,按照上述步骤进行验证,所有配置完以后,点击train.py就可以开始训练了。
链接:https://pan.baidu.com/s/1P7MdYwNsHrYc3qHunccffQ
提取码:kut3

















 258
258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









