







Safe Self-Refinement for Transformer-based Domain Adaptation
* Authors: Tao Sun, Cheng Lu, Tianshuo Zhang, Haibin Ling

阅读内容总结
论文摘要(Abstract)
提出了一种名为 SSRT(基于 Transformer 的域自适应的安全自改进)的新颖解决方案,它从两个方面带来了改进:
- 首先,受到视觉 Transformer 在各种视觉任务中取得成功的鼓舞,为 SSRT 配备了 Transformer 主干。Vision Transformer与简单对抗性适应的结合超过了在具有挑战性的 DomainNet 基准上最好报道的基于卷积神经网络 (CNN) 的结果,显示出其强大的可转移特征表示
- 为了降低模型崩溃的风险并提高差距较大的领域之间知识转移的有效性,提出了安全自我改进策略。具体来说,SSRT 利用扰动目标域数据的预测来完善模型。由于Vision Transformer的模型容量很大,并且在此类具有挑战性的任务中的预测可能会有噪声,因此设计了一种安全的训练机制来自适应地调整学习配置。
对多个经过广泛测试的 UDA 基准进行了广泛的评估,SSRT 始终获得最佳性能,包括 Office-Home 上的 85.43%、VisDA-2017 上的 88.76% 和 DomainNet 上的 45.2%。
- 开发了一种新颖的UDA 解决方案SSRT,它采用Vision Transformer主干来实现强大的可转移特征表示,并利用对扰动目标域数据的预测来进行模型细化。
- 提出了一种安全的培训策略,以防止学习过程因较大的领域差距而崩溃。它在训练过程中通过对目标域数据的模型预测的多样性度量来自适应地调整学习配置。
- SSRT 是最早探索用于领域适应的Vision Transformer的公司之一。基于Vision Transformer的 UDA 已经显示出有希望的结果,特别是在像 DomainNet 这样的大规模数据集上。
- 在经过广泛测试的基准上进行了大量的实验。SSRT 取得了最好的性能,包括在 Office-Home 上的 85.43%、在 VisDA2017 上的 88.76% 和在 DomainNet 上的 45.2%
研究动机(Motivation/Introduction)
在UDA领域,利用对抗性学习的思想学习领域不变特征表示的对抗性适应一直是一种流行的范式。深度 UDA 方法通常与视觉任务中的预训练卷积神经网络(CNN,例如 ResNet)主干结合应用。在 OfficeHome 和 VisDA 等中等规模的分类基准上,报告的最新技术非常令人印象深刻 。然而,在像 DomainNet 这样的大规模数据集上,我们提交的文献中的最新结果报告了 33.3% 的最佳平均准确率,这远远不能令人满意。
重点从两个方面考虑困难的UDA问题:
- 首先,从表现方面来看,希望使用更强大的骨干网络。这将我们的注意力引向最近流行的Vision Transformer,它已成功应用于各种视觉任务。Vision Transformer将图像处理为标记序列,并使用全局自注意力来完善这种表示。凭借其长程依赖性和大规模预训练,Vision Transformer获得了强大的特征表示,为下游任务做好了准备。尽管如此,它在 UDA 中的应用仍处于探索之中。因此我们建议将Vision Transformer集成到 UDA 中。我们发现,通过简单地将 ViT-B/16 与对抗性适应相结合,它可以在 DomainNet 上实现 38.5% 的平均准确率,优于当前使用 ResNet-101 的技术。这表明Vision Transformer的特征表示具有区分性并且可以跨域转移。
- 其次,从领域适应方面来看,需要更可靠的策略来保护学习过程不会因领域差距过大而崩溃。由于像Vision Transformer这样具有大容量的强大主干会增加对源域数据过度拟合的机会,因此需要对目标域数据进行正则化。 UDA 的常见做法是利用模型预测进行自训练或在目标域数据上强制执行聚类结构 。虽然这通常有帮助,但当领域差距很大时,监督可能会很吵。因此,适应方法预计是安全的,足以避免模型崩溃
SSRT 采用Vision Transformer作为主干网络,并利用对扰动目标域数据的预测来细化适应模型。具体来说,我们向目标域数据的潜在标记序列添加随机偏移,并使用 Kullback Leibler (KL) 散度最小化原始版本和扰动版本之间模型预测概率的差异。
为了防止学习过程崩溃,我们提出了一种新颖的安全训练机制。由于 UDA 任务即使来自同一数据集,也有很大差异,适用于大多数任务的特定学习配置(例如超参数)可能会在某些特定任务上失败。因此希望学习配置能够自动调整。
监控整个训练过程并自适应地调整学习配置。我们对目标域数据使用模型预测的多样性度量来检测模型崩溃。一旦发生,模型将恢复到之前达到的状态,并且配置将被重置。通过这种安全的训练策略,我们的 SSRT 可以避免在具有较大域间隙的适应任务中出现显着的性能下降。
