







Network Applications of Bloom Filters: A Survey
* Authors: Andrei Broder, Michael Mitzenmacher
阅读内容总结
1 论文摘要(Abstract)
Bloom filter是一个简单的空间高效的随机数据结构,用于表示支持成员查询的集合。Bloom 过滤器允许误报,在控制错误的概率的条件下,节省空间的优势可以一定克服这个缺点。自 1970 年代以来,Bloom filter已被用于数据库应用程序,但直到最近几年,它们在网络文献中变得流行。本文的目的是调查Bloom filter在各种网络问题中已经被使用和改进的方式,目的是提供一个统一的数学和实用的框架来理解它们,并刺激它们在未来应用中的使用。
2 研究动机(Motivation/Introduction)
Burton Bloom 在 1970 年代引入了 Bloom filter这一概念,从那时起它们在数据库应用程序中非常流行,最近(2004)在网络中的应用更加广泛。
主要工作如下:
1. 描述了Bloom filter背后的数学结构和历史以及一些重要的变体;
2. 考虑研究了Bloom filter与网络相关的四种应用:
1. 帮助覆盖性网络和端到端网络的协作;
2. 提供资源设备的概率性路由算法;
3. 提供包的加速路由;
4. 为测量基础设施提供了有用的工具,用于在路由器或其他网络设备中创建数据摘要
需要注意,作者的这种分类是不够严格的,很多应用往往符合于多种类别的应用。
3. 这些不同应用程序的统一主题是,Bloom filter提供了一种简洁的方式来表示一个集合或一个链表。网络中的许多地方都有保存链表的需求,然而完整的表会消耗太多空间;Bloom filter引入误报为代价,提供了一种可以显著减少空间的表示方法。
Bloom filter的主要适用原则:
1. 使用链表或集合,空间的费用高;
2. 误报的影响是可以减轻的或者忽略
3 符号系统(Notation)
4 结论(Conclusion)
Bloom 过滤器是集合的简单空间高效表示或处理成员查询的列表。
有许多网络问题中都需要这样的数据结构。当存储空间是主要限制时,Bloom filter可能是保留显式列表的绝佳替代方案。Bloom filter的缺点是误报。必须仔细考虑每个特定应用程序的影响,以确定误报的影响是否可接受。
The Bloom filter principle: Wherever a list or set is used, and space is at a premium, consider using a Bloom filter if the effect of false positives can be mitigated.
5 主体工作
5.1 Bloom filter 的数学基础
5.1.1 标准的Bloom Filter
假设待检测(表示)的集合为
S
=
x
1
,
x
2
,
.
.
.
,
x
n
S={x_1,x_2,...,x_n}
S=x1,x2,...,xn
采用具有
m
m
m个二进制位的连续数组存储,初始时设置为0;
采用
k
k
k个相互独立的取值范围为
1
,
.
.
.
,
m
{1,...,m}
1,...,m的哈希函数
h
1
−
h
k
h_1-h_k
h1−hk寻址;
检测和误报示例:假设
x
1
x_1
x1和
x
2
x_2
x2在集合中,以
y
1
y_1
y1和
y
2
y_2
y2进行检测,由于
y
1
y_1
y1对应的哈希值中存在0所以检测成功,但
y
2
y_2
y2的哈希对应值均为1,因此产生误报。如下图:
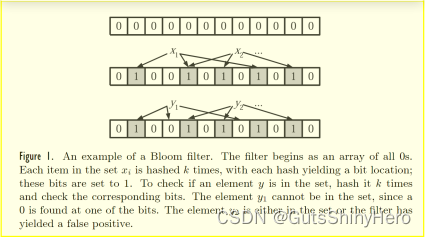
为了避免关于哈希映射的复杂讨论,假设
k
n
<
m
kn<m
kn<m,即集合中每个值对应的哈希值的位置充足。
