






本文参考python爬取微博数据(截至2021.10.3仍然有效)_Nosimper的博客-CSDN博客,原文代码我运行时有一些小小的报错,结合自身需求在此基础上做了一些改进,但还是有一些不足之处,如有错误请各位批评指正。
1.首先解决了原代码的问题:
- 原代码的userIdList.txt文件中如果是一行一个userIdList的话,运行完一个uid后会报错,不能继续执行下一个uid。
- 原代码是一次性爬取该博主所有博文,不符合我爬取一个月内博文的需求。
- 原代码直接保存为了pkl文件,不方便后续使用
2.还需要改进的地方:
- 如果有置顶博文在一个月之外的话,那后面的博文也爬取不到了,这个问题暂时还没解决
- 会有一小部分博文获取不到
3.如有需要,可根据自身情况改动如下地方:
(1)用户名和密码改成自己的
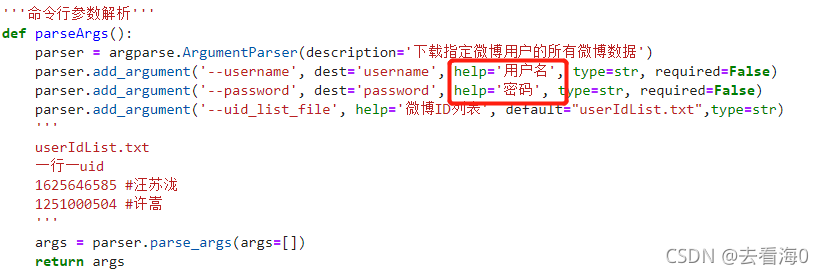
(2)建立一个userIdList.txt文件,里面存放博主的uid,有的博主主页网址里就有uid,没有的话点击任意一条博文前面博主的头像,网址里就会变成有uid的了。


(3)爬取的时间范围,我取的30天,可以根据自身需求修改
下面是代码部分:
import os
import sys
import time
import random
import pickle
import datetime
import argparse
import prettytable
import re
import pandas as pd
from tqdm import tqdm
from lxml import etree
from DecryptLogin import login
'''命令行参数解析'''
def parseArgs():
parser = argparse.ArgumentParser(description='下载指定微博用户的所有微博数据')
parser.add_argument('--username', dest='username', help='用户名', type=str, required=False)
parser.add_argument('--password', dest='password', help='密码', type=str, required=False)
parser.add_argument('--uid_list_file', help='微博ID列表', default="userIdList.txt",type=str)
'''
userIdList.txt
一行一uid
1625646585 #汪苏泷
1251000504 #许嵩
'''
args = parser.parse_args(args=[])
return args
'''目标用户微博数据爬取'''
class WeiboSpider():
def __init__(self, username, password, uid_list_file,**kwargs):
self.session = WeiboSpider.login(username, password)
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
self.savedir = os.path.join(os.getcwd(), 'datas_pkl')
with open(uid_list_file, "r") as f:
self.uid_list = [line.strip('\r\n') for line in f.readlines()]
'''外部调用接口'''
def start(self):
for user_id in self.uid_list:
print("[INFO]: 当前爬取微博ID为:{}".format(user_id))
# 提取该目标用户的基本信息供使用者确认输入是否有误
url = f'https://weibo.cn/{user_id}'
res = self.session.get(url, headers=self.headers)
# 转发网址
replace_pattern = re.compile(r'location.replace\([\'\"](.*?)[\'\"]\)')
while len(replace_pattern.findall(res.text))>0:
replace_url = replace_pattern.findall(res.text)[0]
res = self.session.get(replace_url, headers=self.headers)
selector = etree.HTML(res.content)
base_infos = selector.xpath("//div[@class='tip2']/*/text()")
pattern = re.compile(r"\[(.*)\]")
#微博数量,关注数量,被关注数量
num_wbs, num_followings, num_followers = int(pattern.findall(base_infos[0])[0]), int(pattern.findall(base_infos[1])[0]), (pattern.findall(base_infos[2])[0])
#微博页数
num_wb_pages = selector.xpath("//input[@name='mp'][1]/@value")
num_wb_pages = int(num_wb_pages[0]) if len(num_wb_pages) > 0 else 1
#用户名
url = f'https://weibo.cn/{user_id}/info'
res = self.session.get(url, headers=self.headers)
selector = etree.HTML(res.content)
nickname = selector.xpath('//title/text()')[0][:-3]
# 使用者确认是否要下载该用户的所有微博
tb = prettytable.PrettyTable()
tb.field_names = ['用户名', '关注数量', '被关注数量', '微博数量', '微博页数']
tb.add_row([nickname, num_followings, num_followers, num_wbs, num_wb_pages])
print('获取的用户信息如下:')
print(tb)
# is_download = input('是否爬取该用户的所有微博?(y/n, 默认: y) ——> ')
# if is_download == 'y' or is_download == 'yes' or not is_download:
userinfos = {'user_id': user_id, 'num_wbs': num_wbs, 'num_wb_pages': num_wb_pages}
