







Cycle Self-Training for Domain Adaptation
*Authors:Hong Liu, Jianmin Wang, Mingsheng Long

阅读内容总结
论文摘要(Abstract)
无监督域适应(UDA)的主流方法学习域不变表示来缩小域转移,这在经验上是有效的,但在理论上受到困难或不可能性定理的挑战。在 UDA 中的自我训练通过使用目标伪标签进行训练来利用未标记的目标数据,但是,在分布变化下,伪标签与目标地面事实的巨大差异可能是不可靠的。
在本文中,提出了循环自训练(CST),这是一种有原则的自训练算法,可明确强制伪标签跨域泛化。
主要的思想是:
- CST 在正向步骤和反向步骤之间循环,直到收敛。
- 在前向步骤中,CST 使用源训练分类器生成目标伪标签。
- 在相反的步骤中,CST 使用目标伪标签训练目标分类器,然后更新共享表示以使目标分类器在源数据上表现良好。
同时引入 Tsallis 熵作为置信友好的正则化,以提高目标伪标签的质量。
实验中在现实假设下从理论上分析了 CST,并提供了 CST 恢复目标地面事实的困难案例,而不变特征学习和普通自我训练都失败了。实证结果表明,CST 在视觉识别和情感分析基准方面显着优于最先进的技术。
研究动机(Motivation/Introduction)
无监督域适应(UDA)的挑战:
- 知识迁移:将知识从有监督的源域迁移到无标签的目标域是一个重要但具有挑战性的问题。
- 分布敏感性:深度神经网络对底层分布的微小变化非常敏感,导致在一个标记数据集上训练的模型往往无法泛化到另一个未标记的数据集。
特征适应(域对齐)的局限性:
- 域不变表示:主流UDA方法通过减少源域和目标域特征分布之间的距离来学习不变的表示,以促进域之间的知识迁移。
- 不可能性理论:尽管这些方法在多个领域取得了成功,但不可能性理论揭示了在学习不变表示时,面对标签偏移和域支持偏移时存在固有的局限性。
自训练(伪标签)的挑战:
- 自训练:自训练,也称为伪标签,最初用于半监督学习,通过为目标域的未标记数据生成伪标签,并与源域标签和目标域伪标签一起训练模型。
- 分布偏移:在UDA中,分布偏移使得伪标签更加困难。直接使用所有伪标签存在风险,因为累积的误差可能导致平凡解。
- 选择可信的伪标签:以前的工作通过置信度阈值或重新加权来选择可信的伪标签,以减轻标准自训练中域偏移的负面影响。但这些方法可能很脆弱,需要针对不同任务进行昂贵的阈值或权重调整,且性能提升并不一致。
循环自训练(CST)的提出:
- CST分析:首先分析了有无分布偏移时伪标签的质量,以深入了解标准自训练在UDA中的困难。研究表明,当源域和目标域相同时,伪标签分布几乎与真实标签分布相同。然而,分布偏移会导致伪标签与真实标签之间的差异非常大,某些类别的样本大多被错误分类到其他类别。