在随机哈希的条件下,S中元素都被映射后,Bloom filter中的某一位置上元素仍是0的概率是:
p ′ = ( 1 − 1 m ) k n ≈ e − k n m p'=\bigg( 1-\frac{1}{m}\bigg)^{kn}\approx e^{-\frac{kn}{m}} p′=(1−m1)kn≈e−mkn
令 p p p为该近似值,这一值与原值相比比较方便数学计算,而且二者在余项 O ( 1 / m ) O(1/m) O(1/m)下近似,当 m m m较大时差距很小。
设 ρ ρ ρ为所有n个元素插入表后0位所占比例,则 ρ ρ ρ的期望值为 E ( ρ ) = p ′ E(ρ)=p' E(ρ)=p′
因此,整个表的误报率为:
(
1
−
ρ
)
k
≈
(
1
−
p
′
)
k
≈
(
1
−
p
)
k
(1-ρ)^k \approx (1-p')^k\approx(1-p)^k
(1−ρ)k≈(1−p′)k≈(1−p)k
接下来进行第二步讨论:令
f
′
=
(
1
−
(
1
−
1
m
)
k
n
)
k
=
(
1
−
p
′
)
k
f
=
(
1
−
e
−
k
n
m
)
=
(
1
−
p
)
k
\begin{gather} f'=\bigg(1- \bigg( 1-\frac{1}{m}\bigg)^{kn}\bigg)^k=(1-p')^k \\ f= \big(1-e^{-\frac{kn}{m}}\big)=(1-p)^k\end{gather}
f′=(1−(1−m1)kn)k=(1−p′)kf=(1−e−mkn)=(1−p)k
值得注意的是,有时Bloom filter的描述略有不同:不是在所有哈希函数中共享一个大小为
m
m
m的数组,而是每个哈希函数具有
m
/
k
m/k
m/k的连续位置范围,这些位置与所有其他位置不相交。总比特数仍然是
m
m
m,但是这些比特在
k
k
k个哈希函数中被平均分配。
所以在插入所有元素后,表中某位置为0的概率实际上是:
(
1
−
k
m
)
n
≈
e
−
k
n
m
\bigg( 1-\frac{k}{m}\bigg)^{n}\approx e^{-\frac{kn}{m}}
(1−mk)n≈e−mkn
注意到改变后的近似与改变前的近似相同,这是因为
(
1
−
k
m
)
n
≤
(
1
−
1
m
)
k
n
\bigg( 1-\frac{k}{m}\bigg)^{n}\le \bigg( 1-\frac{1}{m}\bigg)^{kn}
(1−mk)n≤(1−m1)kn
所以用该近似进行误报率估计,得出的值只会比实际值大而不会小于实际值。
接下来,假设给定m和n,我们希望优化哈希函数的个数k,有两种相反的方向:
1. 用更多的哈希函数让我们有更多的0位置留给不在集合中的外部元素,避免误报;
2. 用更少的哈希函数来让误报率减少,这一值可以通过对f求导而简单求得:
令
f
=
e
x
p
(
k
×
l
n
(
1
−
e
−
k
n
m
)
)
f=exp(k\times ln(1-e^{-\frac{kn}{m}}))
f=exp(k×ln(1−e−mkn))
设定:
g
=
k
×
l
n
(
1
−
e
−
k
n
m
)
g=k\times ln(1-e^{-\frac{kn}{m}})
g=k×ln(1−e−mkn)
最小化
f
f
f实际上就是最小化
g
g
g,因此对
g
g
g求导得到
∂
g
∂
k
=
l
n
(
1
−
e
−
k
n
m
)
+
k
n
m
e
−
k
n
m
1
−
e
−
k
n
m
\frac {\partial g}{\partial k}=ln(1-e^{-\frac{kn}{m}})+\frac{kn}{m}\frac{e^{-\frac{kn}{m}}}{1-e^{-\frac{kn}{m}}}
∂k∂g=ln(1−e−mkn)+mkn1−e−mkne−mkn