self.__downloadWeibos(userinfos)
# # 使用者是否要继续下载
# is_continue = input('是否还需下载其他用户的微博数据?(n/y, 默认: n) ——> ')
# if is_continue == 'n' or is_continue == 'no' or not is_continue:
# break
'''下载某个用户的所有微博数据'''
def __downloadWeibos(self, userinfos):
# 用于存储微博数据
weibos_dict = {}
# 一些必要的信息
num_wbs = userinfos.get('num_wbs')
user_id = userinfos.get('user_id')
num_wb_pages = userinfos.get('num_wb_pages')
# 爬取所有微博数据
page_block_size = random.randint(1, 5)
page_block_count = 0
try:
for page in tqdm(range(1, num_wb_pages+1)):
url = f'https://weibo.cn/{user_id}?page={page}'
res = self.session.get(url, headers=self.headers)
selector = etree.HTML(res.content)
#内容
contents = selector.xpath("//div[@class='c']")
if contents[0].xpath("div/span[@class='ctt']"):
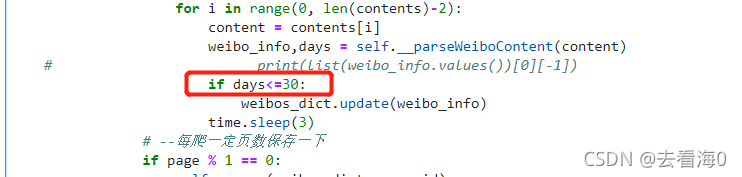
for i in range(0, len(contents)-2):
content = contents[i]
weibo_info,days = self.__parseWeiboContent(content)
# print(list(weibo_info.values())[0][-1])
if days<=30:
weibos_dict.update(weibo_info)
time.sleep(3)
# --每爬一定页数保存一下
if page % 1 == 0:
self.__save(weibos_dict, user_id)
# --避免给服务器带来过大压力and避免被封, 每爬几页程序就休息一下
page_block_count += 1
if page_block_count % page_block_size == 0:
time.sleep(random.randint(1, 3))
page_block_size = random.randint(5, 10)
page_block_count = 0
filepath = self.__save(weibos_dict, user_id)
print('用户%s的所有微博数据下载完毕, 数据保存在%s...' % (user_id, filepath))
except:
pass
'''处理不同类型的微博'''
def __parseWeiboContent(self, content):
weibo_info = {}
# 是否为原创微博
is_ori = False if len(content.xpath("div/span[@class='cmt']")) > 3 else True
# 微博ID
weibo_id = content.xpath('@id')[0][2:]
# 微博文本
if is_ori:
if u'全文' in content.xpath('div//a/text()'):
url = f'https://weibo.cn/comment/{weibo_id}'
res = self.session.get(url, headers=self.headers)
selector = etree.HTML(res.content)
weibo_text_tmp = selector.xpath("//div[@class='c']")
if len(weibo_text_tmp) > 1:
weibo_text_tmp = weibo_text_tmp[1]
weibo_text = weibo_text_tmp.xpath('string(.)').replace(u'\u200b', '').encode('utf-8', 'ignore').decode('utf-8')
weibo_text = weibo_text[weibo_text.find(':')+1: weibo_text.rfind(weibo_text_tmp.xpath("//span[@class='ct']/text()")[0])]
else:
weibo_text = ''
else:
weibo_text = content.xpath('string(.)').replace(u'\u200b', '').encode('utf-8', 'ignore').decode('utf-8')
weibo_text = weibo_text[:weibo_text.rfind(u'赞')]
else:
if u'全文' in content.xpath('div//a/text()'):
url = f'https://weibo.cn/comment/{weibo_id}'
res = self.session.get(url, headers=self.headers)
selector = etree.HTML(res.content)
weibo_text_tmp = selector.xpath("//div[@class='c']")
if len(weibo_text_tmp) > 1:
weibo_text_tmp = weibo_text_tmp[1]
weibo_text = weibo_text_tmp.xpath('string(.)').replace(u'\u200b', '').encode('utf-8', 'ignore').decode('utf-8')
weibo_text = weibo_text[weibo_text.find(':')+1: weibo_text.rfind(weibo_text_tmp.xpath("//span[@class='ct']/text()")[0])]
weibo_text = weibo_text[:weibo_text.rfind(u'原文转发')]
else:
weibo_text = ''
else:
