






前言:
MySQL所使用的SQL语言是用于访问数据库的最常用的标准化语言,它是一个关系型数据库,这里,我来记录在终端对数据库的一些操作。
数据库与MySQL
数据库
什么是数据库(database)?
数据库就是用于存储和管理数据的仓库。
一般我们存储数据,会有如下:
- 存储于内存:临时性数据,程序结束则数据会被释放。
- 存储于文件(数据序列化)
数据库的特点?
- 持久化存储数据(存储于文件中),其实数据库就是一个文件系统
- 方便存储和管理数据
- 使用了统一的方式操作数据库(SQL)
常见的数据库软件
- Oracle数据库(有个Oracle公司,对,就是Java的后爹,别弄混了)
- MySQL
- Microsoft SQL Server
- DB2(IBM公司的数据库产品,常用于银行系统)
- ……
MySQL
MySQL现在也是Oracle公司的产品,非常强大的数据库软件
MySQL的卸载
MySQL的卸载得稍微注意一下,如果卸载不干净,那么你将很烦。
- 去MySQL的安装目录找到my.ini文件(配置文件),复制datadir(我的例子是:datadir=C:/ProgramData/MySQL/MySQL Server 8.0/Data)
- 然后通过控制面板卸载MySQL,这时并没有卸载干净
- 然后将MySQL目录彻底删除(按我的例子:即删除C:/ProgramData/MySQL)
这样就真正卸载了。
MySQL的目录结构
MySQL的目录结构
- MySQL的安装目录
- MySQL的数据目录
MySQL的安装目录
MySQL的安装目录在你安装MySQL的时候应该是会让你去选择的,目录结构中有几个重要目录,这里简单介绍:
- bin:放着二进制的可执行文件(你的MySQL配置环境变量应该要指向这个目录才能成功,因为mysql命令就是要执行bin/mysql.exe)
- data:存放MySQL的一些数据文件
- include:存放C语言的一些头文件信息
- lib:存放MySQL运行需要的一些链接文件
- share:存放MySQL运行的错误信息
MySQL的数据目录
默认MySQL的数据目录在C:/ProgramData/MySQL/MySQL Server 8.0/Data,没错就是我们卸载MySQL的时候需要手动删除的目录。
ProgramData一般是一个隐藏目录
主要存放MySQL的数据
准备工作:
安装MySQL,并对路径配置环境变量
⇒这里有个我用的安装包,有需要就拿去MySQL
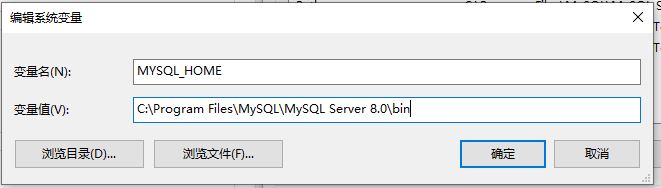
~尽量不要学我安装到C盘~
然后在Path中添加 %MYSQL_HOME% 即可
在services中开启服务

打开cmd窗口输入mysql

如此显示,则配置成功
SQL
SQL概念
SQL是三个单词的缩写:Structured Query Language---结构化查询语言
其实就是定义了操作所有关系型数据库的规则。
不同数据库操作的一点点不一样的地方,我们称为“方言”
SQL语句通用语法
- SQL语句可以单行或多行书写,以分号结尾
- 可使用空格和缩进来增强语句的可读性
- MySQL数据库的SQL语句不区分大小写,但是建议关键字使用大写
- 3中注释方法:
- 单行注释:-- (--后面有个空格,注意)
- 单行注释:# (MySQL特有)
- 多行注释:/* */
SQL分类
DDL(Data Definition Language)数据定义语言
用来定义数据库对象,例如数据库、表、列等。
关键字:CREATE、DROP、ALTER等
DML(Data Manipulation Language)数据操作语言
用来对数据库中表的数据进行增删改。
关键字:INSERT、DELETE、UPDATE等
DQL(Data Query Language)数据查询语言
用来查询数据库中表的记录(数据)。
关键字:SELECT、WHERE 等
DCL(Data Control Language)数据控制语言(了解)
用来定义数据库的访问权限和安全级别,及创建用户。
关键字:GRANT、REVOKE等

