







实验五 贝叶斯文本分析实战
一、实验内容
1. 问题描述
Kaggle上的比赛Bag of Words Meet Bags of Popcorn,其数据来自于国外一个类似豆瓣电影的影评网站IMDB,大概有十万条影评,其中包括正面评价和负面评价,用朴素贝叶斯估计算法对影评情感进行分类。
- 学会调用scikit-learn中的朴素贝叶斯方法,实现对电影评论文字的情感分类,分析预测结果性能。
- 结合自己编写的朴素贝叶斯方法,实现对电影评论文字的情感分类,分析预测结果性能,并与scikit-learn方法做比较。
- 思考如何提高分类准确率。
2. 数据集描述
标记数据集由 50,000 条 IMDB 电影评论组成,专门用于情感分析。评论的情绪是二元的,这意味着 IMDB 评分 < 5 的情绪评分为 0,评分 >=7 的情绪评分为 1。没有一部电影的评论超过 30 条。25,000 条评论标记的训练集不包括任何与 25,000 条评论测试集相同的电影。此外,还有 50,000 条没有任何评级标签的 IMDB 评论。
数据字段说明
| 字段 | 含义 |
|---|---|
| id | 每条评论的唯一ID |
| sentiment | 评论的情绪:1 表示正面评价,0 表示负面评价 |
| review | 评论的文本 |
文件说明
| 文件 | 说明 |
|---|---|
| labeledTrainData.tsv | **标记的训练集。**该文件以制表符分隔,并且有一个标题行,后跟 25000 行,其中包含每个评论的 id、情绪和文本。 |
| testData.tsv | **测试集。**制表符分隔的文件有一个标题行,后跟 25000 行,其中包含每个评论的 id 和文本。你的任务是预测每个人的情绪。 |
| unlabeledTrainData.tsv | **没有标签的额外训练集。**制表符分隔的文件有一个标题行,后跟 50000 行,其中包含每个评论的 id 和文本。 |
| sampleSubmission.csv | 格式正确的以逗号分隔的示例提交文件 |
| NB_model.csv | 输出的预测结果 |
训练集

测试集(没有情感标签)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-waXRtloR-1649823387841)(C:\Users\XUAN\AppData\Roaming\Typora\typora-user-images\image-20220411153507145.png)]](https://img-blog.csdnimg.cn/5ec8dcb4933845a9998808446dac2495.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6JO86Iy46JK_56yL,size_20,color_FFFFFF,t_70,g_se,x_16)
3. 实验环境(软硬件)
- 操作系统:
Windows 10 - IDE:
Pycharm Community Edition - Python环境:
Conda Python3.8 - sklearn环境:
sklearn 0.24.1
二、算法原理
1. 朴素贝叶斯分类算法
最大后验概率MAP
朴素贝叶斯法将实例分到后验概率最大的类中,这等价于期望风险最小化。由期望风险最小化得到后验概率最大化。
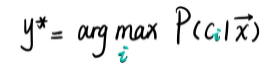
参数估计方法
方法主要是先估算出 先验概率P(Y=Ck) 和 条件概率P(X=x|Y=Ck) ,取使得 **后验概率P(Y=Ck)**最大时的Ck作为输出。根据方法采用的是贝叶斯估计还是极大似然函数,又分为两种方法。极大似然估计比较简单,就是利用统计的频率作为概率。但使用极大似然估计可能会出现所要估计的概率值为0的情况,可以采用贝叶斯估计避免。
贝叶斯估计
具体来说,对先验概率P(Y),分母和分母分别在极大似然估计的统计上加常数λ和Kλ,K表示分类标签数。对条件概率P(X|Y),分子和分母分别加λ和Sλ,S代表特征空间的维数。我们常取λ=1,这是称作拉普拉斯平滑。
(1)计算先验概率
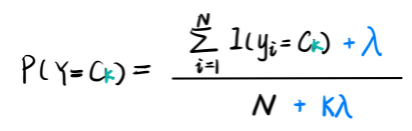
(2)计算条件概率