可以得到两个明显的零点,0和
l
n
2
∗
(
m
/
n
)
ln 2*(m/n)
ln2∗(m/n),或者,令
p
=
e
−
k
n
/
m
p=e^{-kn/m}
p=e−kn/m,
g
=
−
m
n
l
n
(
p
)
l
n
(
1
−
p
)
g=-\frac{m}{n}ln(p)ln(1-p)
g=−nmln(p)ln(1−p)
由对称性可知,最小值在
p
=
1
/
2
p=1/2
p=1/2,
k
=
l
n
2
∗
(
m
/
n
)
k=ln 2 *(m/n)
k=ln2∗(m/n)时取得,此时
f
=
(
1
/
2
)
k
≈
(
0.6185
)
m
/
n
f=(1/2)^k\approx (0.6185)^m/n
f=(1/2)k≈(0.6185)m/n。
在实践中,
k
k
k必须是一个整数,并且更小的次优
k
k
k可能是首选,因为这减少了必须计算的哈希函数的数量。
注意到,
p
=
1
/
2
p=1/2
p=1/2时取到最值,这一结果与是否进行近似取值无关,在上述推理下,如果不取p为近似则
g
′
=
1
n
l
n
(
1
−
1
/
m
)
l
n
(
p
′
)
l
n
(
1
−
p
′
)
g'=\frac{1}{nln(1-1/m)}ln(p')ln(1-p')
g′=nln(1−1/m)1ln(p′)ln(1−p′)
此时1/2仍是极值点。
另外,需要注意在任何实际的例子中,0的比例实际上不等于
p
’
p’
p’或其近似
p
p
p,这一值只依赖于具体的哈希函数计 算,
p
’
p’
p’只是一种期望值,在实际中如果0的比例越小那么误报率就会变大。
精确讨论:
如果 X 是一个随机变量,对应于 Bloom 过滤器中 0 位的数量,那么用霍夫丁不等式可以证明:
P
(
∣
X
−
p
′
m
∣
≥
ε
m
)
≤
2
e
−
2
ε
2
m
2
/
n
k
\mathbb{P}(|X-p'm|\ge \varepsilon m)\le 2e^{-2\varepsilon^2m^2/nk}
P(∣X−p′m∣≥εm)≤2e−2ε2m2/nk
实际上揭示了,0占比的实际值与估计值之间的差距在一定范围内,这对应于一个直观的想法,即当一个位设置为 1 时,它(轻微)降低了彼此位设置为 1 的概率。
在一些特殊的Bloom filter中0的占比不严格等于
p
′
p'
p′,但是当
m
m
m足够大时,会非常接近
p
‘
p‘
p‘,这确保了使用这一变量的正确性。
5.1.2 确定数组大小m的下界
确定Bloom过滤器的效率的一种方法是考虑需要多少位
m
m
m来表示所有
n
n
n个元素的集合,从而允许对宇宙中最多
ε
\varepsilon
ε比例的假阳性,但不允许假阴性。
假设,我们需要表示的全集个数为
u
u
u,那么必须将
m
m
m位的字符串与全集中可能出现的
(
u
n
)
\binom{u}{n}
(nu)中可能的元素集合相关联。设
F
(
X
)
F(X)
F(X)为我们用于表示集合
X
X
X的字符串,如果
m
m
m位的字符串
s
s
s与包含
x
x
x的
X
X
X的
F
(
X
)
F(X)
F(X)相同,则称
s
s
s接受元素
x
x
x,即全集中有一些集合包含
x
x
x而
s
s
s是代表性字符串,否则称s
拒绝
拒绝
拒绝
x
x
x.直观地说,如果
s
s
s接受
x
x
x,那么给定 s,我们应该得出结论生成的
s
s
s包含
x
x
x 的集合,如果
s
s
s 拒绝
x
x
x,我们可以确保生成的
x
x
x 不包含在
s
s
s 的集合中。
现在假设
X
X
X中有
n
n
n个元素,
s
s
s串用于表示集合
X
X
X,那么s必须接受
X
X
X中所有元素并且在最大误报率
ε
\varepsilon
ε下,可能接受
ε
(
u
−
n
)
\varepsilon (u-n)
ε(u−n)个
X
X
