







线性结构
线性结构表达式: (,
,......,
)
线性结构的特点:
1.只有一个首结点和尾结点;
2.除首尾结点外,其他结点只有一个直接前驱和一个直接后继。
简言之,线性结构反映结点间的逻辑关系是一对一的。线性结构包括线性表、堆栈、队列、字符串、数组等等,其中,最基本、最常用的是线性表。
线性表的定义: n(n>=0)个具有相同特征数据元素的有限序列。
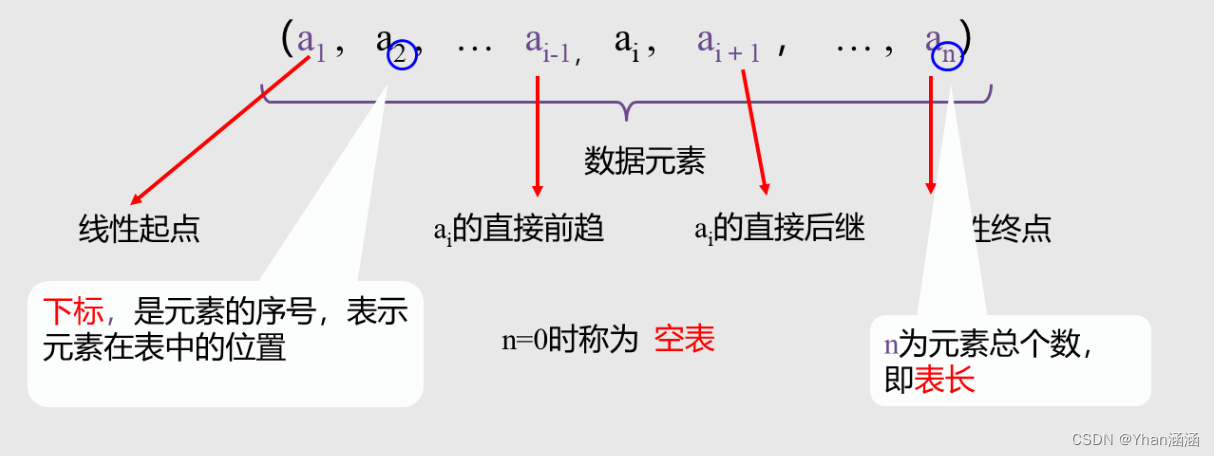
数据元素都是记录,元素间关系是线性的。同一线性表中的元素必定具有相同特性。
线性表
线性表的顺序表示又称为顺序存储结构或顺序映像。顺序存储的线性表称为顺序表。
顺序存储定义:把逻辑上相邻的数据元素存储在物理上相邻的存储单元中的存储结构。简言之,逻辑上相邻,物理上也相邻。
顺序存储方法:用一组地址连续的存储单元依次存储线性表的元素,可通过数组V[n]来实现。
顺序存储的实现:
[静态分配方法]
#defined MAXSIZE 100
typedef struct {
ElemType elem[MAXSIZE];
int length;//顺序表当前长度
} SqList;
[动态分配方法]
typedef struct {
ElemType *elem;
int length;
int listsize;
}SqList;
SqList L;
顺序表
顺序表的基本操作:
[插入]
Status ListInsert(SqList &L,int i,ElemType e) //按位置插入
{
if(i>L.length+1 or L.length>=100 or i<1) return 0;
L.length++;
int temp;
int j=L.length;
while(j>=i)
{
L.elem[j]=L.elem[j-1];
j--;
}
L.elem[i-1]=e;
return 1;
}
1.位置i是否合理:1≤i≤L.length+1
2.表满:L.length==L.listsize
表满处理:L.elem=(ElemType *)realloc(L.elem,(L. listsize+INCREMENT)*sizeof(ElemType))或return ERROR;
[删除]
Status ListDelete(SqList &L,int i)//按位置删除
{
if(i>L.length or i<1) return 0;
L.length--;
i--;
while(i<L.length)
{
L.elem[i]=L.elem[i+1];
i++;
}
return 1;
}
1.注意事先需要判断位置i是否合法:1≤i≤L.length
2.算法的时间复杂度:
在第i位插入元素需移动的次数=n-i+1
插入时的平均移动次数=n/2
![]()
删除运算的平均移动次数= (n-1)/2
时间复杂度为:O(n)
顺序表的优点:
1.存储密度大(结点本身所占存储量/结点结构所占存储量)。
2.可以快速地计算出任何一个数据元素的存储地址,随机存取表中任一元素。
顺序表的缺点:
1.插入和删除操作需要移动大量元素。
2.表的容量难以估计,过大会浪费空间,过小则会溢出。
3.容易造成储存空间的“碎片”。
链式储存
