







这篇文章主要放源代码,思路不会介绍特别清楚,详细思路可以看评论区的b站讲解视频。
1.场景需求
获取微博肖战超话内容部分用户的帖子数据,日期范围限定在近2个月,要求获得帖子的发布时间、帖子文本内容、转发数据、评论数据和点赞数据(不包括评论的内容和点赞的人)。
2.网站调研
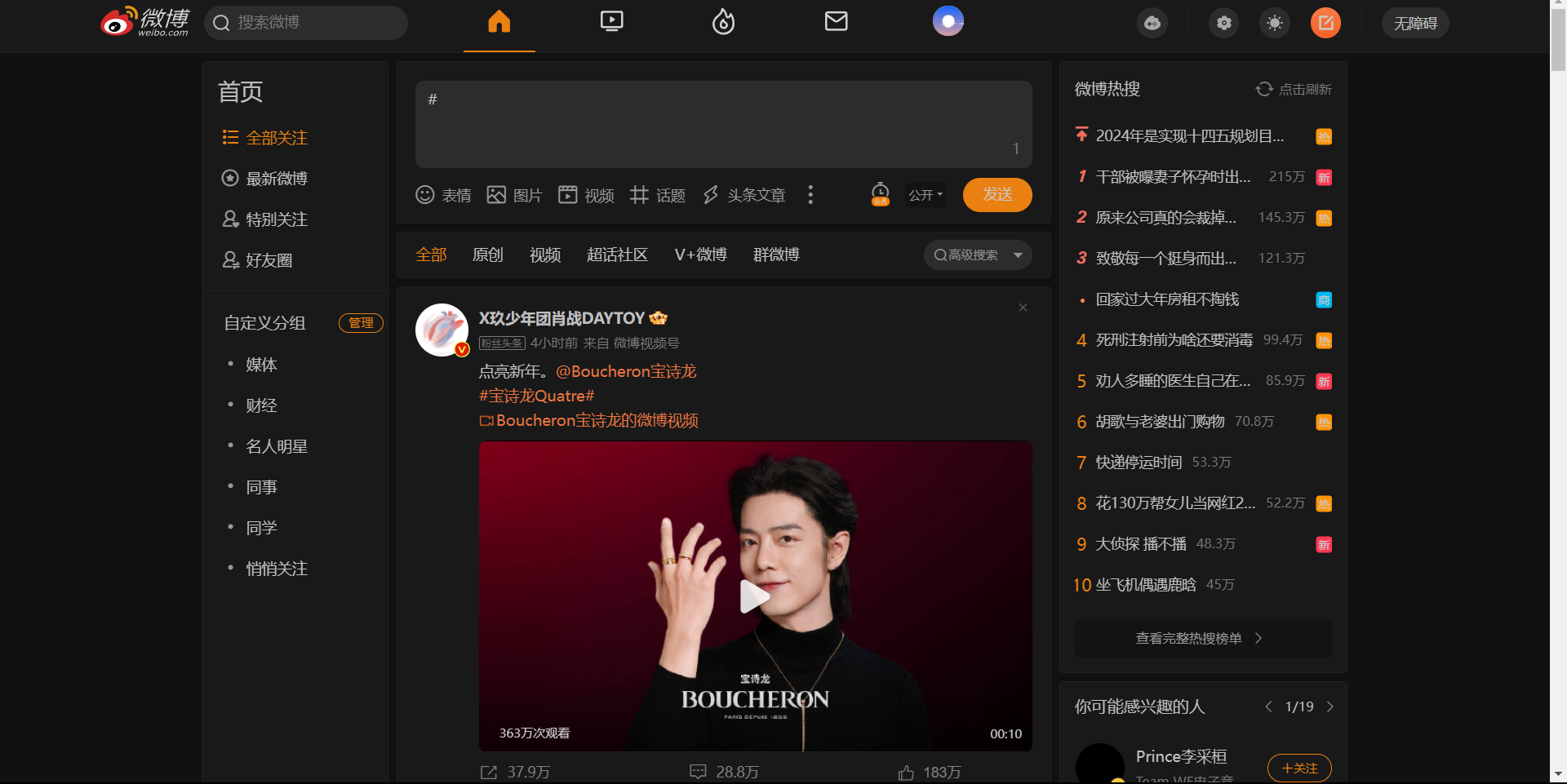
通过调查发现,微博有2个入口,第一种如下:
第二种如下:
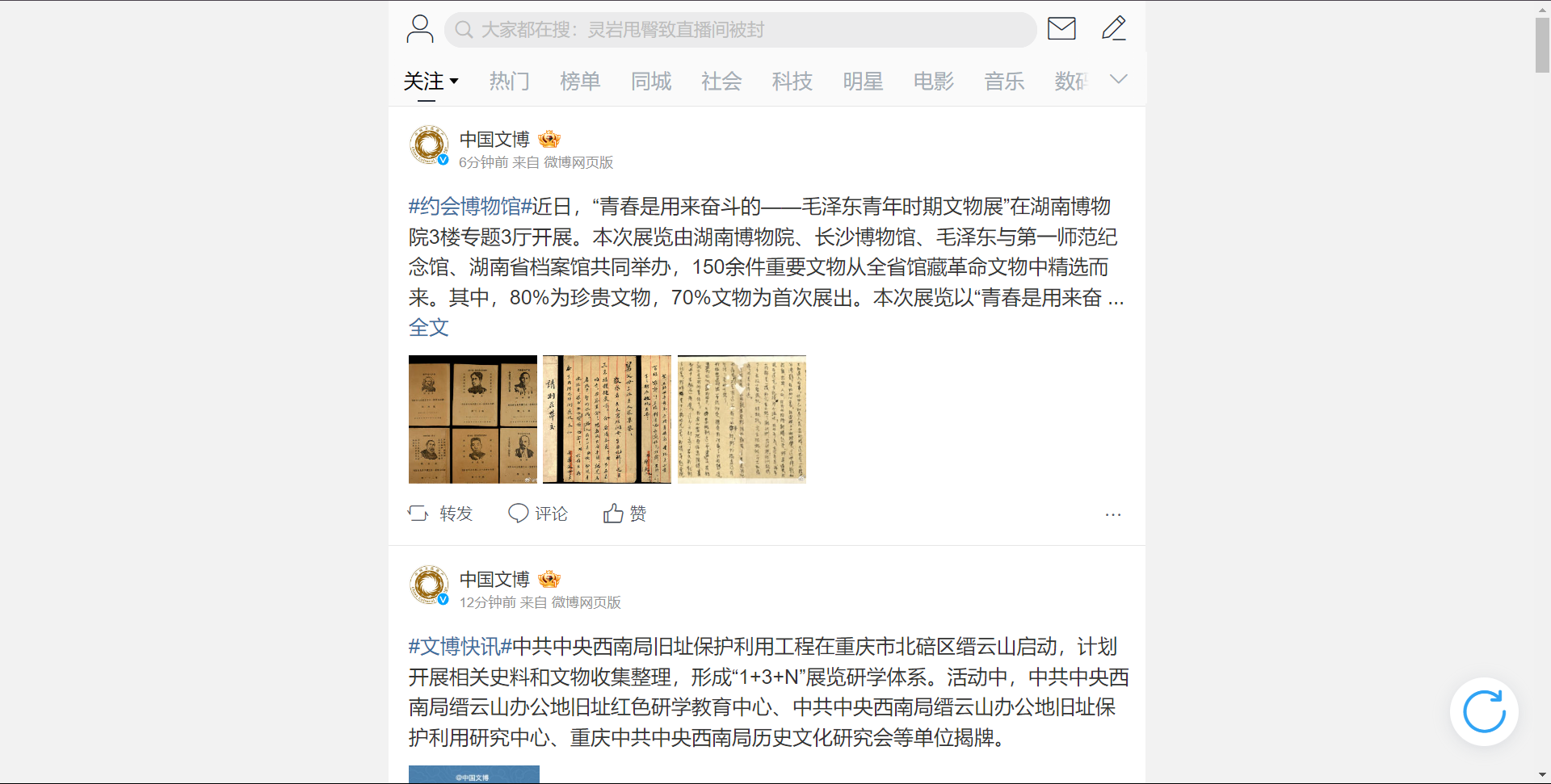 这2种入口爬取方式不同,我因为不熟悉微博,所以也是把两个入口的方式都试了一遍。。。