- CST方法:提出的CST方法是一种针对UDA的原则性自训练方法,它克服了标准自训练的局限性。CST通过循环使用目标伪标签训练目标分类器,并更新共享表示以使目标分类器在源数据上表现良好,从而学习跨域泛化伪标签。
- 不确定性度量:与标准的Gibbs熵不同,CST提出了一种基于信息论中Tsallis熵的置信友好的不确定性度量,该度量能够自适应地最小化不确定性,无需手动调整或设置阈值。
CST的性能和理论证明:
- 实证评估:在一系列标准的UDA基准测试中,CST在21个任务中的性能超过了先前最先进的方法,包括对象识别和情感分类。
- 理论证明:作者从理论上证明了CST目标的最小化器具有目标性能的一般保证,并研究了特定分布上的困难案例,展示了CST在特征适应和标准自训练失败时能够恢复目标真实标签的能力。
简单总结
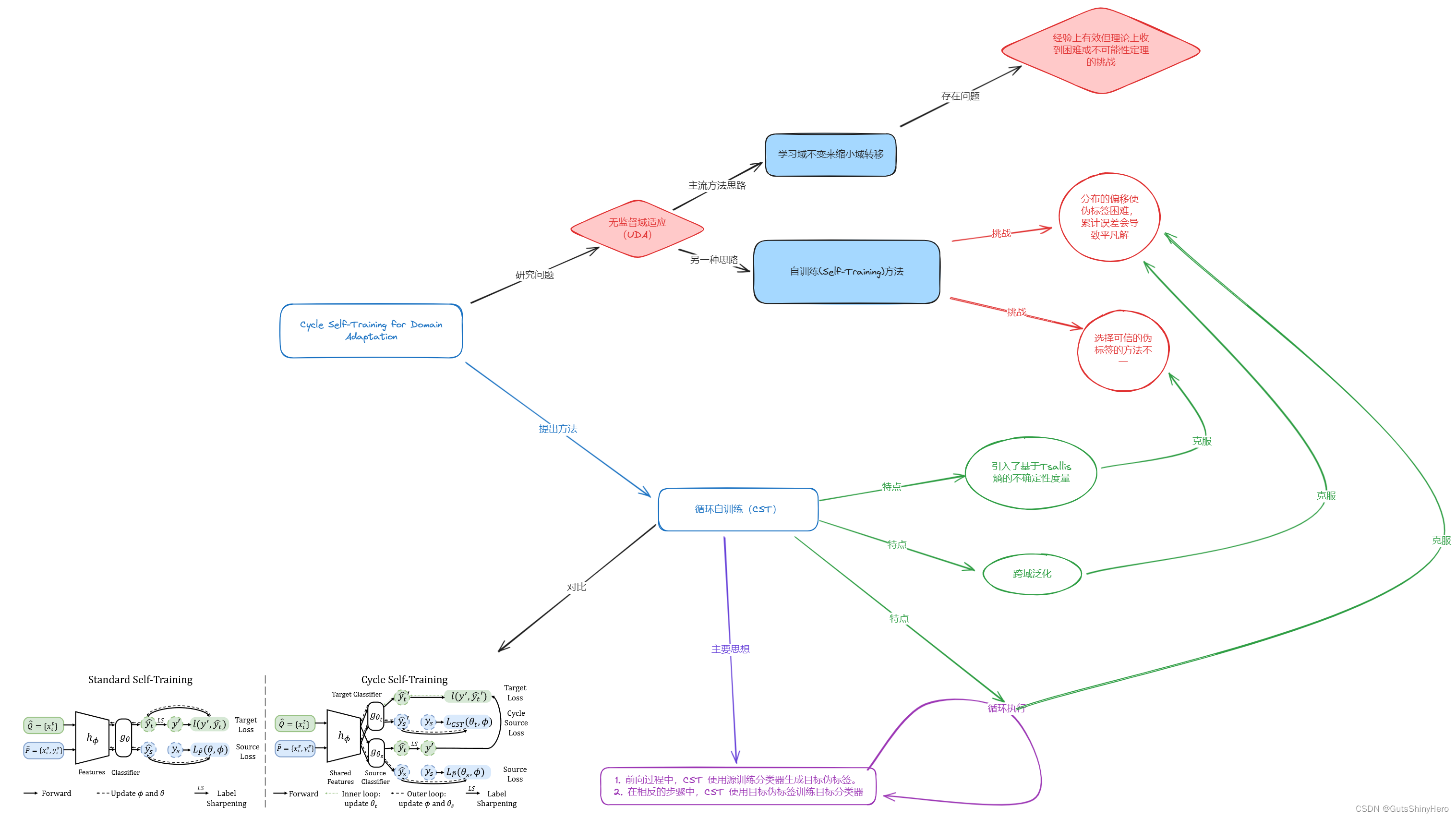
结论(Conclusion)
建议用循环自我训练代替标准自我训练,以明确解决领域适应中的分布变化。通过实验证明了该方法在扩展假设下有效,并演示了特征适应和标准自我训练的困难案例。自我训练(或伪标签)只是半监督学习文献中的一系列工作。未来的工作可以深入研究其他半监督学习技术的行为,包括分布变化下的一致性正则化和数据增强,并广泛利用它们进行领域适应。
先验知识-什么是无监督域适应(UDA)
可以参考文章域适应的背景,理论与方法
考虑输入标签空间
X
×
Y
{\mathcal{X}}\times{\mathcal{Y}}
X×Y 上的源分布
P
P
P 和目标分布
Q
Q
Q。
假设现在有来自
P
P
P的已标记的
n
s
n_s
ns个样本
P
^
=
{
x
i
s
,
y
i
s
}
i
=
1
n
s
\widehat{P} = \{x_i^s,y_i^s\}_{i=1}^{n_s}
P
={xis,yis}i=1ns 和来自
Q
Q
Q的已标记的
n
t
n_t
nt个样本
Q
^
=
{
x
i
t
}
i
=
1
n
t
\widehat{Q} = \{x_i^t\}_{i=1}^{n_t}
Q
={xit}i=1nt 。模型
f
f
f 包括参数化的特征提取器
h
ϕ
h_{\phi}
hϕ 和参数化的head(线性分类器)
g
θ
g_{\theta}
gθ,即
f
θ
,
ϕ
(
x
)
=
g
θ
(
h
ϕ
(
x
)
)
{f}_{\theta,\phi}(x)=g_\theta(h_\phi(x))
fθ,ϕ(x)=gθ(hϕ(x))。损失函数为
ℓ
(
⋅
,
⋅
)
\ell(\cdot,\cdot)
ℓ(⋅,⋅)。
L
P
(
θ
,
ϕ
)
:
=
E
(
x
,
y
)
∼
P
ℓ