MySQL字符类型:
基础学习:
登录数据库:
在终端输入如下命令即可登录本机数据库
mysql -uroot -p123-u后面跟用户名(username)
-p后面跟密码(password)
退出数据库操作:
退出数据库的操作界面,回到cmd端
mysql > exit;
mysql > quit;
mysql > \q;查询已有数据库:
查询数据库中已经存在的数据库
show databases;注意:一定要有分号
+——————–+
| Database |
+——————–+
| blog |
| information_schema |
| myfirsttest |
| mysql |
| performance_schema |
选择数据库从而进行操作:
use 数据库名Database changed
查看已有表:
选中数据库后,输入如下代码:
show tables;+———————–+
| Tables_in_myfirsttest |
+———————–+
| user_name |
+———————–+
查看表内所有内容:
select * from 表名;+—-+———-+————–+———————+
| ID | ADMIN | PASSWORD | DATE |
+—-+———-+————–+———————+
| 1 | batman | 1199 | 2019-11-05 19:30:38 |
| 2 | superman | 2200 | 2019-11-05 19:30:38
有条件的查看:
select * from user_name where ID=1;+—-+——–+———-+———————+
| ID | ADMIN | PASSWORD | DATE |
+—-+——–+———-+———————+
| 1 | batman | 1199 | 2019-11-05 19:30:38 |
数据库服务器中创建数据库:
在登录数据库后,输入如下命令来创建数据库
create database 数据库名;创建数据表:
大致格式如下:
CREATE TABLE pet (
name VARCHAR(20),
sex CHAR(1),
birth DATE);剖析一下,就是这样:
CREATE TABLE 表名(
字段1 字段1类型,
字段2 字段2类型,
字段3 字段3类型);查看数据表的具体结构:
输入如下命令:
describe 表名+——-+————-+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+——-+————-+——+—–+———+——-+
| name | varchar(20)| YES | | NULL | |
| sex | char(1) | YES | | NULL | |
| birth | date | YES | | NULL | |
+——-+————-+——+—–+———+——-+
给数据表插入信息:
大致格式如下:
INSERT INTO pet
VALUES ('dudu','f','1999-03-30');剖析一下就是这样:
INSERT INTO 表名
VALUES ('对应类型的对应信息','对应类型的对应信息','对应类型的对应信息');+——+——-+——+
| name | sex | birth |
+——+——-+——+
| dudu | f | 1999-03-30 |
+——+——-+——+
删除表:
删除数据表
DROP TABLE 表名
给数据表删除信息:
删除某一条:
delete from 表名 where 条件;例如此表:
+—-+———-+——+——+
| id | name | age | info |
+—-+———-+——+——+
| 2 | 变体精灵 | 11 | 牛逼 |
| 6 | 熊猫人 | 34 | 凶恶 |
| 7 | 恶魔猎手 | 21 | 敏捷 |
+—-+———-+——+——+
使用命令:
delete from hero where name='熊猫人';
之后即:
+—-+———-+——+——+
| id | name | age | info |
+—-+———-+——+——+
| 2 | 变体精灵 | 11 | 牛逼 |
| 7 | 恶魔猎手 | 21 | 敏捷 |
+—-+———-+——+——+
给数据表修改信息:
修改某一信息:
update 表名 set 字段=新值 where 字段=旧值;旧值和新值并不在同一位置,旧值只是为了方便索引到某一行
例如:
+—-+———-+——+——+
| id | name | age | info |
+—-+———-+——+——+
| 2 | 变体精灵 | 11 | 牛逼 |
| 7 | 恶魔猎手 | 21 | 敏捷 |
+—-+———-+——+——+
update hero set name="水人" where info='牛逼';之后:
+—-+———-+——+——+
| id | name | age | info |
+—-+———-+——+——+
| 2 | 水人 | 11 | 牛逼 |
| 7 | 恶魔猎手 | 21 | 敏捷 |
+—-+———-+——+——+
约束:
概念:
MySQL创建数据表的时候,对字段进行的一些约束条件
主要有:
- 主键约束: primary_key
- 自增约束: auto_increment
- 外键约束: foreign references
- 唯一约束: unique
- 非空约束: not_null
- 默认约束: default
通常是在创建数据表的时候给字段进行约束:
CREATE TABLE 表名(
字段1 字段1类型 约束关键字,
字段2 字段2类型 约束关键字,
字段3 字段3类型
);
主键约束(primary_key):
给字段添加主键约束,将会使得该字段不重复,不为空,让记录唯一。
create table admin(
id int primary key,
name varchar(20)
);然后输入命令:describe admin;
可以看到:
+——-+————-+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+——-+————-+——+—–+———+——-+
| id | int(11) | NO | PRI | NULL | |
| name |varchar(20)| YES | | NULL | |
+——-+————-+——+—–+———+——-+
这时我们就不能添加两个ID相同的数据了,也不能建数据设置ID为NULL。
联合主键:
create table user2(
id int,
name varchar(20),
password varchar(20),
primary key(id,name)
); 如此一来,要求 id+name 的值不能重复,而id或name都不能为NULL。
例如表中有数据 1——小王——12345,
则不能再加入 1——小王——23456,
但可以加入 1——小张——98765 或者 2——小王——34534。(联合主键主要应用于多对多的关系结构上)
自增约束(auto_increment):
自增约束常常与主键约束一起使用。
创建一个字段id具有主键约束和自增约束的表
create table admin(