结论(Conclusion)
在本文中,我们提出了一种名为 SSRT 的新型 UDA 方法。它利用Vision Transformer主干,并使用扰动的目标域数据来完善模型。制定安全的训练策略以避免模型崩溃。基准测试实验显示其最佳性能。局限性。尽管我们将 DomainNet 上的平均准确率提高到 45.2%,但它还远未达到饱和。一种方法是组合多个源域。另一种方法是合并一些有关目标领域的元知识。我们计划将来在这些方向上扩展我们的研究。
主体工作
无监督问题的形式化表述
UDA 旨在学习分类器
h
=
g
◦
f
h = g ◦ f
h=g◦f ,其中
f
(
⋅
;
θ
f
)
:
X
→
Z
f (·; θf ) : X → Z
f(⋅;θf):X→Z 表示特征提取器,
g
(
⋅
;
θ
g
)
:
Z
→
Y
g(·; θg) : Z → Y
g(⋅;θg):Z→Y 表示类别预测器,Z 是潜在空间。
对抗性适应通过二元域判别
d
(
⋅
;
θ
d
)
:
Z
−
>
[
0
,
1
]
d(·; \theta_d) : Z -> [0, 1]
d(⋅;θd):Z−>[0,1] 将特征映射到域标签来学习域不变特征
min
f
,
g
max
d
L
=
L
C
E
−
L
d
+
β
L
t
g
t
\min_{f,g}\max_{d}\mathcal{L}=\mathcal{L}_{\mathrm{CE}}-\mathcal{L}_{\mathrm{d}}+\beta\mathcal{L}_{\mathrm{tgt}}
f,gmindmaxL=LCE−Ld+βLtgt
其中
L
C
E
L_{CE}
LCE是源域数据上的交叉熵损失,
L
d
L_{d}
Ld是域对抗性损失:
L
d
=
−
E
x
∼
D
s
[
log
d
(
f
(
x
)
)
]
−
E
x
∼
D
t
[
log
(
1
−
d
(
f
(
x
)
)
)
]
\mathcal{L}_{\mathrm{d}}=-\mathbb{E}_{\boldsymbol{x}\sim\mathcal{D}_s}\big[\log d(f(\boldsymbol{x}))\big]-\mathbb{E}_{\boldsymbol{x}\sim\mathcal{D}_t}\big[\log(1-d(f(\boldsymbol{x})))\big]
Ld=−Ex∼Ds[logd(f(x))]−Ex∼Dt[log(1−d(f(x)))]
β
\beta
β是权衡参数,
L
t
g
t
L_{tgt}
Ltgt是目标域数据的损失。
L
t
g
t
L_{tgt}
Ltgt的常见选择是互信息最大化损失。
在我们的方法中,将其实例化为自求精损失
L
S
R
L_{SR}
LSR即
L
t
g
t
=
L
S
R
L_{tgt}=L_{SR}
Ltgt=LSR
主要框架
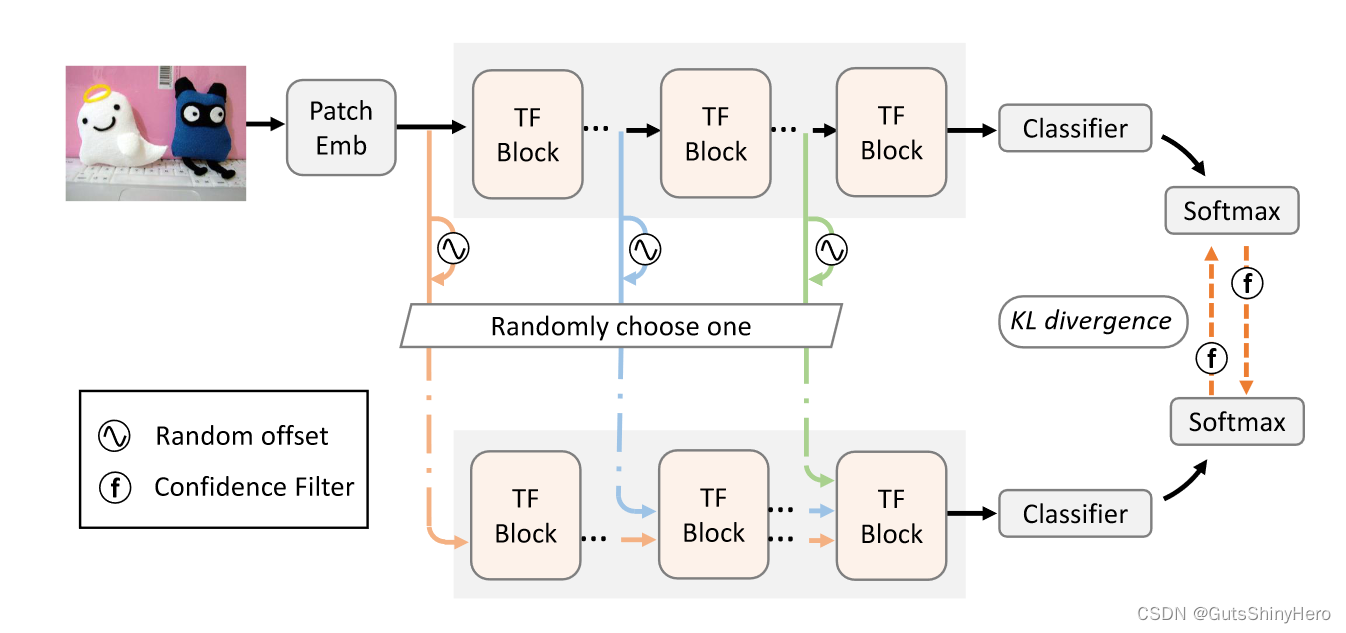
该网络由Transformer主干和分类器头组成。
- 对于每个目标域图像,嵌入层将其转换为包含特殊类标记和图像标记的标记序列。
- 然后使用一系列 Transformer Block 来完善该序列。
分类器头获取类标记并输出标签预测。我们随机选择一个Transformer Block ,并向其输入token序列添加随机偏移量。然后使用原始版本和扰动版本的相应预测类别概率进行双向自细化。 - 为了避免噪音监督,仅通过置信过滤器使用可靠的预测。
- 为了降低模型崩溃的风险,我们使用安全的训练机制来学习模型。
Transfomer的多层扰动
随机扰动的动机
Vision Transformer由于其特殊的架构而具有一些特殊的属性。由于嵌入层只是一个卷积层加上位置嵌入,因此原始输入上的线性操作可以等效地转移到第一个Transformer 块。此外,由于Transformer 块内的残差连接,相邻块的Token序列高度相关。然而,添加扰动的最佳层因任务而异。根据经验,扰动相对较深的层表现更好,但模型崩溃的风险更高。
因此,从多个层中随机选择一个层,这被证明比扰动其中的任何一层更稳健。事实上,它同时对多个层进行正则化,使学习过程更加安全。
具体方案
给定目标域图像
x
x
x,令
b
x
l
b^{l}_{x}
bxl 为其第
l
l
l 个变换器块的输入标记序列。
b
x
l
b^{l}_{x}
bxl 可以被视为
x
x
x 在隐藏空间中的潜在表示。由于其维度很高,而目标域数据的支持在空间上是有限的,所以任意扰动
b
x
l
b^{l}_{x}
bxl是低效的。相反,我们利用另一个随机选择的目标域图像
x
r
x_r
xr 的标记序列
b
l
x
r
b_{l_{xr}}
blxr 来添加偏移量。
b
x
l
b^{l}_{x}
bxl 的扰动标记序列为
b
~
x
l
=
b
x
l
+
α
[
b
x
r
l
−
b
x
l
]
×
\tilde{b}_x^l=b_x^l+\alpha[b_{xr}^l-b_x^l]_\times
b~xl=bxl+α[bxrl−bxl]×
α
\alpha
α是一个标量,
[
.