(
f
θ
,
ϕ
(
x
)
,
y
)
L_{P}(\theta,\phi):=\mathbb{E}_{(x,y)\sim P}\ell(f_{\theta,\phi}(x),y)
LP(θ,ϕ):=E(x,y)∼Pℓ(fθ,ϕ(x),y)表示
P
P
P 上的预期误差。
使用
L
P
^
(
θ
,
ϕ
)
L_{\widehat{P}}(\theta,\phi)
LP
(θ,ϕ) 表示数据集
P
^
\widehat{P}
P
上的经验误差。
主流的 UDA 方法:特征自适应
特征适应在源数据集
P
^
\widehat{P}
P
上训练模型
f
f
f,并同时匹配表示空间
Z
=
h
(
X
)
\mathcal{Z}=h(\mathcal{X})
Z=h(X) 中的源分布和目标分布
其目标函数可表示为:
min
θ
,
ϕ
L
P
^
(
θ
,
ϕ
)
+
d
(
h
♯
P
^
,
h
♯
Q
^
)
\min_{\theta,\phi}L_{\widehat P}(\theta,\phi)+d(h_\sharp\widehat P,h_\sharp\widehat Q)
θ,ϕminLP
(θ,ϕ)+d(h♯P
,h♯Q
)
这里,
h
♯
P
^
h_\sharp\widehat P
h♯P
表示
P
^
\widehat P
P
的前推分布,
d
(
⋅
,
⋅
)
d(·,·)
d(⋅,⋅)是某个分布距离。这种方法的关键就是选择合适的分布距离和前向集合表示。
主流的 UDA 方法:自训练。
自训练方法的关键是伪标签。
源于半监督学习,标准自训练在源数据集
P
^
\widehat P
P
上训练源模型
f
s
f_s
fs :
min
θ
s
,
ϕ
s
L
P
^
(
θ
s
,
ϕ
s
)
\min_{\theta_s,\phi_s}L_{\widehat{P}}(\theta_s,\phi_s)
minθs,ϕsLP
(θs,ϕs)。然后,目标伪标签由目标数据集
Q
^
\widehat Q
Q
上的
f
s
f_s
fs生成。为了利用未标记的目标数据,自训练在源数据集和目标数据集上以及源真实值和目标伪标签上训练模型:
min
θ
,
ϕ
L
P
^
(
θ
,
ϕ
)
+
E
x
∼
Q
^
ℓ
(
f
θ
,
ϕ
(
x
)
,
arg
max
i
{
f
θ
s
,
ϕ
s
(
x
)
[
i
]
}
)
\min_{\theta,\phi}L_{\widehat{P}}(\theta,\phi)+\mathbb{E}_{x\sim\widehat{Q}}\ell(f_{\theta,\phi}(x),\arg\max_{i}\{f_{\theta_{s},\phi_{s}}(x)_{[i]}\})
θ,ϕminLP