(3)计算后验概率,选择最大的

2. 特征创建方法
(1)Bag of words模型
Bag of words模型是信息检索领域常用的文档表示方法,它忽略了文档单词的顺序和语法、句法等要素,将其仅仅看做若干词汇的集合,文档中每个单词的出现都是独立的。本例子中,由于词汇很多,故人为设定词库单数为5000,不然计算量太大。
【举例说明】
现在数据集里有两个句子:
句子1:The cat sat on the hat
句子2:The dog ate the cat and the hat
词库就是:
{ the, cat, sat, on, hat, dog, ate, and }
Bag of words的词汇表vocabulary:
- 特征维数:词库的单词数
- 对应元素:该位置单词在该句子中出现的次数
句子1:{ 2, 1, 1, 1, 1, 0, 0, 0 }
句子2:{ 3, 1, 0, 0, 1, 1, 1, 1}
(2)TF-IDF模型——改进特征
在对在文本分类的特征创建方法改进时,采用 tf-idf 模型,即“词频-逆文本频率”模型,使用到TfidfVectorizer()函数,这个函数把词转换为向量。TFIDF 的主要思想是如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
(a)词频TF(Term Frequency)
定义:TF表示搜索词在每个文档中出现的频率。
**说明:为了进一步区分各类文档,需要计算这些搜索词在文档中出现的次数,我们将搜索词在文档中出现的频率称作词频TF,这个数字是对词数(Term Count)**的归一化,以防止它偏向长的文件(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否)。
如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。tf 计算公式如下:
𝑡
𝑓
𝑖
𝑗
=
𝑛
𝑖
𝑗
∑
k
𝑛
𝑘
j
𝑡𝑓_{𝑖𝑗} = \frac{𝑛_{𝑖𝑗}}{\sum_{k} 𝑛_{𝑘j}}
tfij=∑knkjnij
**缺点:**不能过滤终止词,比如a,an,the在文档中出现频率极高,因此被错误的强调赋予过高的权重,而没有给予真正有意义的术语足够的权重。
(b)逆文本频率IDF(Inverse Document Frequency)
定义:idf表示逆文本频率,表现一个词在所有文本中出现的频率,它是一个词语普遍重要性的度量。
说明:词语的特异性可以量化为其出现的文档数量的反函数。词语出现的文档数df的越大(反函数idf越小),说明对于区分各类文档越不重要。因此,idf是一个词的重要程度体现,越高越重要。如果一个词条在一个类的文档中频繁出现,说明该词条能够很好地代表这个类的文本特征,这样的词条应该赋予较高的权重,并选来作为该类文本的特征词以区别于其他类文档。idf计算公式如下:
𝑖
𝑑
𝑓
𝑖
𝑗
=
l
o
g
(
∣
𝐷
∣
1
+
∣
𝐷
𝑖
∣
)
𝑖𝑑𝑓_{𝑖𝑗} = log ( \frac{|𝐷|}{1 + |𝐷_𝑖|})
idfij=log(1+∣Di∣∣D∣)
*其中 |D|代表文档的总数,分母部分 |Di|则是代表文档集中含有i词的文档数。*原始公式是分母没有+1的,这里+1是采用了拉普拉斯平滑,避免了有部分新的词没有在语料库中出现而导致分母为零的情况出现。
**优点:**引入逆文档频率能够有效减少频繁出现的非术语词抢占的权重,增加了很少出现的词语的权重。
(c)TF-IDF
最后,把 TF 和 IDF 两个值相乘就可以得到TF-IDF 的值如下,把每个句子中每个词的 TF-IDF 值添加到向量表示出来,就是每个句子的 TF-IDF 特征。
𝑡
𝑓
∗
𝑖
𝑑
𝑓
(
𝑖
,
𝑗
)
=
𝑡
𝑓
𝑖
𝑗
∗
𝑖
𝑑
𝑓
𝑖
𝑗
=
𝑛
𝑖
𝑗
∑
k
𝑛
𝑘
j
∗
l
o
g
(
∣
𝐷
∣
1
+
∣
𝐷
𝑖
∣
)
𝑡𝑓 ∗ 𝑖𝑑𝑓(𝑖,𝑗) = 𝑡𝑓_{𝑖𝑗} * 𝑖𝑑𝑓_{𝑖𝑗} = \frac{𝑛_{𝑖𝑗}}{\sum_{k} 𝑛_{𝑘j}} * log ( \frac{|𝐷|}{1 + |𝐷_𝑖|})
tf∗idf(i,j)=tfij∗idfij=∑knkjnij∗log(1+∣Di∣∣D∣)
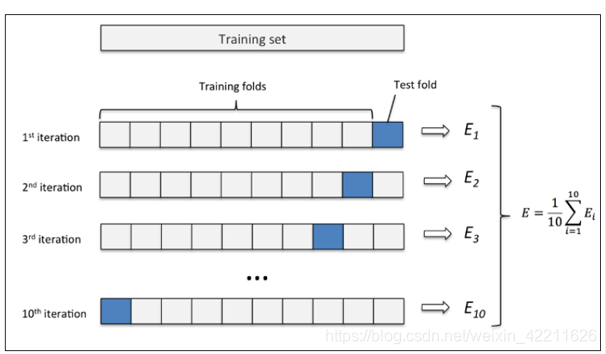
3. k折交叉验证
为了解决简单交叉验证的不足,提出k-fold交叉验证。
-
首先,将全部样本划分成k个大小相等的样本子集;
-
依次遍历这k个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行模型的训练和评估;
-
最后把k次评估指标的平均值作为最终的评估指标。在实际实验中,k通常取10。
三、代码分析
1. 流程图