]
X
[.]_X
[.]X表示没有梯度的反向传播。
除了手动注入的扰动之外,分类器头中的 Dropout 层也对两个分支随机工作。这造成了自我精炼损失的另一个差异来源。
双向自细化
设
p
x
p_x
px 和
p
~
x
\tilde{p}_{x}
p~x 分别为
b
x
l
{b}^l_{x}
bxl 和
b
~
x
l
\tilde{b}^l_{x}
b~xl 对应的预测概率向量。为了测量它们的距离,通常使用 KL 散度:
D
K
L
(
p
t
∥
p
s
)
=
∑
i
p
t
[
i
]
l
o
g
p
t
[
i
]
p
s
[
i
]
D_{\mathrm{KL}}(\boldsymbol{p}_t\|\boldsymbol{p}_s)=\sum_i\boldsymbol{p}_t[i]\mathrm{log}\frac{\boldsymbol{p}_t[i]}{\boldsymbol{p}_s[i]}
DKL(pt∥ps)=i∑pt[i]logps[i]pt[i]
其中
p
t
p_t
pt 是教师概率(又名目标概率),
p
s
p_s
ps 是学生概率。请注意,KL 散度在
p
t
p_t
pt 和
p
s
p_s
ps 中是不对称的。虽然很自然地将
p
x
p_x
px 作为教师概率,因为它对应于原始数据,但我们发现反过来也有效。我们的双向自求精损失定义为:
L
S
R
=
E
B
t
∼
D
t
{
ω
E
x
∼
F
[
B
t
;
p
]
D
K
L
(
p
x
∥
p
~
x
)
+
(
1
−
ω
)
E
x
∼
F
[
B
t
;
p
~
]
D
K
L
(
p
~
x
∥
p
x
)
}
,
\begin{aligned}\mathcal{L}_{\mathrm{SR}}&=\mathbb{E}_{\mathcal{B}_t\sim\mathcal{D}_t}\Big\{\omega\mathbb{E}_{\boldsymbol{x}\sim F[\mathcal{B}_t;\boldsymbol{p}]}D_{\mathbf{KL}}(\boldsymbol{p}_x\|\boldsymbol{\tilde{p}}_x)\\&+(1-\omega)\mathbb{E}_{\boldsymbol{x}\sim F[\mathcal{B}_t;\boldsymbol{\tilde{p}}]}D_{\mathrm{KL}}(\boldsymbol{\tilde{p}}_x\|\boldsymbol{p}_x)\Big\},\end{aligned}
LSR=EBt∼Dt{ωEx∼F[Bt;p]DKL(px∥p~x)+(1−ω)Ex∼F[Bt;p~]DKL(p~x∥px)},
ω
\omega
ω是从伯努利分布
B
(
0.5
)
\mathcal{B}(0.5)
B(0.5)中采样的随机变量,F是一个置信度过滤器:
F
[
D
;
p
]
=
{
x
∈
D
∣
max
(
p
x
)
>
ϵ
}
F[\mathcal{D};\boldsymbol{p}]=\{\boldsymbol{x}\in\mathcal{D}|\max(\boldsymbol{p}_x)>\epsilon\}
F[D;p]={x∈D∣max(px)>ϵ}
L
S
R
L_{SR}
LSR 通过置信预测来完善模型,并对其进行正则化,以在潜在特征空间中平滑地进行预测。
通常,损失梯度仅通过学生概率(即
D
K
L
D_{KL}
DKL 中的 ps)反向传播。然而,我们发现,最好在框架中通过教师和学生的概率来反向传播梯度。回想一下,在
b
~
x
l
\tilde{b}_{x}^{l}
b~xl的定义中,
∂
L
S
R
/
∂
b
~
x
l
\partial\mathcal{L}_{\mathrm{SR}}/\partial\tilde{b}_{x}^{l}
∂LSR/∂b~xl 相同地传播到
b
~
x
l
\tilde{b}_{x}^{l}
b~xl。因此,每个模型参数都根据 px 和 ̃ px 的联合效应进行更新。这可以避免任何单一概率产生过大的梯度。当 KL 散度中教师概率的梯度或
b
~
x
l
\tilde{b}_{x}^{l}
b~xl 的梯度被阻止时,我们观察到性能下降。
通过自适应调整进行安全训练
在所提出的自细化策略中,设置适当的扰动标量α和自细化损失权重β的值至关重要.过大的扰动会导致预测的类别分布崩溃,而较小的扰动则可能无法充分利用其好处。由于目标域完全未标记,并且即使对于相同的数据集,域适应任务也有很大差异,因此需要自适应地调整这些值。一些作品 [1, 29] 在训练开始时应用了一个加速期。虽然这缓解了该时期崩溃的趋势,但它无法解决最大值不适合当前适应任务的问题。
我们提出了Safe Training机制。观察结果是,每当模型开始崩溃时,模型预测的多样性就会同时减少。
我们的目标是在监控训练过程的同时检测此类事件。一旦发生,学习配置将被重置,同时模型将恢复到之前达到的状态。
自适应标量的数值定义
具体地,采用自适应标量
r
∈
[
0
,
1
]
r \in[0, 1]
r∈[0,1]来调制
α
\alpha
α和
β
\beta
β,即
α
r
=
r
α
\alpha_{r} = r\alpha
αr=rα和
β
r
=
r
β
\beta_{r} = r\beta
βr=rβ。我们定义一个固定的周期T,并将训练过程划分为连续的间隔。在每个间隔结束时保存模型快照.
r定义:
r
(
t
)
=
{
sin
(
π
2
T
r
(
t
−
t
r
)
)
if
t
−
t
r
<
T
r
1.0
otherwise
r(t)=\begin{cases}\sin\left(\frac{\pi}{2T_r}(t-t_r)\right)&\text{if }t-t_r<T_r\\1.0&\text{otherwise}\end{cases}
r(t)={sin(2Trπ(t−tr))1.0if t−tr<Trotherwise
其中,
t
t
t是当前的训练步数。
如图所示:粉色区域表示,检测到多样性下降事件
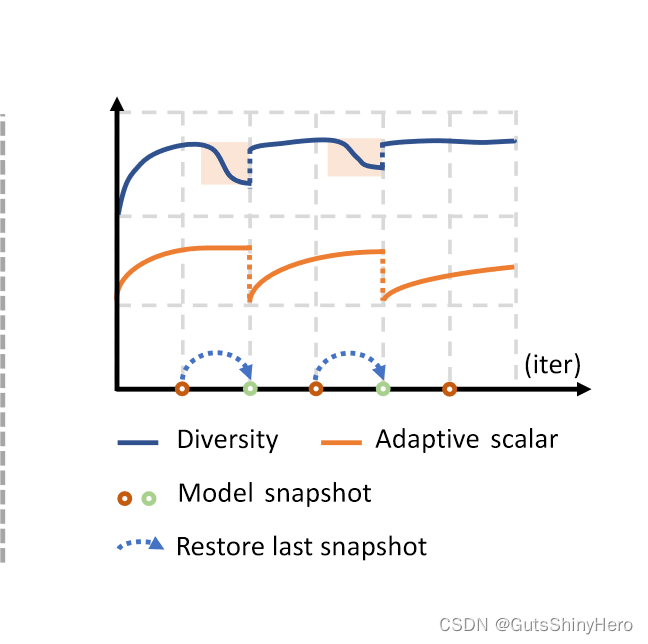
初始时,令 T r = T , t r = 0 T_r=T,t_r=0 Tr=T,tr=0,r 需要 T 个步骤才能上升到 1.0。在每个间隔结束时,检查该间隔内模型预测的多样性以发现突然下降。如果不存在,则 r 的公式保持不变。否则,将 t r t_r tr 重置为当前训练步骤 t t t,并将模型恢复到上一个快照。为了避免崩溃和恢复之间的振荡,如果最后一次恢复发生在 T r T_r Tr步骤内,则 T r T_r Tr 将加倍。
模型的多样性度量
发现每个目标训练批次 Bt 上的独特模型预测标签的数量效果很好。因此,定义了以下多样性度量: div ( t ; B t ) = u n i q u e _ l a b e l s ( h ( B t ) ) \text{div}(t;\mathcal{B}_t)=unique\_labels(h(\mathcal{B}_t)) div(t;Bt)=unique_labels(h(Bt))为了检测多样性下降,将间隔分为子间隔,并检查每个子间隔的平均多样性值是否下降。我们在多尺度上实现这一点以提高检测的灵敏度。检查 T / 2 1 、 ⋅ ⋅ ⋅ ⋅ 、 T / 2 L T /2^1、····、T /2^L T/21、⋅⋅⋅⋅、T/2L步长的每个连续子区间是否有给定的整数 L.