链式存储结构特点:其结点在存储器中的位置是随意的,即逻辑上相邻的数据元素在物理上不一定相邻。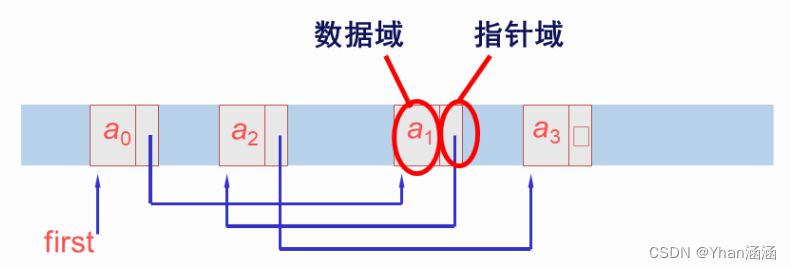
单链表:结点只有一个指针域的链表,称为单链表或线性链表
头指针:指向单链表中第一个结点的指针,是单链表的唯一标识。
首结点(首元结点):存放线性表中第一个数据元素的结点。
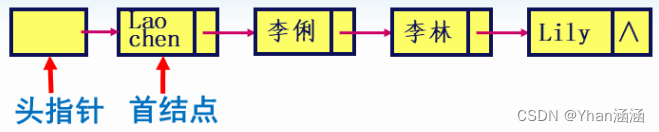
头结点:在链表的首结点之前附设的一个结点,该结点的数据域可以为空,也可存放表长度等附加信息。
链表中设置头结点作用:
1.便于首元结点的处理:首元结点的地址保存在头结点的指针域中,所以在链表的第一个位置上的操作和其它位置一致,无须进行特殊处理。
2.便于空表和非空表的统一处理:无论链表是否为空,头指针都是指向头结点的非空指针,因此空表和非空表的处理也就统一了。
链式储存的实现:
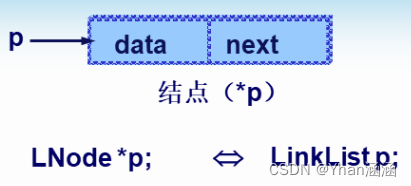
typedef struct LNode//单链表结点结构定义
{
ElemType data;//数据域,存放数据元素
struct LNode *next;//指针域,指向后继元素
}LNode , *LinkList;//单链表的类型名

p表示所指向的结点:
(*p).data;p->data; //表示p指向结点的数据域
(*p).next;p->next; //表示p指向结点的指针域生成一个LNode型新结点:
p=(LNode *)malloc(sizeof(LNode));
p=new LNode;回收p结点:
free(p);
delete p;
单链表操作:
[建立]
//头插法
struct Linklist* insertFromHead(struct Linklist* head,Linklist* p) //头插法处理函数
{
if(p == NULL) head = p; //判断head是否创建有节点
else
{
p->next = head; //将头节点,赋值给新创建的下一个节点
head = p; //将新创建的结点的地址赋给头指针的结点
}
return head; //返回头节点
}
//尾插法
struct Linklist* insertFromTail(struct Linklist* head,Linklist* p) //尾插法处理函数
{
Linklist* point;
point=(Linklist*)malloc(sizeof(Linklist));
point=NULL;
if(head == NULL)
{
head=p;
point=p;
}
else
{
while(point->next != NULL) point = point->next; //让point指针指向下一个结点,保证它指向链表尾部
point->next = p; //让point指针指向的结点的next成员指向新建结点p
}
return head;
}
[初始化]
void InitList(SqList &L)
{
L=(LinkList)malloc(sizeof(LNode));
L->next=NULL;
return OK;
}[查询]
Status Get_LinkList(LinkList H, ElemType key)
{
