






1.简介
raft算法是一种分布式共识算法,替代了Paxos成为接受度更广的分布式共识算法。
背景:为了提升大规模数据下的读写性能,分布式系统的优势:(1)数据备份;(2)负载均衡
解决问题:不同于单机系统,分布式多节点之间需要考虑到网络的不确定性,那么如何保证不同节点间的数据一致性问题,以及整个系统的秩序?
2.CAP理论
C:Consistency一致性
A:Availability可用性
P:Partition Tolerance分区容错性
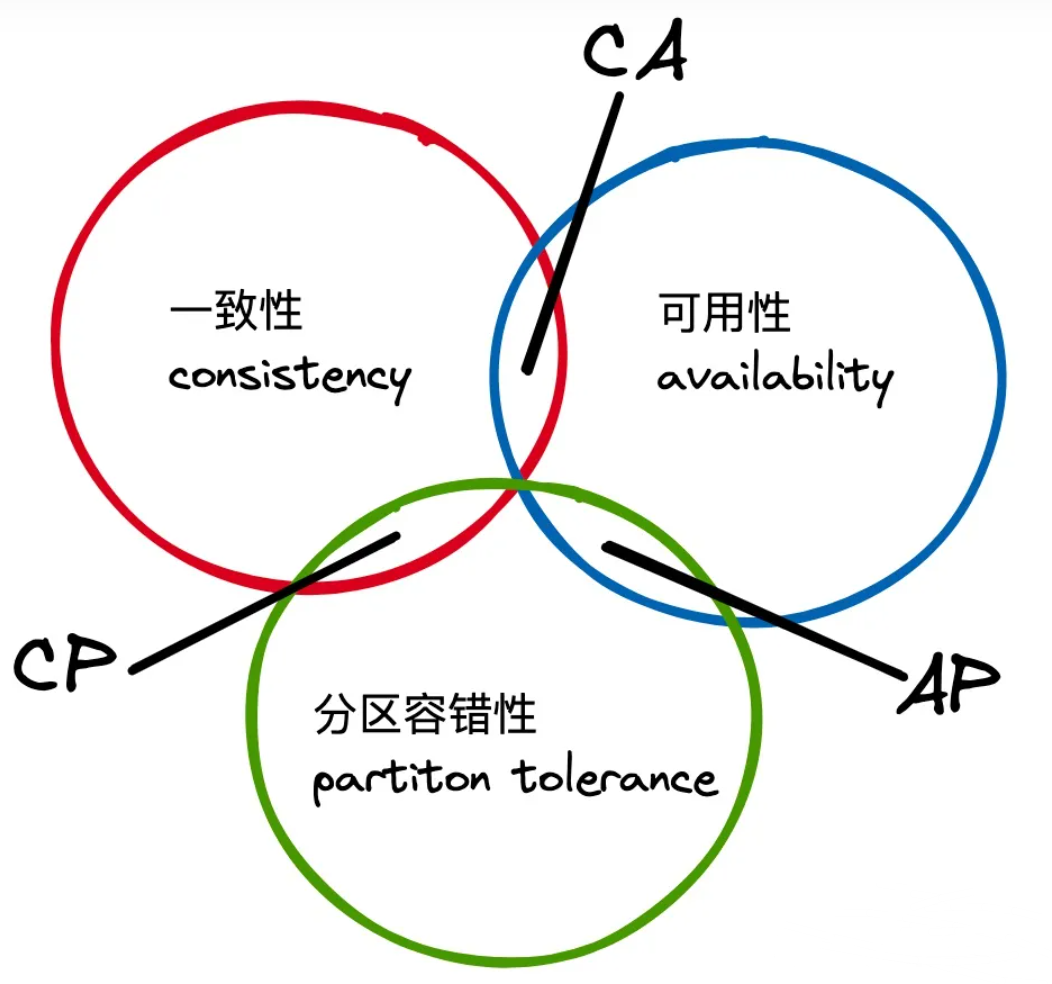
C,A,P对于一个系统而言至多满足其二,对于单机系统可以是CA,CP,AP,但对于分布式系统而言,P分区容错是必须保证的,因此分为CP,AP,分别倾向于保障一致性和可用性。
C的问题:(1)即时一致性;(2)顺序一致性
A的问题:(1)某个节点宕机,整个系统无法返回ack;(2)某个节点网络不好,整个系统的响应时间跟着变长
分布式一致性共识算法是为了在A和C之间取得良好的平衡。
3.一些术语

4.一些细节
多数原则
总体节点半数以上达成的共识即可视为整个系统的答复
一主多从,读写分离
1个leader若干个follower,读操作所有节点可提供,写操作需要统一转发给leader处理
问题:(1)某个节点还未完成一致性同步就被读取数据,这是因为只保证了最终一致性,没有满足即时一致性;
(2)一主多从,leader挂了后群龙无首,系统脑裂
方案:(1)即时一致性的解决方案;(2)选举机制
两阶段提交
在将数据写入状态机(实际存储数据的节点)前,需要将写请求明细通过日志的方式记录在预写日志(write ahead log)中,预写日志存放在一个数组缓冲区中,然后:
(1)leader将写请求写入预写日志中,并广播集群其他节点,称之为提议proposal
(2)若半数以上校验后同意了该操作,leader会提交commit这个请求,并返回给客户端ack
(3)所有节点同步预写日志,并最终写入状态机
领导者选举机制
(1)如何得知leader挂了?心跳机制
(2)谁能成为新的leader?follower会成为候选人向所有人拉票,多数人投了赞同票即可成为新一任leader
一个任期称为term,每个任期内至多有一个leader(可能还未选举出来),存于数组中的每则预写日志WAL中包含两个属性:(1)term号;(2)index索引号,标明在日志数组中的位置

leader挂了或者任期结束,竞选出新的leader
leader需要做的:
(1)收到写请求时,开启两阶段提交流程;
(2)定时发送心跳信号,携带(term+index)定位到具体的日志,推动follower更新日志
follower需要做的:
同步写请求;接收心跳;投票或参与竞选
candidate是一种临时态,成为leader或follower
原文:https://zhuanlan.zhihu.com/p/600147978?utm_id=0















 1464
1464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