Safe Training 机制算法伪代码

SSRT 算法描述

实验结果(Evaluation)
数据集选择
我们在四个流行的 UDA 基准上评估我们的方法。
Office-31 [22] 包含来自三个域的 31 个类别的 4,652 个图像:Amazon (A)、DSLR (D) 和 Webcam (W)。
Office-Home [33] 由来自四个领域的 65 个类别的 15,500 张图像组成:艺术 (Ar)、剪贴画 (Cl)、产品 (Pr) 和现实世界 (Rw) 图像。
VisDA2017 [20] 是一个从合成到真实的数据集,包含 12 个类别的约 20 万张图像。 DomainNet [19] 是最大的 DA 数据集,包含 6 个领域 345 个类别的约 60 万张图像:Clipart (clp)、Infograph (inf)、Painting (pnt)、Quickdraw (qdr)、Real (rel)、Sketch (skt) 。
Baseline
使用在 ImageNet 上预先训练的 16×16 patch 大小 的 ViT-base 和 ViT-small 作为Transformer主干。对于所有任务,我们使用一组相同的超参数
(
α
=
0.3
、
β
=
0.2
、
ϵ
=
0.4
、
T
=
1000
、
L
=
4
)
(\alpha = 0.3、\beta = 0.2、\epsilon = 0.4、T = 1000、L = 4)
(α=0.3、β=0.2、ϵ=0.4、T=1000、L=4)。
比较方法包括DANN [4]、CDAN [14]、CDAN+E [14]、SAFN [38]、SAFN+ENT [38]、CDAN+TN [35]、SHOT [12]、DCAN+SCDA [10] ]、MDD+SCDA [10]、SWD [9]、MIMTFEL [5]、TVT [40] 和 CDTrans [39]。