所以这里有个经验要分享一下:爬虫的最终目的是获取需要的数据,不管用什么方式,从网站哪个入口开始,都应该要实现高效率的获得所有数据。因此在爬虫之前,应该花时间了解目标网站的数据存储方式,切忌一上来就找个网址开始胡乱一通爬,得动脑子思考、观察再决定爬取方案。尤其是规模大的项目,方案没选好后面会出现爬取速度很慢、内存不够用、爬一半发现方案行不通等问题。
这2种入口爬取方式不同,我因为不熟悉微博,所以也是把两个入口的方式都试了一遍。。。所以这里有个经验要分享一下:爬虫的最终目的是获取需要的数据,不管用什么方式,从网站哪个入口开始,都应该要实现高效率的获得所有数据。因此在爬虫之前,应该花时间了解目标网站的数据存储方式,切忌一上来就找个网址开始胡乱一通爬,得动脑子思考、观察再决定爬取方案。尤其是规模大的项目,方案没选好后面会出现爬取速度很慢、内存不够用、爬一半发现方案行不通等问题。
3.解决方案
这里写文章主要就放源代码,思路不会介绍的特别清楚,详细思路可以看评论区的b站讲解视频。
3.1 入口选择
通过不断尝试,最后发现一个兼具通用性和速度的方法。首先选择如下入口,通过微博自带的微博lite,点击在浏览器打开:

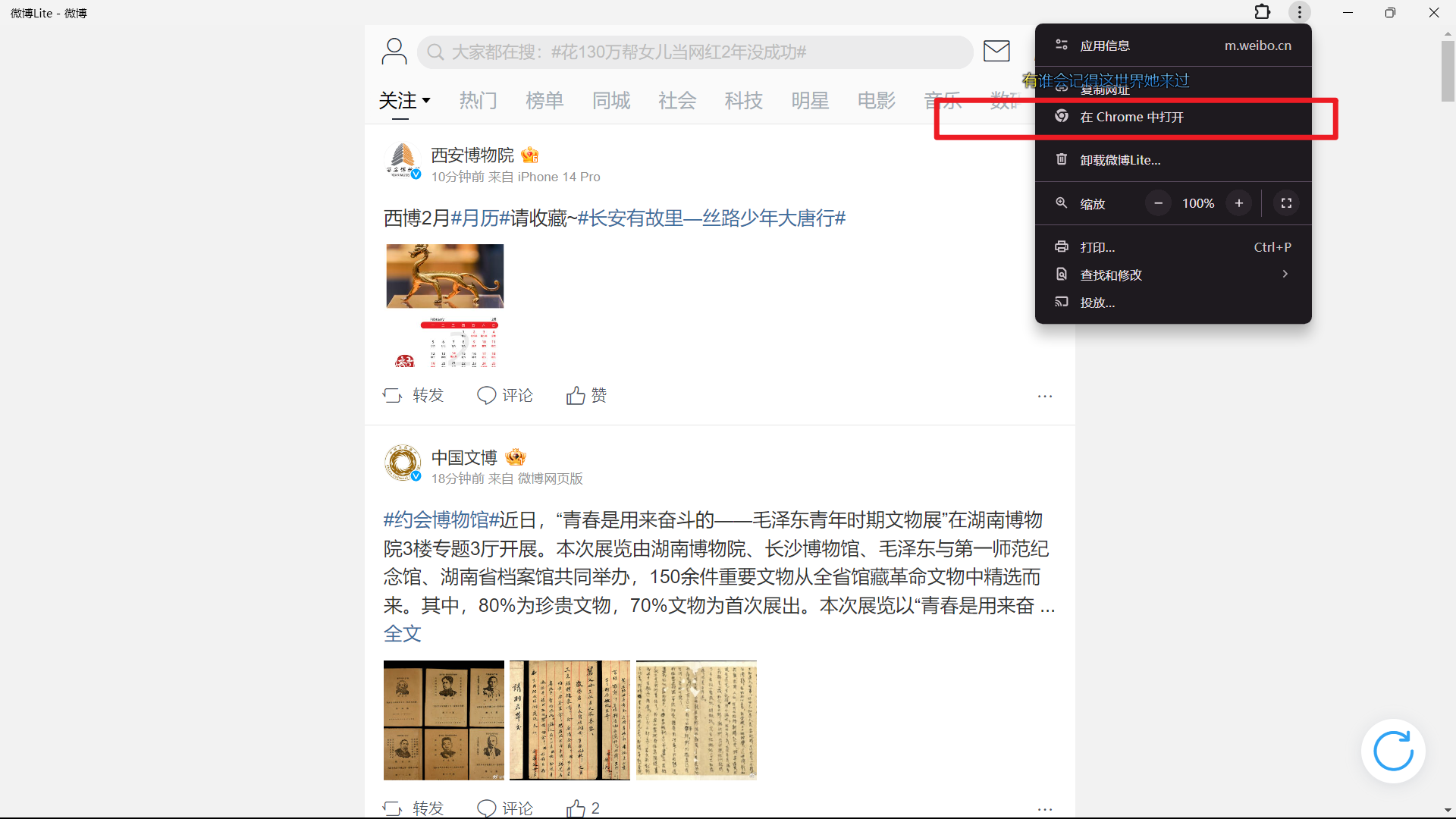