weibo_text = content.xpath('string(.)').replace(u'\u200b', '').encode('utf-8', 'ignore').decode('utf-8')
weibo_text = weibo_text[weibo_text.find(':')+1: weibo_text.rfind(u'赞')][:weibo_text.rfind(u'赞')]
# 微博发布的时间
publish_time = content.xpath("div/span[@class='ct']")[0]
publish_time = publish_time.xpath('string(.)').replace(u'\u200b', '').encode('utf-8', 'ignore').decode('utf-8')
publish_time = publish_time.split(u'来自')[0]
if u'刚刚' in publish_time:
publish_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
# publish_time = datetime.datetime.now().strftime('%Y-%m-%d')
print('刚刚',publish_time)
elif u'分钟' in publish_time:
passed_minutes = publish_time[:publish_time.find(u'分钟')]
publish_time = (datetime.datetime.now() - datetime.timedelta(minutes=int(passed_minutes))).strftime('%Y-%m-%d %H:%M')
# publish_time = (datetime.datetime.now() - datetime.timedelta(int(passed_minutes))).strftime('%Y-%m-%d')
print('分钟',publish_time)
elif u'今天' in publish_time:
today = datetime.datetime.now().strftime('%Y-%m-%d')
publish_time = today + ' ' + publish_time[3:]
print('今天',publish_time)
if len(publish_time) > 16: publish_time = publish_time[:16]
elif u'月' in publish_time:
year = datetime.datetime.now().strftime('%Y')
month = publish_time[0: 2]
day = publish_time[3: 5]
publish_time = year + '-' + month + '-' + day + ' ' + publish_time[7: 12]
print('月',publish_time)
else:
publish_time = publish_time[:16]
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
# 转换为时间格式
time2 = pd.to_datetime(publish_time)
# 计算时间差值
delta = pd.to_datetime(now) - time2
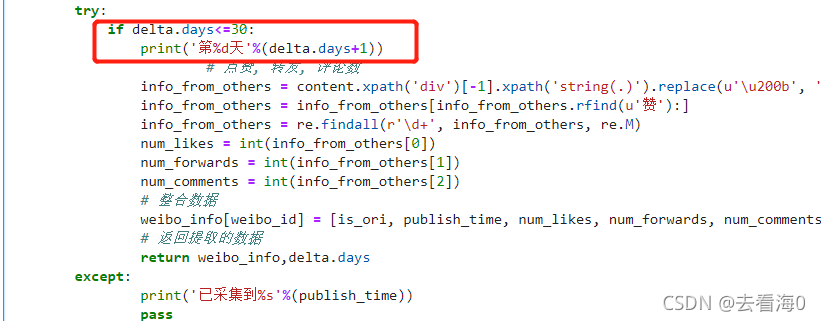
try:
if delta.days<=30:
print('第%d天'%(delta.days+1))
# 点赞, 转发, 评论数
info_from_others = content.xpath('div')[-1].xpath('string(.)').replace(u'\u200b', '').encode('utf-8', 'ignore').decode('utf-8')
info_from_others = info_from_others[info_from_others.rfind(u'赞'):]
info_from_others = re.findall(r'\d+', info_from_others, re.M)
num_likes = int(info_from_others[0])
num_forwards = int(info_from_others[1])
num_comments = int(info_from_others[2])
# 整合数据
weibo_info[weibo_id] = [is_ori, publish_time, num_likes, num_forwards, num_comments, weibo_text]
# 返回提取的数据
return weibo_info,delta.days
except:
print('已采集到%s'%(publish_time))
pass
'''保存微博数据'''
def __save(self, weibos_dict, user_id):
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
filepath = os.path.join(self.savedir, user_id+'.pkl')
f = open(filepath, 'wb')
pickle.dump(weibos_dict, f)
f.close()
return filepath
'''利用DecryptLogin模拟登录'''
@staticmethod
def login(username, password):
lg = login.Login()
#这里选择扫码登录,而微博验证码每时段有发送次数限制
_, session = lg.weibo(username, password, 'scanqr')
return session
'''run'''
if __name__ == '__main__':
args = parseArgs()
wb_spider = WeiboSpider(args.username, args.password, args.uid_list_file)
wb_spider.start()代码里保存的是pkl文件,还可以把pkl文件转成excel文件:
#把pkl文件转换成excel文件
import pandas as pd
df = pd.read_pickle("./datas_pkl/2400966427.pkl")
pd.DataFrame(df).T.to_excel('./datas/冬亚.xlsx')爬完之后的数据如下:


















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