int index;
LNode *p;
p=(LNode *)malloc(sizeof(LNode));
p=H->next;
index=1;
while(p->next!=NULL and p->data!=key)
{
p=p->next;
index++;
}
if(p->next==NULL) return -1;
else return index;
}1.表示p指针所指结点的数据域
p->data
p->data.name2.表示指针的移动
p=p->next[取值]
Status GetElem_L(LinkList L,int i,ElemType &e)
{
p=L->next;
j=1;//初始化
while(p&&j<i)//向后扫描,直到p指向第i个元系
{
p=p->next;
++j;
}
if(!p||j>i) return ERROR;//第i个元素不存在
e=p->data;//取第i个元素
return OK;
}
[插入]
Status ListInsert(LinkList &L,ElemType e)
{
LNode *p;
p=(LNode *)malloc(sizeof(LNode));
p=L;
while(p->next!=NULL&&strcmp(e.name,p->next->data.name)>0) p=p->next;
LNode *s;//申请一个新节点
s=(LNode *)malloc(sizeof(LNode));
s->next=NULL;//新节点初始化
s->data=e;
if(p==NULL) p=s;
else
{
s->next=p->next;//先接尾
p->next=s;//再联头
}
return OK;
}[删除]
Status ListDelete(LinkList &L,char name[])
{
LNode *p,*q;
p=(LNode *)malloc(sizeof(LNode));
q=(LNode *)malloc(sizeof(LNode));
p=L;
if(p->next==NULL) return ERROR;
while(p->next!=NULL&&strcmp(name,p->next->data.name)!=0) p=p->next;
if(p->next==NULL) return ERROR;
q=p->next;//为释放节点做准备
p->next=p->next->next;
free(q);
return OK;
}链表优点:
1.数据元素的个数可以自由扩充
2.插入、删除等操作不必移动数据,只需修改链接指针,修改效率较高
链表缺点:
1.存储密度小
2.存取效率不高,必须采用顺序存取,即存取数据元素时,只能按链表的顺序进行访问
例:单链表按姓名插入删除
#include<string.h> #include<stdio.h> #include<stdlib.h> #define OK 1 #define ERROR 0 #define OVERFLOW -2 typedef int Status; typedef struct Telephone{ char name[10]; char Tel[12]; }ElemType; typedef struct LNode /* 定义链式存储结构 */ { ElemType data; struct LNode *next; }LNode,*LinkList; Status InitList(LinkList &L) /* 初始化 */ { L=(LinkList)malloc(sizeof(LNode)); L->next=NULL; return OK; } Status ListInsert(LinkList &L,ElemType e) /* 插入 */ { LNode *p; p=(LNode *)malloc(sizeof(LNode)); p=L; while(p->next!=NULL&&strcmp(e.name,p->next->data.name)>0) p=p->next; LNode *s; s=(LNode *)malloc(sizeof(LNode)); s->next=NULL; s->data=e; if(p==NULL) p=s; else { s->next=p->next; p->next=s; } return OK; } Status ListDelete(LinkList &L,char name[]) /* 删除 */ { LNode *p,*q; p=(LNode *)malloc(sizeof(LNode)); q=(LNode *)malloc(sizeof(LNode)); p=L; if(p->next==NULL) return ERROR; while(p->next!=NULL&&strcmp(name,p->next->data.name)!=0) p=p->next; if(p->next==NULL) return ERROR; q=p->next; p->next=p->next->next; free(q); return OK; } void Print_LinkList(LinkList H) /* 输出链表中每个数据元素值 */ { LNode *p; p=H->next; //p指向首元结点 if(p==NULL) printf("链表为空\n"); while(p!=NULL) { printf("姓名:%s,电话:%s\n",p->data.name,p->data.Tel); p=p->next; } } int main() { LinkList L; ElemType e; char name[10]; int n; InitList(L); scanf("%d",&n); for(int i=0;i<n;i++) { scanf("%s",e.name); scanf("%s",e.Tel); ListInsert(L,e); } Print_LinkList(L); //输出单链表 scanf("%s",name); //输入删除人姓名 if(ListDelete(L,name)) { printf("删除后:\n"); Print_LinkList(L); //输出单链表 } else printf("查无此人!"); return 0; }
链表与顺序表对比:
| 随机存取访问 | 插入操作 | 删除操作 | 内存空间 | |
|---|---|---|---|---|
| 顺序表 | O(1) | O(n) | O(n) | 受限,储存密度为1 |