这个入口的优点是不需要登录就可以获取全部上述信息,因此也就省去了模拟登录的麻烦。接下来搜索对应用户的ID,便可以进入其主页:
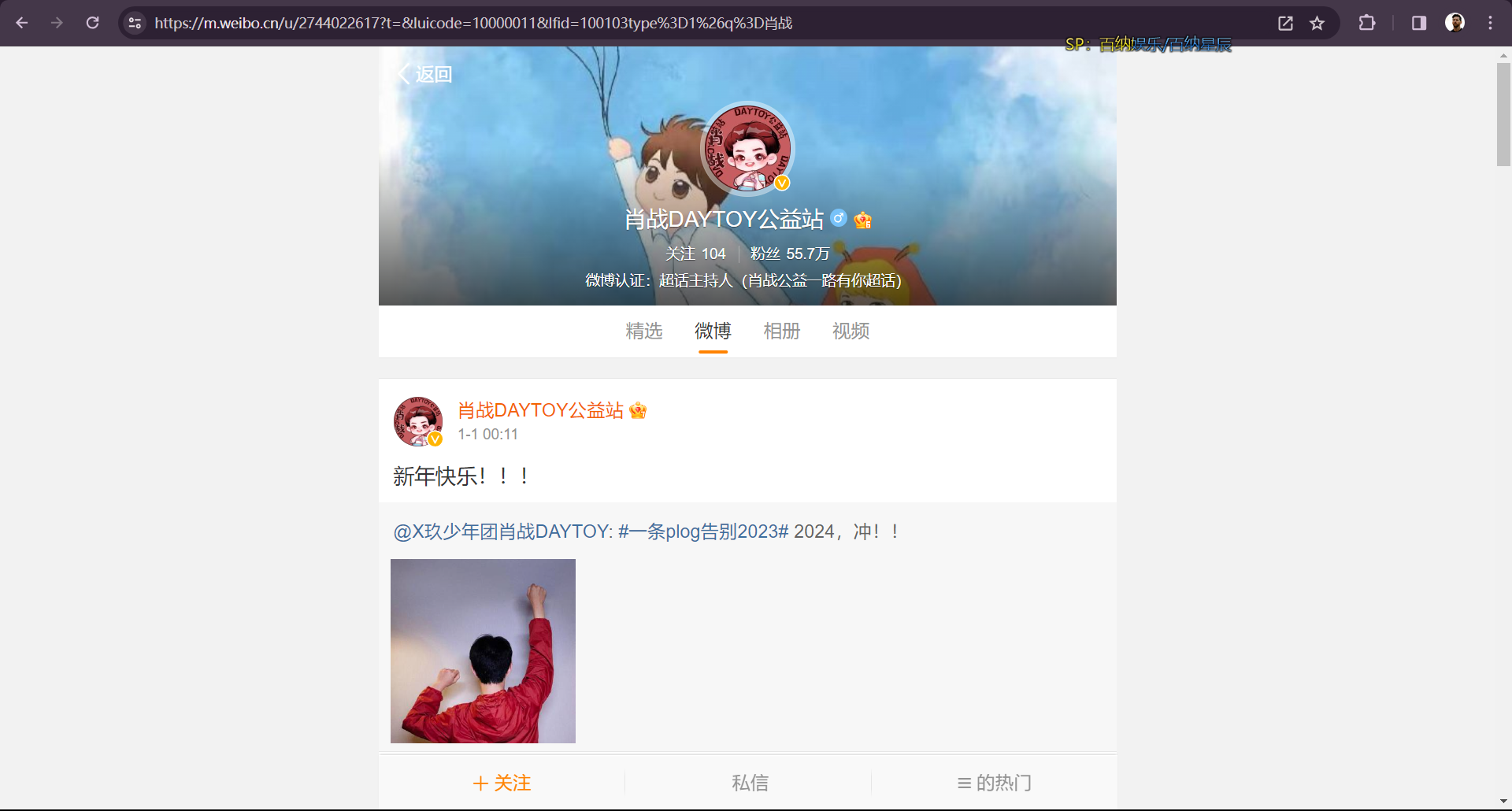
3.2 实现方法
可以发现每个用户所有发布的帖子都在上面的个人主页中,因此需要不断向下滑动以获取更多的数据。这种特点比较适合用selenium,通过模拟浏览器的滑动操作加时间判断便可以较为精准的得到指定时间内的帖子。那么下面就是源代码,一个函数,很简洁:
def getTiez 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