X集合外的元素。因此,每个
s
s
s可能接受元素个数最多为
n
+
ε
(
u
−
n
)
n+\varepsilon (u-n)
n+ε(u−n),所以s串应该要能表示任何元素个数为
n
n
n的
(
n
+
ε
(
u
−
n
)
n
)
\binom {n+\varepsilon (u-n)}{n}
(nn+ε(u−n))的子集,但它不能用于表示任何其他集合。
假设使用m位字符串,那么应该有如下不等式:
2
m
(
n
+
ε
(
u
−
n
)
n
)
≥
(
u
n
)
2^m\binom {n+\varepsilon (u-n)}{n}\ge \binom {u}{n}
2m(nn+ε(u−n))≥(nu)
即
m
≥
l
o
g
2
(
u
n
)
(
n
+
ε
(
u
−
n
)
n
)
≈
l
o
g
2
(
u
n
)
(
ε
u
n
)
≥
l
o
g
2
ε
−
n
=
n
l
o
g
2
(
1
/
ε
)
m\ge log_2 \frac{\binom {u}{n}}{\binom {n+\varepsilon (u-n)}{n}}\approx log_2\frac{\binom {u}{n}}{\binom {\varepsilon u}{n}}\ge log_2\varepsilon^{-n}=nlog_2(1/\varepsilon)
m≥log2(nn+ε(u−n))(nu)≈log2(nεu)(nu)≥log2ε−n=nlog2(1/ε)
这一近似在
ε
u
>
>
n
\varepsilon u>>n
εu>>n时成立,这在实际应用中很常见。
因而现在m的下界就是
n
l
o
g
2
(
1
/
ε
)
nlog_2(1/\varepsilon)
nlog2(1/ε),在之前对k的讨论中有
f
=
(
1
/
2
)
k
≥
(
1
/
2
)
m
l
n
2
/
n
f=(1/2)^k\ge(1/2)^{mln2/n}
f=(1/2)k≥(1/2)mln2/n,如果要求最终误报率
f
≤
ε
f\le \varepsilon
f≤ε,则有
m
≥
n
l
o
g
2
(
1
/
ε
)
l
n
2
=
n
l
o
g
2
e
⋅
l
o
g
2
(
1
/
ε
)
m\ge n \frac{log_2(1/\varepsilon)}{ln2}=nlog_2e \cdot log_2(1/\varepsilon)
m≥nln2log2(1/ε)=nlog2e⋅log2(1/ε)
m下界值以
l
o
g
2
e
log_2e
log2e为参数值。如果令
n
j
=
m
nj=m
nj=m的话,最佳的BLoom filter将产生
(
0.6185
)
j
(0.6185)^j
(0.6185)j的误报率,而下限错误率仅为
(
0.5
)
j
(0.5)^j
(0.5)j
有一些比较复杂的方案能在不改变误报率的情况下降低Bloom filter的空间占用,如压缩 Bloom filter和基于完美散列的技术。
5.1.3 哈希与Bloom filter对比
哈希是表示集合最常见的方法之一。集合的每个项目都被散列为
Θ
(
l
o
g
n
)
Θ(log n)
Θ(logn) 位,哈希值的(排 序)列表然后表示集合。这种方法产生非常小的错误概率。例如,每个集合元素使用
2
l
o
g
2
n
2 log_2 n
2log2n 位, 两个不同元素产生相同哈希值的概率为
1
/
n
2
1/n^2
1/n2。因此,集合中任何元素与集合中某个哈希值匹配 的概率在标准联合界最多为
n
/
n
2
=
1
/
n
n/n^2 = 1/n
n/n2=1/n。
Bloom 过滤器可以解释为散列的自然泛化,它允许在每个集合元素使用的比特数和误报的概 率之间更有趣的权衡。(事实上,只有一个哈希函数的Bloom过滤器等价于普通散列。)即使每个集 合元素的比特数恒定,Bloom过滤器也会产生恒定的假阳性概率。例如,当