(θ,ϕ)+Ex∼Q
ℓ(fθ,ϕ(x),argimax{fθs,ϕs(x)[i]})
自训练模型的缺憾
-
域偏移发生时,伪标签分布与真实标签显著不同
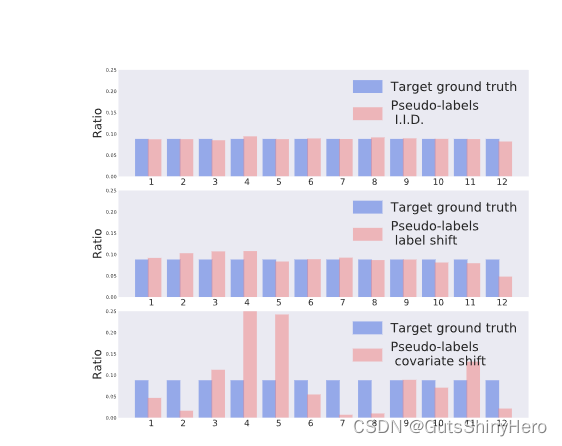
-
随着训练的进行,源域和目标域之间伪标签的分布差异几乎不变
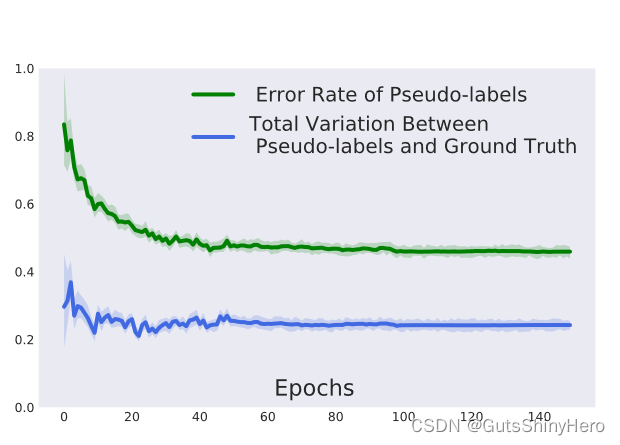
-
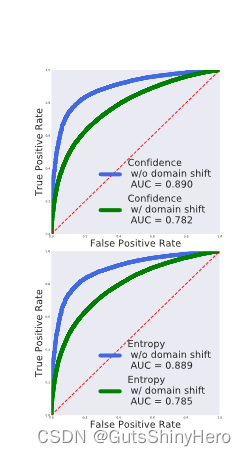
在域偏移下很难选择可信标签
主体工作
循环自训练的基本方法
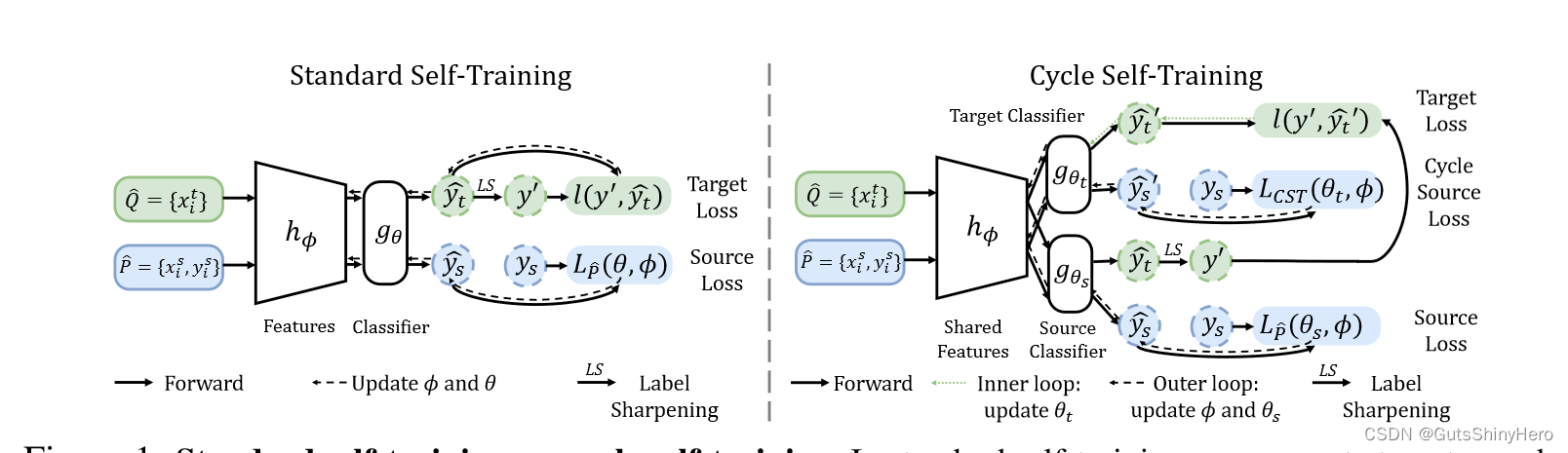
前向步
与标准的自训练类似,我们有一个源分类器,在标记源域的共享表示之上进行训练,并使用它来生成目标伪标签,如下所示
y
′
=
arg
max
{
f
θ
s
,
ϕ
(
x
)
[
i
]
}
y'=\arg\max\{f_{\theta_s,\phi}(x)_{[i]}\}
y′=argmax{fθs,ϕ(x)[i]}
传统的自我训练方法使用置信度阈值或重新加权来选择可靠的伪标签。然而,深度网络的输出通常是错误校准的,并且即使在相同的分布上也不一定与真实可信度相关。在域适应中,源域和目标域之间的差异使得伪标签更加不可靠,并且常用的选择策略的性能也不尽如人意。另一个缺点是为了找到新任务的最佳置信阈值而进行昂贵的调整。为了更好地将自我训练应用于领域适应,我们期望模型能够自行逐步细化伪标签,而无需进行繁琐的选择或阈值处理。
后向步
根据以下见解设计了一个补充步骤来改进自我训练。
直观上,源域上的标签既包含可以传输到目标域的有用信息,也包含可以使伪标签不正确的有害信息。类似地,目标域上可靠的伪标签可以依次转移到源域,而目标域上使用不正确的伪标签训练的模型则无法转移到源域。从这个意义上说,如果我们明确地训练模型以使目标伪标签提供源域的信息,我们就可以逐渐使伪标签更加准确并学习泛化到目标域。
根据前向步的分类器,生成的伪标签
y
′
y'
y′,在目标域
Q
^
\widehat Q
Q
上训练一个目标头:
θ
^
t
(
ϕ
)
=
arg
min
E
x
∼
Q
^
ℓ
(
f
θ
,
ϕ
(
x
)
,
y
′
)
\hat{\theta}_t(\phi)=\arg\min\mathbb{E}_{x\sim\widehat{Q}}\ell(f_{\theta,\phi}(x),y')
θ^t(ϕ)=argminEx∼Q
ℓ(fθ,ϕ(x),y′)
我们希望使目标伪标签能够提供源域的信息并逐渐细化它们。为此,我们更新共享特征提取器以在源域上准确预测,并联合强制目标分类器
θ
^
t
(
ϕ
)
\hat{\theta}_t(\phi)