“基线”是具有对抗性适应的 ViT。还与互信息(MI)损失的组合进行比较。
结果分析
SSRT与Baseline比较
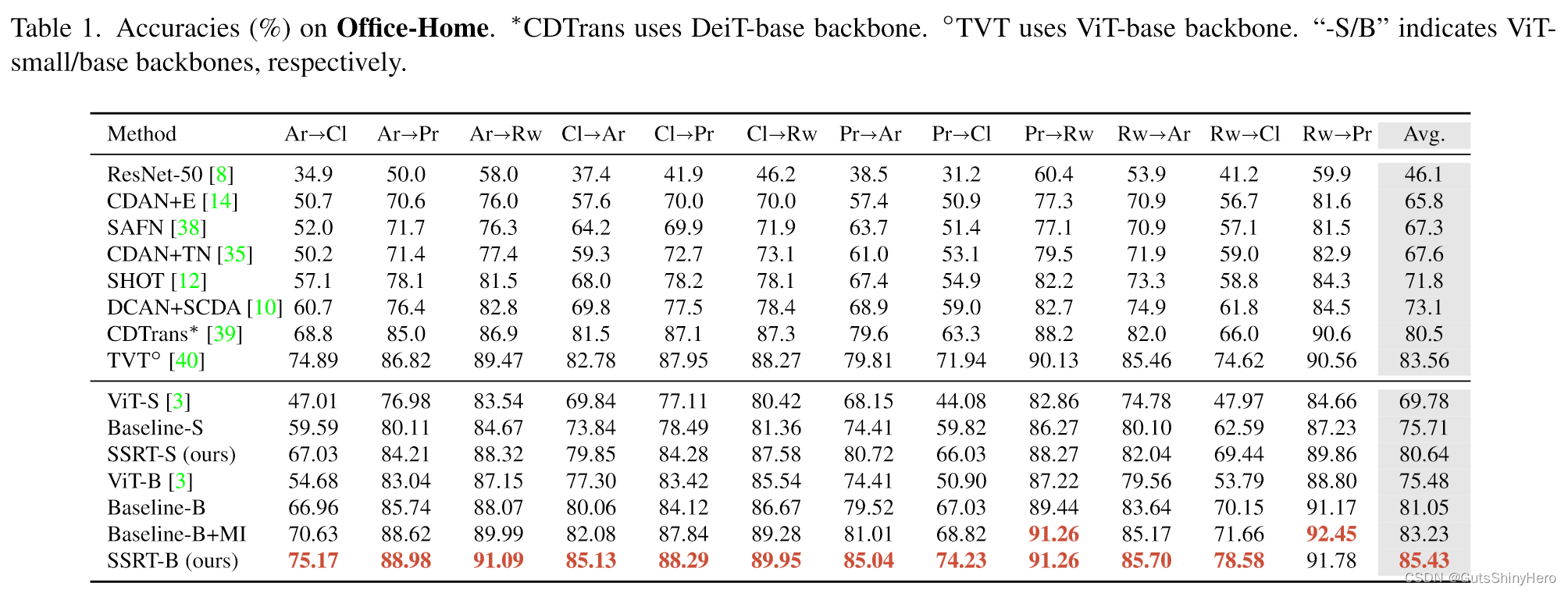
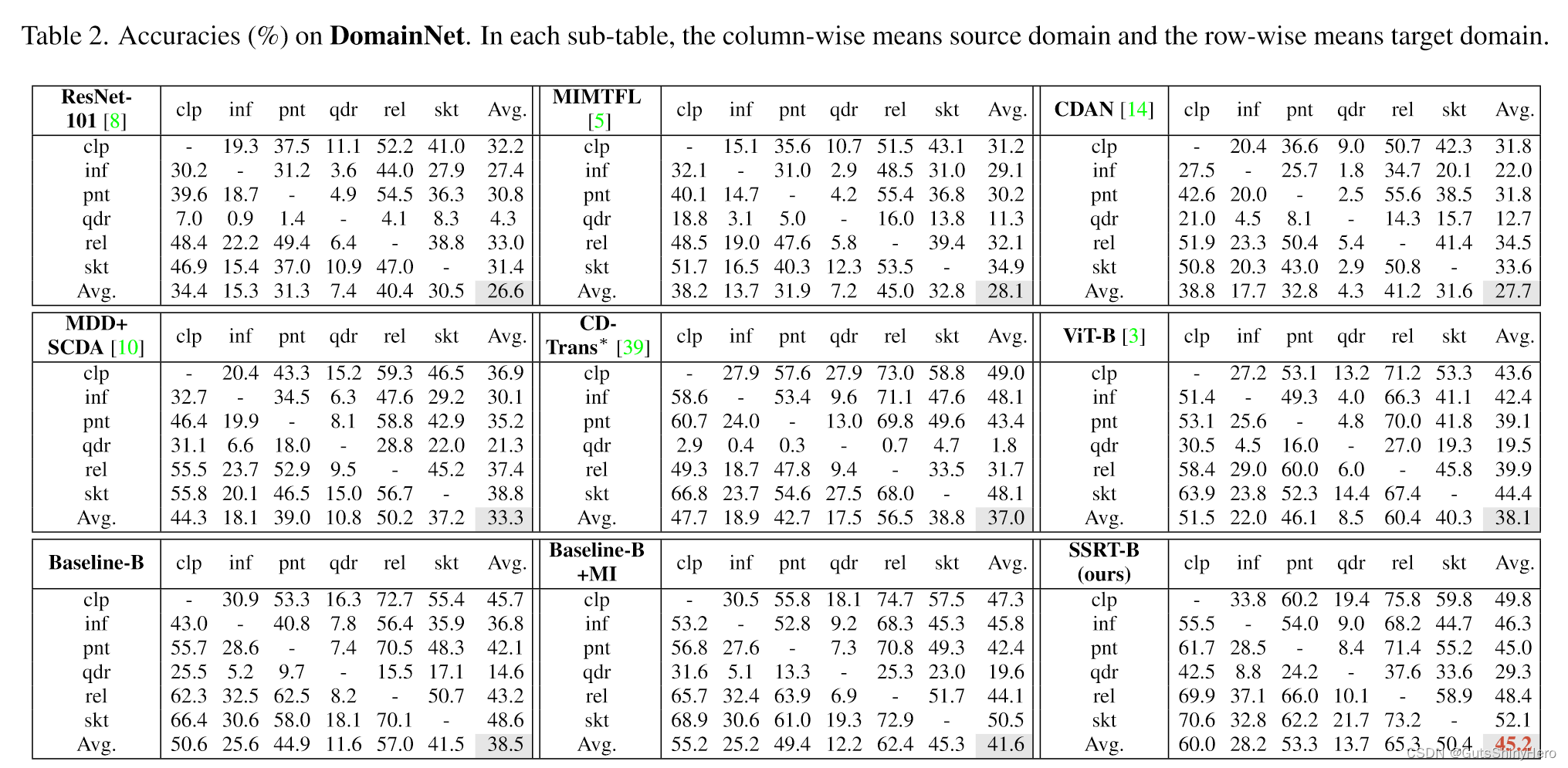
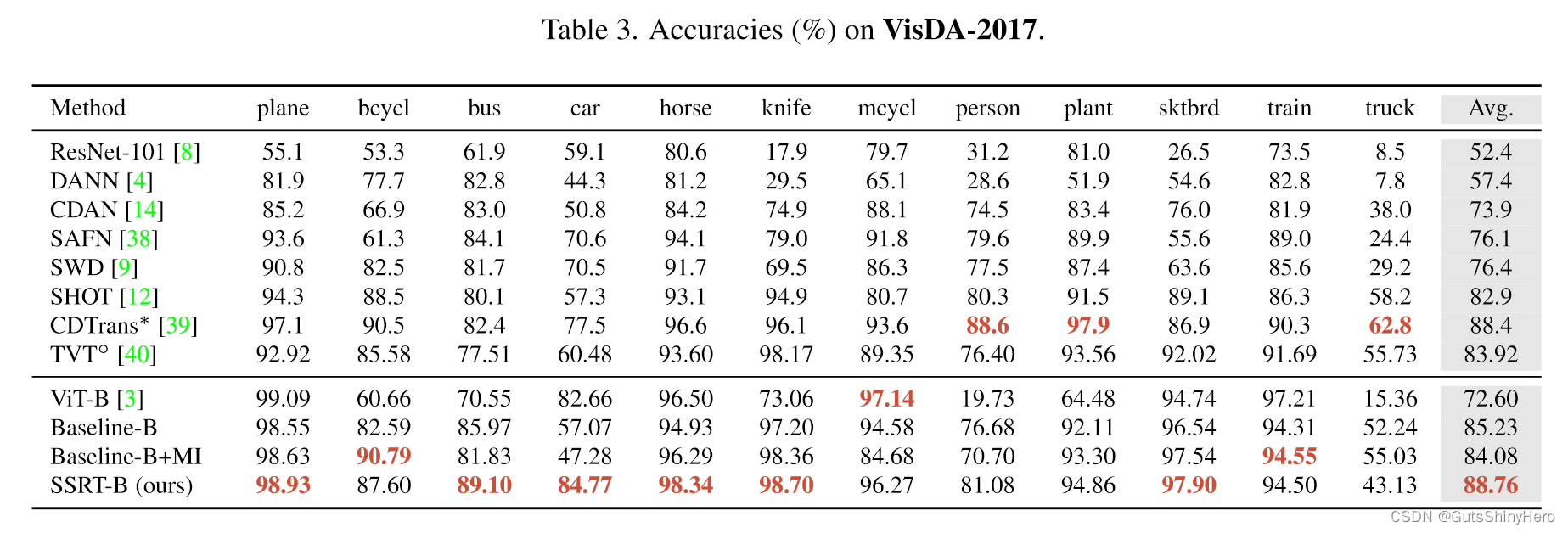
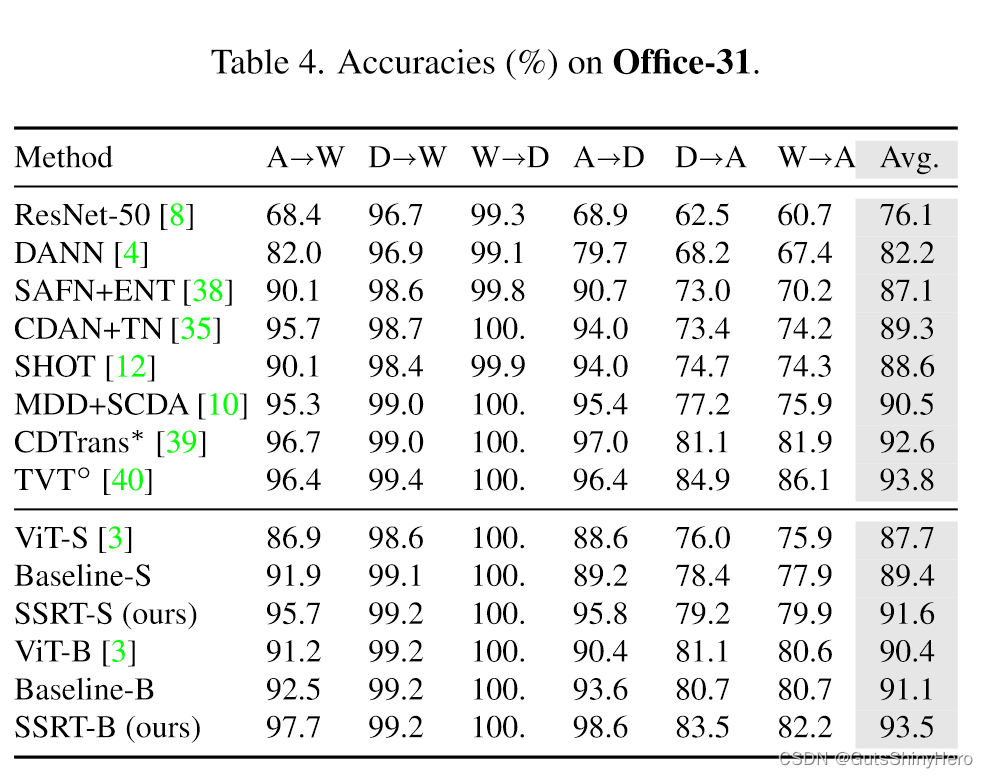
与其他方法相比,SSRT-B 在 Office-Home、DomainNet 和 VisDA 上表现最好。尽管 Baseline-B 已经非常强大,但与 Baseline-B 相比,它在 Office-Home 上提高了 4.38%,在 VisDA-2017 上提高了 3.53%,在 DomainNet 上提高了 6.7%。
特别是,在具有挑战性的 DomainNet 数据集上,SSRT-B 实现了令人印象深刻的 45.2% 平均准确率。值得一提的是,在DomainNet中,有些域与其他域存在较大差距,例如inf和qdr。在这些领域和其他领域之间转移非常困难。因此希望安全传输并且不会显着降低性能。以 qdr 为目标域的任务来看,SSRT-B 获得了 29.3% 的平均准确率,而许多其他方法表现不佳。我们将在以下部分中说明一些有助于我们实现卓越性能的重要组件的作用。
多层扰动的对比

对潜在标记序列应用扰动比对 Office-Home (OH) 和 DomainNet (DN) 上的原始输入图像应用扰动效果更好。
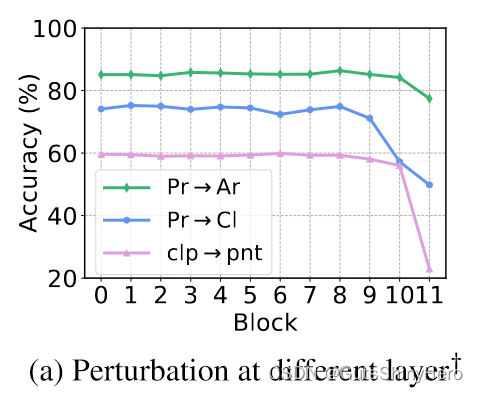
上图中比较了在不使用安全训练的情况下向每层添加相同量的扰动时的性能。可以看出,应用扰动的最佳层因任务而异。此外,适用于一项任务的层可能无法完成其他任务。在我们的实验中,我们统一从{0,4,8}中选择一层。作为比较,扰动其中的任何单层都会使 DomainNet 上的平均准确度分别降低 -1.0%、-1.5% 和 -1.5%。