处理流程:
- 提取特征数据集标签并向量化
- 选择合适的分类器构建模型
- 对模型进行验证
2. 代码
用到的库
import pandas as pd
from bs4 import BeautifulSoup # HTML
import re
import numpy as np
from sklearn.naive_bayes import MultinomialNB as MNB # 贝叶斯分类器
from sklearn.model_selection import cross_val_score # 交叉验证
from sklearn.feature_extraction.text import CountVectorizer # Bag of words
from sklearn.feature_extraction.text import TfidfVectorizer # TF-IDF
import nltk
nltk.find('.')
from nltk.book import *
from nltk.corpus import stopwords
(1)读取数据
train =pd.read_csv(r"labeledTrainData.tsv",header=0,delimiter="\t",quoting=3)
test = pd.read_csv(r"testData.tsv",header=0,delimiter="\t",quoting=3)
(2)数据清洗
观察所给数据,思考可以做哪些数据清洗?
1、使用强大的BeautifulSoup库去掉review中有一些HTML标签,之前学过爬虫有印象,例如<br/><br/> \\";
2、去掉标点符号等一些非文字符号,例如, ···。但是这也不是说一定得做的,比如现在一些常用的颜文字可能就很能表现出评论者的心态,比如颜文字(≧▽≦)/;
3、所有文本需要转换为小写词;
4、去掉stop words,它指一些经常出现的词,比如a,and,the等等,对统计文本情感没有太大意义,可以从nltk库中下载这些词。