id int primary key auto_increment,
name varchar(20)
);使用命令describe admin;查看字段属性
+——-+————-+——+—–+———+—————-+
| Field | Type | Null | Key | Default | Extra |
+——-+————-+——+—–+———+—————-+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20)| YES | | NULL | |
+——-+————-+——+—–+———+—————-+
接下来指定字段插入两条数据:
insert into admin (name) value('张雪');
insert into admin (name) value('李获');然后select * from admin;
+—-+——+
| id | name |
+—-+——+
| 1 | 张雪 |
| 2 | 李获 |
+—-+——+
修改字段的约束:
alter:更改,修改
增加约束——add:
alter table 表名 add primary key(字段);例如:
alter table admin add primary key(id);即给id增加了主键约束
删除约束——drop:
而要删除主键约束:
alter table 表名 drop primary key;例如:
alter table admin drop primary key;修改约束——modify:
modify可以重置字段属性
修改主键约束(通过修改字段属性):
alter table 表名 modify 字段 字段类型 约束;例如:
alter table admin modify id int primary key;唯一约束(unique):
约束字段的值不可以重复。
create table admin(
id int,
name varchar(20) unique
);或者
create table admin(
id int,
name varchar(20),
unique(name)
);使用命令desc admin;(这里的describe简写了,也是可以正常运行的)
+——-+————-+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+——-+————-+——+—–+———+——-+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | UNI | NULL | |
+——-+————-+——+—–+———+——-+
若要删除唯一约束:
alter table admin drop index name;如果不加index会把整个name字段删除
当使用联合命令赋予unique:
create table admin(
id int,
name varchar(20),
unique(id,name)
);然后describe会变成这样:
+——-+————-+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+——-+————-+——+—–+———+——-+
| id | int(11) | YES | MUL | NULL | |
| name | varchar(20)|YES| | NULL | |
+——-+————-+——+—–+———+——-+
类似于联合主键,id+unique 不重复即可
非空约束(not_null):
create table admin(
id int,
name varchar(20) not null
);使用describe:
+——-+————-+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+——-+————-+——+—–+———+——-+
| id | int(11) | YES | | NULL | |
| name | varchar(20)| NO | | NULL | |
+——-+————-+——+—–+———+——-+
默认约束(default) :
在插入字段值的时候,若没有传入具体值,就会传入默认值
create table admin(
id int,
name varchar(20),
age int default 10
);使用desc查看:
+——-+————-+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+——-+————-+——+—–+———+——-+
| id | int(11) | YES | | NULL | |
| name | varchar(20)| YES | | NULL | |
| age | int(11) | YES | | 10 | |
+——-+————-+——+—–+———+——-+
之后我们插入元素的话,若没有给age赋值,则age使用10;
外键约束(foreign references):
外键约束是涉及两个表的约束——主表(父表)、副表(子表)
主表中的数据被副表所引用,所以在添加和删除数据时有了限制
例如,创建表 world
create table world(
id int primary key,
name varchar(20) unique
);再创建表hero
create table hero(
id int primary key,
name varchar(20),
address varchar(20),
foreign key(address) references world(name)
);foreign key(address) references world(name)这一句即实现了将表内的address字段与外表world的name字段关联,这样一来,hero则为副表,world则为主表,hero的增删中的信息的address值必须在world的name值中有所对应。
注意,创建主表的时候,关联字段必须要有唯一性,如world中的name有unique约束
接下来我们继续,给world里添加了一些信息:
+—-+——–+
| id | name |
+—-+——–+
| 1 | 中国 |
| 3 | 俄罗斯|
| 2 | 美国 |
+—-+——–+
然后我们给hero添加信息:
//可以顺利添加
insert into hero values(1,"孙悟空","中国");//不能顺利添加
insert into hero values(2,"苏菲玛索","法国");这就是因为有外键约束,在world中没有”法国”
另一方面:
此时在子表中有 1——孙悟空——中国 的信息,我们如果使用如下命令删除world中的 1——中国
delete from world where id=1;就会报错,因为 1——中国 还在作为关联中
第一部分就先写到这里了,把你的想法留言到下面吧
希望对你有帮助
欢迎访问我的博客:is-hash.com
商业转载 请联系作者获得授权,非商业转载 请标明出处,谢谢















 882
882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