双向自适应的效果
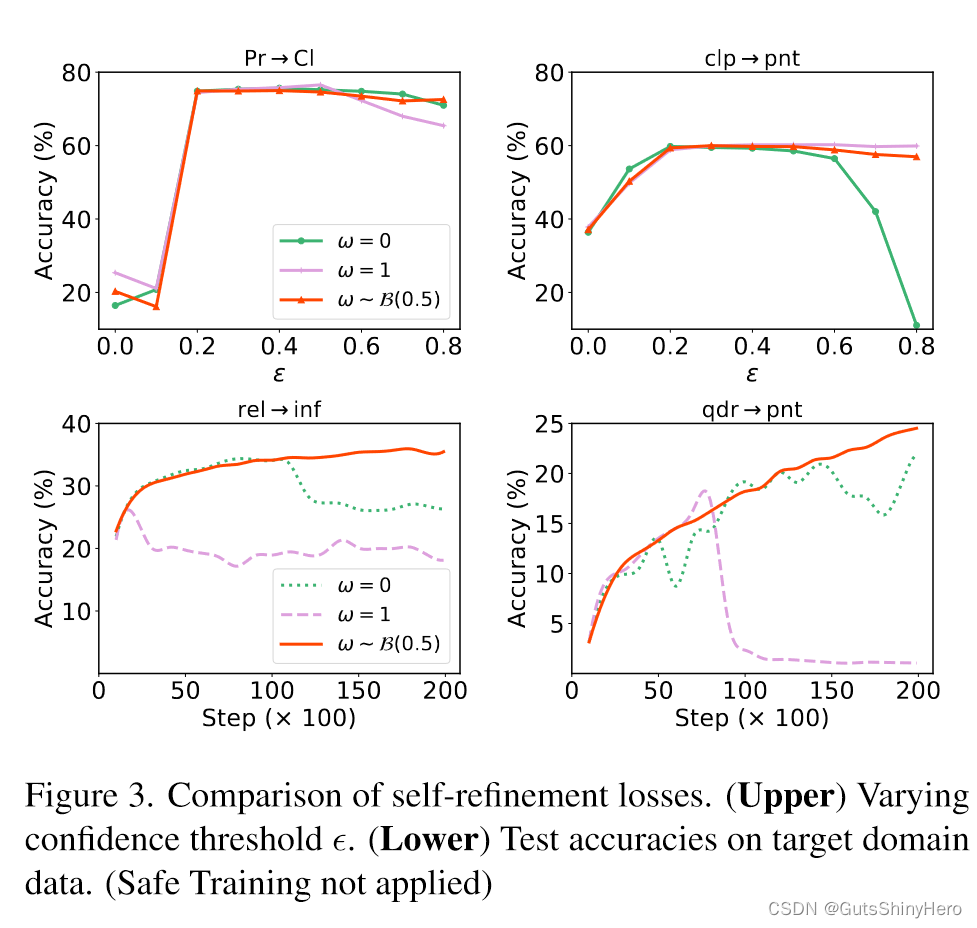
在上方的图中,当置信阈值
ϵ
\epsilon
ϵ相对较大时,它们的性能会下降。在下面的两张图中,模型在训练某些步骤后发生崩溃。相比之下,双向自求精更加稳健,因为它结合了两种损失,从而减少了其中任何一种的负面影响。
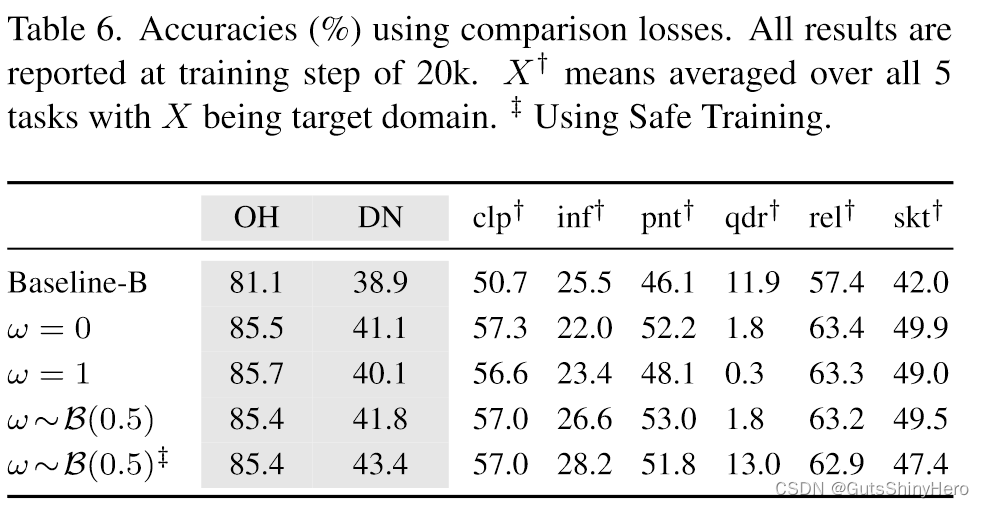
上图中:
- 在 Office-Home 上,所有损失的表现都同样出色。
- 在DomainNet上,双向自我优化效果更好。
- 然而,当目标域是 qdr 时,它们都无法完成具有挑战性的任务。这个问题可以通过安全培训来解决。
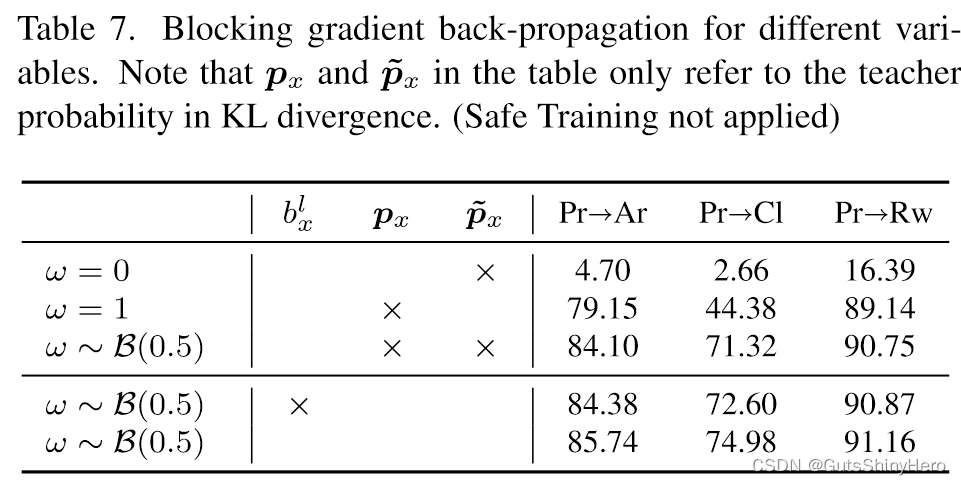
另一个重要问题是何时反向传播梯度。表 7 显示,当 b ~ x l = b x l + α [ b x r l − b x l ] × \tilde{b}_x^l=b_x^l+\alpha[b_{xr}^l-b_x^l]_\times b~xl=bxl+α[bxrl−bxl]× 中 b x l b^l_x bxl 的梯度或 L S R = E B t ∼ D t { ω E x ∼ F [ B t ; p ] D K L ( p x ∥ p ~ x ) + ( 1 − ω ) E x ∼ F [ B t ; p ~ ] D K L ( p ~ x ∥ p x ) } , \begin{aligned}\mathcal{L}_{\mathrm{SR}}&=\mathbb{E}_{\mathcal{B}_t\sim\mathcal{D}_t}\Big\{\omega\mathbb{E}_{\boldsymbol{x}\sim