数据清洗函数
def review_to_words(raw_review):
# 移除HTML
review_text = BeautifulSoup(raw_review).get_text()# 移除非文字部分(比如标点)
# 移除非文字部分
letters_only = re.sub("[^a-zA-Z]"," ", review_text)
# 转换为小写字母,并把所有词切开
words = letters_only.lower().split()
# Python中搜寻集合(set)要比列表(list)快,所以把stop words转换为集合
stops = set(stopwords.words("english"))
# 删除 stopword
meaningful_words = [w for w in words if not w in stops]
# 将筛分好的词合成一个字符串,并用空格隔开
words =" ".join(meaningful_words)
return words
主函数中调用
# 清洗训练集中的评论文本
clean_train_reviews = []
for i in range(0,len(train["review"])):
clean_train_reviews.append(review_to_words(train["review"][i])) # 调用函数清洗评论并填入新数组
# 清洗测试集中的评论文本
clean_test_reviews = []
for i in range(0,len(test["review"])):
clean_test_reviews.append(review_to_words(test["review"][i])) # Bag of words
(3)创造特征
方法一:Bag of words模型
使用sklearn中的CountVectorizer()函数,该函数只考虑每个单词出现的频率;然后构成一个特征矩阵,每一行表示一个训练文本的词频统计结果。其思想是,先根据所有训练文本,不考虑其出现顺序,只将训练文本中每个出现过的词汇单独视为一列特征,构成一个词汇表(vocabulary list)。
from sklearn.feature_extraction.text import CountVectorizer # Bag of words
CountVectorizer()参数说明:
| 参数 | 说明 | 赋值 |
|---|---|---|
| analyzer | 文本类型 | “word” |
| tokenizer | 划分词 | None |
| preprocessor | 预处理器 | None |
| stop_words | 停顿词 | None |
| max_features | 指定词库大小 | 5000 |
# Bag of words创造特征,设定词库大小为 5000
vectorizer = CountVectorizer(analyzer = "word",tokenizer = None,preprocessor=None,stop_words=None,max_features=5000)
# 训练集
train_data_features = vectorizer.fit_transform(clean_train_reviews)
train_data_features = train_data_features.toarray() # 转化为矩阵
# 测试集
test_data_features = vectorizer.fit_transform(clean_test_reviews)
test_data_features = test_data_features.toarray()
方法二:TF-IDF模型【改进特征】
sklearn中的TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer # TF-IDF
参数说明:
| 参数 | 说明 | 赋值 |
|---|---|---|
| min_df | 文档频率df最小值,忽略掉词频严格低于定阈值的词 | 1 |
| norm | 标准化词条向量所用的规范 | ‘l2’ |
| smooth_idf | 添加一个平滑idf权重,即idf的分母是否使用平滑,防止0权重 | True |
| use_idf | 启用idf你文档频率重新加权 | True |
| ngram_range | 同词袋模型 | (1,1) |
transform(raw_documents):把文档转换成词频矩阵(该文档中该特征词出现的频次),行是文档个数,列是特征词的个数。
# TF-IDF模型创造特征
tfidf = TfidfVectorizer(min_df=1,norm='l2',smooth_idf=True,use_idf=True,ngram_range=(1,1))
# 训练集fit_transform
train_data_features = tfidf.fit_transform(clean_train_reviews)
train_data_features = train_data_features.toarray() # 转化为矩阵
# 测试集transform
test_data_features = tfidf.transform(clean_test_reviews)
test_data_features = test_data_features.toarray()
(4)训练朴素贝叶斯分类器
方法一:使用scikit-learn库中的MultinomialNB模拟朴素贝叶斯分类
from sklearn.naive_bayes import MultinomialNB as MNB # 贝叶斯分类器
函数说明:MultinomialNB().model_NB.fit(特征,标签)
# 贝叶斯分类器预测
model_NB = MNB() # 创建贝叶斯器
model_NB.fit(train_data_features,train["sentiment"]) # 训练
方法二:使用自己写的朴素贝叶斯分类器
主函数
# 贝叶斯模型训练
prior_probability, conditional_probability = Train(train_data_features, train["sentiment"])
四个自定义函数:训练、二值化、预测、计算概率
### 训练函数
def Train(trainset,train_labels):