m
=
8
n
m = 8n
m=8n时,假阳性概 率仅为0.02以上。对于大多数理论分析,这种权衡并不有用:通常,需要渐近消失的误差概率,只 有当每个元素使用
Θ
(
l
o
g
n
)
Θ(log n)
Θ(logn)位时,才能实现。因此,Bloom 过滤器在理论讨论中很少受到关注。相 比之下,对于实际应用,恒定的数学假阳性概率可能是值得的,以保持每个元素使用相同的比特 数。
5.1.4 标准的Bloom filter的应用技巧
- Bloom filter简单的结构使其实现变得很容易。例如,假设有两个Bloom filter,表示具有相同位数并使用相同哈希函数的集合S1和S2。然后,通过取Bloom filter的两个位向量的或,可以得到一个表示两个集合并的Bloom filter。
- Bloom filter的大小可以很容易地减半,允许应用程序动态收缩Bloom filter。假设filter的大小是2的幂。要将filter的大小减半,只需将前半部分和后半部分放在一起。当哈希进行查找时,最高阶位可以被屏蔽。
- Bloom filter可以被用来表示两个集合的交集。假设有两个Bloom过滤器表示集合S1和S2,它们具有相同的位数并使用相同的哈希函数。那么,在两个filter的第
j
j
j位,置为1的概率是:
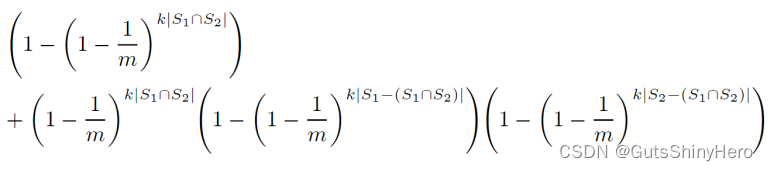
通过一些代数学上的简化,两个表示向量的内积的期望值是:
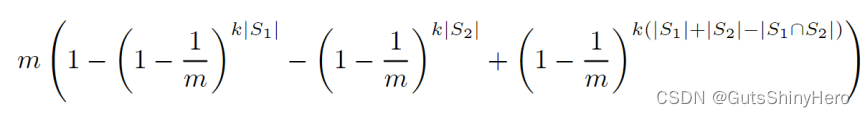
因此,如果给定S1,S2集合大小,k,m值,和两个向量的内积值,那么就可以估算两个集合的交集中的元素个数。注意,就算不给定原始集合的大小,依然可以通过Bloom filter中0的个数来估算集合元素个数,就像第一部分的推导,0的个数近似于
m
(
1
−
1
/
m
)
k
∣
S
∣
m(1-1/m)^{k|S|}
m(1−1/m)k∣S∣
有近似式
1
m
(
1
−
1
m
)
−
k
∣
S
1
∩
S
2
≈
Z
1
+
Z
2
−
Z
12
Z
1
Z
2
\frac{1}{m}\bigg(1-\frac{1}{m}\bigg)^{-k|S_1\cap S_2}\approx \frac{Z_1+Z_2-Z_{12}}{Z_1Z_2}
m1(1−m1)−k∣S1∩S2≈Z1Z2Z1+Z2−Z12
其中
Z
1
Z_1
Z1是
S
1
S_1
S1的Bloom filter中0的个数,
Z
12
Z_{12}
Z12是向量内积中0的个数。
5.1.5 计数Bloom filter
在Bloom filter中需要对元素进行增删。增加元素很简单,只需要计算哈希值,将对应的位数 置为0;但删除元素时却不能将相应元素置为0,因为每个元素的哈希值可能有所重叠,如果简 单将其全部置零会使Bloom filter不能正确表示集合中元素。为此提出了计数Bloom filter的概念:不同之处在于哈希值指向的不再是一个单位值,而是一个小计数器,当插入元素时将对应哈希值的计数器加1,删除元素时将对应位减一,为了避免计数器的溢出,需要确定计数器的尺寸。
延续上述推理中的符号设置,
c
(
i
)
c(i)
c(i)为第
i
i
i位的计数器的值,那么第
i
i
i位计数器值为j的概率是:
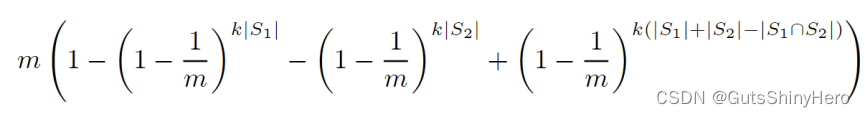
所有计数器至少为
j
j
j的概率以
m
P
(
c
(
i
)
≥
j
)
mP(c(i)≥j)
mP(c(i)≥j)为界,可用上式计算,同时有下式:
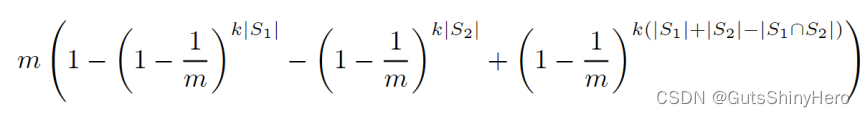
再将推导出的k上界:
k
≤
(
l
n
2
)
m
/
n
k \le (ln2)m/n
k≤(ln2)m/n带入后可得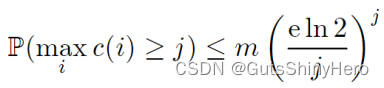