F[\mathcal{B}_t;\boldsymbol{p}]}D_{\mathbf{KL}}(\boldsymbol{p}_x\|\boldsymbol{\tilde{p}}_x)\\&+(1-\omega)\mathbb{E}_{\boldsymbol{x}\sim F[\mathcal{B}_t;\boldsymbol{\tilde{p}}]}D_{\mathrm{KL}}(\boldsymbol{\tilde{p}}_x\|\boldsymbol{p}_x)\Big\},\end{aligned} LSR=EBt∼Dt{ωEx∼F[Bt;p]DKL(px∥p~x)+(1−ω)Ex∼F[Bt;p~]DKL(p~x∥px)},中的梯度被屏蔽,性能会下降。一个有趣的发现是,即使梯度被阻止,双向自细化似乎也更加鲁棒。我们认为这是因为这两种损失是互补的。
Safe Training的效果
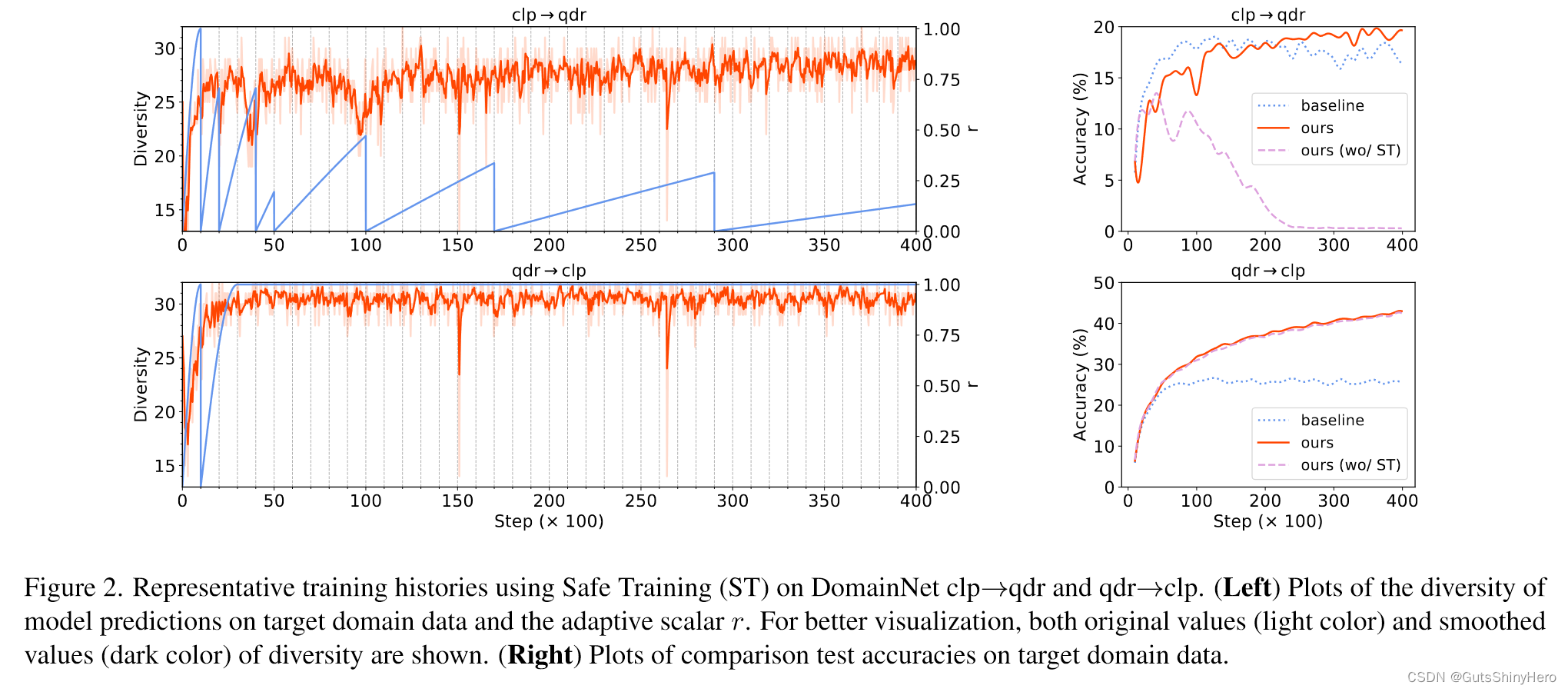
上图显示了两个代表性任务的详细训练历史,以展示其工作原理。
- 对于qdr→clp,自适应标量r很快收敛到1.0,多样性稳定到一个相对较高的值。有或没有安全训练的训练模型表现相似。
- 对于 clp→qdr,多样性在经过一些步骤后下降,并且 r 重置为较小的值。可以观察到多样性和准确性之间的明显相关性。例如,在步长为 10k 时,精度突然下降,多样性同时下降。如果没有安全训练,模型在大约 10k 次迭代后就会崩溃。通过安全训练,模型训练正常并最终超越基线。需要注意的是,模型崩溃主要影响目标域数据。对于没有安全训练的clp→qdr,源域上的最终准确率为96.9%,而目标域上的最终准确率仅为0.3%。
扰动的可视化