prior_probability = np.zeros(class_num) # 先验概率
conditional_probability = np.zeros((class_num,feature_len,2)) # 条件概率,三维(标记y,特征j,特征可能的取值0或1)
# 1. 计算先验概率(平滑公式4.11)
for i in range(class_num):
prior_probability[i] = (np.sum(train_labels == i) + 1) / (len(train_labels) + 10) # K=10
# 2. 计算条件概率(公式4.10)
# 统计联合概率,求分子
for i in range(len(train_labels)):
img = binaryzation(trainset[i]) # 图片特征二值化
label = train_labels[i] # 获取第i个样本的标记
# 第i个样本的第j个特征的值是0或1,计数
for j in range(feature_len):
conditional_probability[label][j][img[j]] += 1
# 求分母,遍历标签i(10个)
for i in range(class_num):
for j in range(feature_len):
P0 = conditional_probability[i][j][0] # 标签为i,第j个特征的值为0的个数
P1 = conditional_probability[i][j][1]
conditional_probability[i][j][0] = (P0 + 1) / (P0 + P1 + 2) # K=10,l=2
conditional_probability[i][j][1] = (P1 + 1) / (P0 + P1 + 2)
return prior_probability,conditional_probability
### 二值化函数
def binaryzation(img):
cv_img = img.astype(np.uint8)
cv2.threshold(cv_img,50,1,cv2.THRESH_BINARY_INV,cv_img)
return cv_img
### 预测函数
def Predict(testset,prior_probability,conditional_probability):
predict = []
for img in testset:
# 图像特征二值化
img = binaryzation(img)
# 进入循环前的初始化最大后验概率
max_label = 0
max_probability = calculate_probability(img,0)
# 遍历十个类别,找最大后验概率对应的类别
for j in range(1,10):
probability = calculate_probability(img,j)
# 发现大的概率就更新
if max_probability < probability:
max_label = j
max_probability = probability
# 填充每个样本的最大后验概率
predict.append(max_label)
return np.array(predict)
### 概率计算函数
def calculate_probability(img,label):
# 初始化p = 先验概率P(Y)
p = prior_probability[label]
# 累乘所有特征j的条件概率
for j in range(feature_len):
p*=conditional_probability[label][j][img[j]] # P(Y|X)=P(Y)*P(x1|Y)*P(x2|Y)···
return p
(5)进行k折交叉验证
sklearn.model_selection.cross_val_score()参数说明
| 参数 | 说明 | 赋值 |
|---|---|---|
| estimator | 需要使用交叉验证的算法(训练好的模型) | model_NB |
| X | 训练样本的特征 | train_data_features |
| y | 训练样本的标签 | train[“sentiment”] |
| cv | 交叉验证折数或可迭代的次数 | 20 |
| scoring | 交叉验证最重要的就是他的验证方式,选择不同的评价方法,会产生不同的评价结果。 | ‘roc_auc’ |
# K折交叉验证交叉验证训练集
score = np.mean(cross_val_score(model_NB,train_data_features,train["sentiment"],cv=20,scoring='roc_auc'))
print("多项式贝叶斯分类器20折交叉验证得分∶",score)
Bag of words模型交叉验证结果
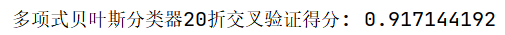
TF-IDF模型交叉验证结果
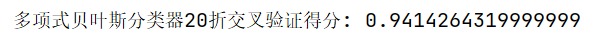
TF-IDF效果比Bag of words好
(6)测试集分类
# sklearn的贝叶斯预测结果
result = model_NB.predict(test_data_features)
output = pd.DataFrame( data={"id":test["id"],"sentiment":result} )
output.to_csv(r"NB_model.csv",index=False,quoting=3)
# 自己的贝叶斯预测结果
test_predict = Predict(test_data_features,prior_probability,conditional_probability)
output = pd.DataFrame(data={"id": test["id"], "sentiment": test_predict})# 输出.csv文件
output.to_csv(r"NB_model.csv", index=False, quoting=3)
3. 关键量变化过程
- 读取训练集和测试集数据,都有25000个样本(25000条评论),训练集有id,sentiment,reviews三维,测试集只有id,review两维。