| 链表 | O(n) | O(1) | O(1) | 不受限,储存密度小于1 |
链表的其他形式:
[循环链表]

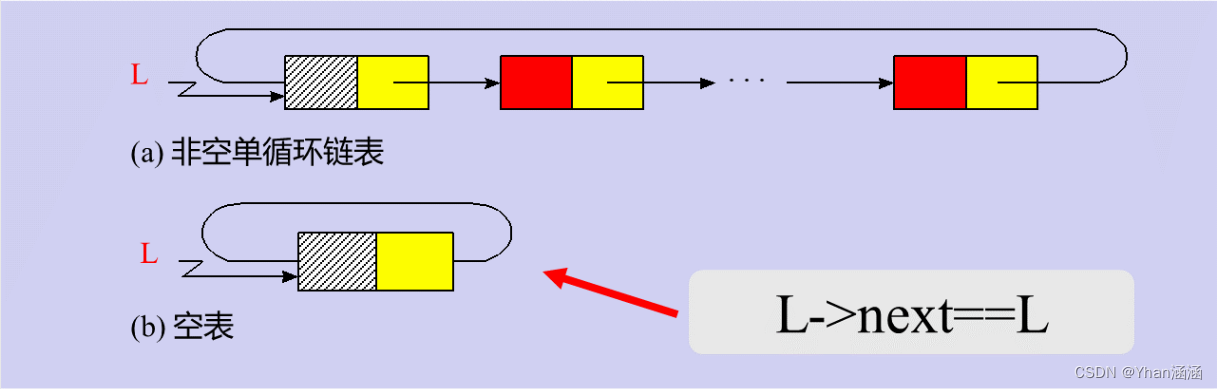
从循环链表中的任何一个结点的位置都可以找到其他所有结点,而单链表做不到。以下是单链表和循环链表的一些对比:
| 单链表 | 单循环链表 | |
|---|---|---|
| 循环条件 | p!=NULL或p->next!=NULL | p!=L或p->next!=L |
| 表尾结点判定条件 | p->next==NULL | p->next==L |
| 链表判空条件 | p->next==NULL | L->next==L |
对循环链表,有时不给出头指针,而给出尾指针可以更方便的找到第一个和最后一个结点。

开始结点:rear->next->next
终端结点:rear
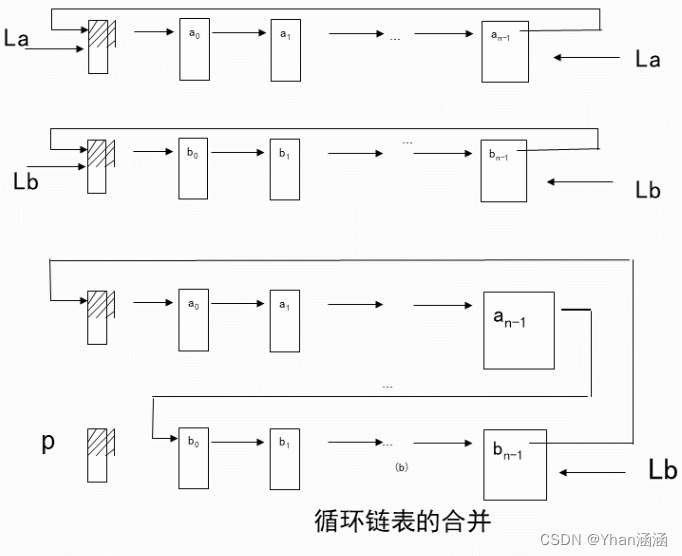
循环链表的合并:
Void merge(LinkList La, LinkList &Lb)
{
p=Lb->next;
Lb->next=La->next;
La->next=Lb->next->next;
free(p);
}
[双向链表]
typedef struct DuLNode{
ElemType data;
struct DuLNode *prior;
struct DuLNode *next;
}DuLNode,*DuLinkList
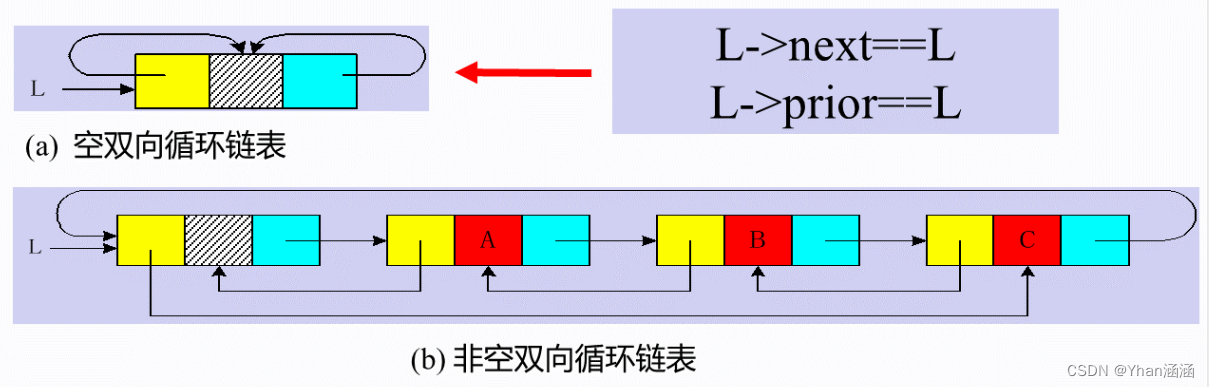
若p为指向表中某结点的指针,则p->next->prior==p>prior->next==p
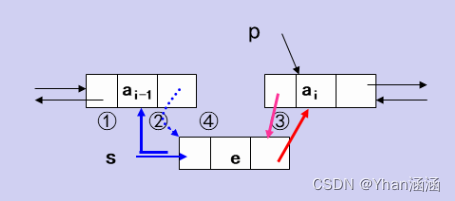
循环链表的插入:
Status ListInsert_DuL(DuLinkList &L,int i,ElemType e)
{
p=L->next;
j=1;
while (p!=L && j<i) //双向循环链表
{
p=p->next;
j++;
}
if ((p==L&&j<i)||j>i) return ERROR;
s=(DuLNode *)malloc(sizeof(DuLNode));
s->data=e;
s->prior=p->prior;
p->prior->next=s;
s->next=p;
p->prior=s;
return OK;
}
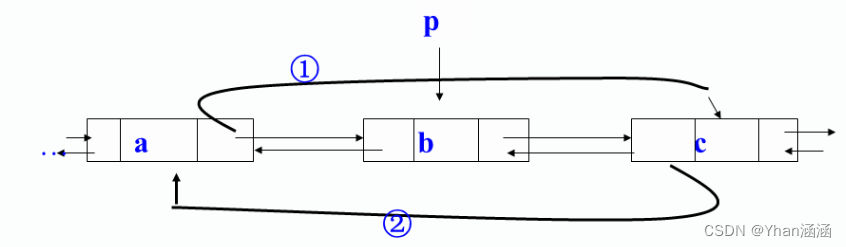
双向链表的删除:
Status ListDelete_DuL(DuLinkList &L,int i,ElemType &e)
{
p=L->next;
j=1;
while (p!=L&&j<i)
{
p=p->next;
j++;
}
if (p==L||j>i) return ERROR;
e=p->data;
p->prior->next=p->next;
p->next->prior=p->prior;
free(p);
return OK;
}

















 1482
1482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