为了可视化目标域图像 x x x 的扰动版本,我们将可训练变量 x v i s x_{vis} xvis 初始化为 x x x,并优化 x v i s x_{vis} xvis 以最小化 ∣ ∣ b ~ x l − b x v i s l ∣ ∣ 2 ||\tilde{b}_x^l-b^l_{xvis}||^2 ∣∣b~xl−bxvisl∣∣2,其中 b ~ x l \tilde{b}_x^l b~xl 是 x x x 的扰动标记序列, b x v i s l b^l_{xvis} bxvisl 是相应的标记 x v i s x_{vis} xvis 的序列。然后 x v i s x_{vis} xvis 让我们了解潜在空间中的扰动如何反映在原始输入图像上。
上图中可视化了向不同 Transformer 块添加扰动时两个图像的扰动版本。对于浅层,可以观察到与其他图像混合的效果。然而,对于深层,由于网络的高度非线性变换,这种影响不太明显。这也表明了使用多层扰动的互补性。

消融实验
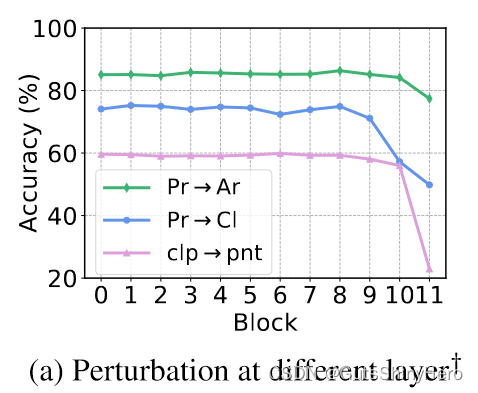
绘制了扰动不同层的结果。
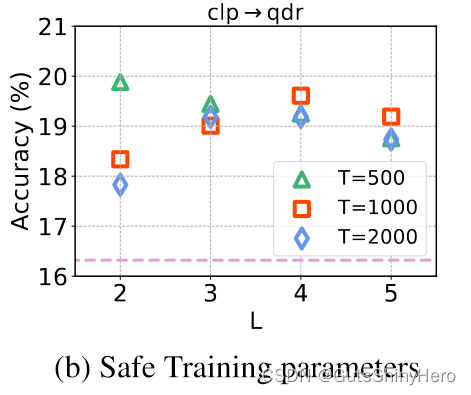
绘制了使用不同参数的安全训练。 T和L影响其粒度。 T 越小意味着响应越快。 L 越大,灵敏度越高,但存在更多误报检测的风险。 T 和 L 的许多组合在我们的方法中效果很好。

绘制了精度曲线与扰动标量
α
\alpha
α 和自细化损失权重
β
\beta
β 的关系。即使对于
α
=
0.5
\alpha = 0.5
α=0.5这样明显不合理的值,安全训练仍然可以自适应地调整它们以避免模型崩溃。当
α
=
0
\alpha = 0
α=0 时,我们的方法仍然比基线有一些增益。这是由于分类器头部中的随机丢弃操作造成的。
















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