-
查看清洗完成后的训练集和测试集,使用正则表达式或者BeautifulSoup等工具处理为dataframe格式

-
用两种方式创造特征,重点关注vocabulary_词典的变化情况
方法一:词袋模型
统计每个单词出现的频率,然后构成一个特征矩阵,每一行表示一个训练文本的词频统计结果。限定了词库大小5000,共有5000个单词。

训练集和测试集的词频统计结果如下,举例说明:第1条评论的第4267个单词出现了3次
方法二:TF-IDF模型
计算训练集TF-IDF,
fit_transform学习到一个字典vocabulary_idf逆文档频率矩阵
vocabulary_词库,
vocabulary_: dict类型

4. 特征创建成功,25000条评论,74047个特征
5. 交叉验证得分
6. 输出测试集25000条评论的分类结果

四、 总结
1. 遇到的问题与解决方法
安装nltk库
查询nltk的搜索路径
import nltk
nltk.find('.')
把文件夹放在指定搜索路径下
2. 知识点总结
(1) fit_transform()和transform()对比
-
测试集用
transform()transform(raw_documents):把文档转换成词频矩阵(该文档中该特征词出现的频次),行是文档个数,列是特征词的个数。 -
训练集用
fit_transform()fit_transform学习到一个字典,并返回Document-term的矩阵(即词典中的词在该文档中出现的频次)
(2) Pandas 数据结构 - DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
(3) CountVectorizer()和TfidfVectorizer()对比
CountVectorizer()函数只考虑每个单词出现的频率,然后构成一个特征矩阵,每一行表示一个训练文本的词频统计结果。TfidfVectorizer()基于tf-idf算法。此算法包括两部分tf和idf,两者相乘得到tf-idf算法。tf算法统计某训练文本中,某个词的出现次数。idf算法,用于调整词频的权重系数,如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。
3. 算法的思考
我认为决定该算法性能的主要因素是:如何有效的进行文本特征的提取。提取文本特征一般有三种常用的模型:词袋模型、TF-IDF、word2vector。
TF-IDF模型
fit_transform学习到一个字典,并返回Document-term的矩阵(即词典中的词在该文档中出现的频次)。
TfidfVectorizer.fit_transform(raw_document) = TfidfTransformer.fit(X).transform(X)
fit步骤学习idf_vector,一个全局的词权重_idf_diag。输入的X是一个稀疏矩阵,行是样本数,列是特征数。
transform步骤是把X这个计数矩阵转换成tf-idf表示, X = X * self._idf_diag,然后进行归一化。
word2vector模型
word2vector是深度网络的一种应用。基本含义为把每个词语映射成一个高纬空间的向量,词义或词性相近的词语映射成的向量比较接近。
算法。此算法包括两部分tf和idf,两者相乘得到tf-idf算法。tf算法统计某训练文本中,某个词的出现次数。idf算法,用于调整词频的权重系数,如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。
3. 算法的思考
我认为决定该算法性能的主要因素是:如何有效的进行文本特征的提取。提取文本特征一般有三种常用的模型:词袋模型、TF-IDF、word2vector。
TF-IDF模型
fit_transform学习到一个字典,并返回Document-term的矩阵(即词典中的词在该文档中出现的频次)。
TfidfVectorizer.fit_transform(raw_document) = TfidfTransformer.fit(X).transform(X)
fit步骤学习idf_vector,一个全局的词权重_idf_diag。输入的X是一个稀疏矩阵,行是样本数,列是特征数。
transform步骤是把X这个计数矩阵转换成tf-idf表示, X = X * self._idf_diag,然后进行归一化。
word2vector模型
word2vector是深度网络的一种应用。基本含义为把每个词语映射成一个高纬空间的向量,词义或词性相近的词语映射成的向量比较接近。















 6244
6244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