假设采用4位的计数器,那么要使计数器溢出,就需要
j
j
j的值大于16,而计数器大于16的最大概率是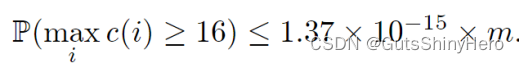
这个结果适用于最多拥有
n
n
n个元素的所有集合,所以
t
t
t个不同的集合溢出的联合分布概率是
1.37
×
1
0
−
15
m
t
1.37×10^−15mt
1.37×10−15mt,这可以适用于大多数的应用场景。
解释此结果的另一种方法是观察到,当
m
m
m个计数器上分布有
m
l
n
2
m ln 2
mln2个计数器增量时,那么很大可能最大计数器值是
O
(
l
o
g
m
)
O(log m)
O(logm),因此每个计数器只需要
O
(
l
o
g
l
o
g
m
)
O(log log m)
O(loglogm)位。
实际应用中,如果计数器溢出,常采用的方法是将计数器维持维持在最大值,仅当计数器减到0时会发生假阴性情况,如果删除是随机的,则此事件的预期时间相对较大。
5.1.6 压缩式的Bloom filter
如果我们选择k的最优值来最小化前面计算的错误概率,则
p
=
1
/
2
p = 1/2
p=1/2。在我们假设好的随机哈希函数下,位数组本质上是一个由
m
m
m个0和1组成的随机字符串,每个条目为0或1,概率为1/2。因此,压缩似乎不能带来任何好处。
这种推理的缺陷是当我们在约束条件下优化了Bloom filter的误报率,即过滤器中有m位,有n个元素。假设我们在压缩后要发送的比特数为z的约束下优化布隆过滤器的误报率,但其未压缩形式的数组误报率可能更大。事实证明,使用更大但更稀疏的Bloom filter可能与更少的传输位数下产生相同的误报率。或者,可以使用相同数量的传输位,但提高误报率,或者在两者之间找到更合适的折衷。
给出了一个例子,其目标是获得小的误报率,同时每个元素使用不到 16 个传输位。在没有压缩的情况下,哈希函数的最佳数量为11,假阳性概率为0.000459;通过使用每个元素 48 位但只有 3 个散列函数的稀疏 Bloom 过滤器,可以将结果压缩到每个项目的不到 16 位(概率很高),并将误报概率降低了大约 2 倍。
5.1.7 主要的历史和现在(2004)的应用
- 词典:Bloom filter在早期的UNIX中的使用,数据库中的Bloom filter.
- 一个样本网络应用:分布式缓存.
- Bloom filter进行网络中的缓存共享.
- P2P/Overlay Networks:早期的点对点应用;中等规模P2P网络;内容传递中的近似集合和解决问题;关键词搜索中的集合交并集
- 分组路由:基本路由协议;P2P网络上的资源路由;地理路由
- 数据包路由:检测Icarus中的环;队列管理:随机公平蓝色;多播
- 用于测量的基础工具:记录重点流;IP追踪
6 实验结果(Evaluation)
思考与相关工作
Bloom filter通过接受一定程度的误报率和增加一定的哈希求解的时间来大幅度的节省空间,这是很经典的考虑空间限制情景下的理论模型,通过这种权衡,Bloom filter将很大的映射空间节约到一个较小的尺度上,这非常适合空间制约严重的实际情景,如路由器和高速网络设备。Bloom filter实际上是一种对传统哈希方法的延申拓展,最大的改变在于,不同元素得出哈希索引值可能重叠,这会导致误报的产生,但通过数学的理论推导,选用合适的哈希函数数量和Bloom filter的大小可以一定程度上降低误报率,同时在实际应用中也可以针对不同的情景减小误报对整个filter的影响,如在关键字搜索中应用集合交集求解的Bloom filter 就可以通过接受端的再确认来消除误报的影响。


















 989
989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