θ^t(ϕ) 在源域上表现良好。这自然导致了循环自我训练的目标:
minimize
θ
s
,
ϕ
L
Cycle
(
θ
s
,
ϕ
)
:
=
L
P
^
(
θ
s
,
ϕ
)
+
L
P
^
(
θ
^
t
(
ϕ
)
,
ϕ
)
\text{minimize }_{\theta_s,\phi}L_\text{Cycle}(\theta_s,\phi):=L_{\widehat P}(\theta_s,\phi)+L_{\widehat P}(\hat\theta_t(\phi),\phi)
minimize θs,ϕLCycle(θs,ϕ):=LP
(θs,ϕ)+LP
(θ^t(ϕ),ϕ)
双层的优化策略
minimize
θ
s
,
ϕ
L
Cycle
(
θ
s
,
ϕ
)
:
=
L
P
^
(
θ
s
,
ϕ
)
+
L
P
^
(
θ
^
t
(
ϕ
)
,
ϕ
)
\text{minimize }_{\theta_s,\phi}L_\text{Cycle}(\theta_s,\phi):=L_{\widehat P}(\theta_s,\phi)+L_{\widehat P}(\hat\theta_t(\phi),\phi)
minimize θs,ϕLCycle(θs,ϕ):=LP
(θs,ϕ)+LP
(θ^t(ϕ),ϕ) relies on the solution
θ
^
t
(
ϕ
)
\hat{\theta}_t(\phi)
θ^t(ϕ) to the objective in
θ
^
t
(
ϕ
)
=
arg
min
E
x
∼
Q
^
ℓ
(
f
θ
,
ϕ
(
x
)
,
y
′
)
\hat{\theta}_t(\phi)=\arg\min\mathbb{E}_{x\sim\widehat{Q}}\ell(f_{\theta,\phi}(x),y')
θ^t(ϕ)=argminEx∼Q
ℓ(fθ,ϕ(x),y′).Thus,CST formulates a
b
i
−
l
e
v
e
l
bi-level
bi−level optimization problem.
在内层循环中:每一次通过源域分类器生成伪标签,然后利用目标域伪标签训练一个目标域分类器。
在每组内层循环迭代完成后,更新一次特征提取器。
然而,由于等式 4 中优化的内循环仅涉及轻量级 Iinear 头
θ
t
\theta_t
θt,因此我们建议计算
θ
^
t
(
ϕ
)
\hat{\theta}_t(\phi)
θ^t(ϕ) 的解析形式并直接反向传播到特征提取器
ϕ
\phi
ϕ,而不是像 MAML 中那样计算二阶导数。
由此产生的框架就像联合训练两个头一样快。另请注意,解决方案
θ
^
t
(
ϕ
)
\hat{\theta}_t(\phi)
θ^t(ϕ) 通过
y
′
.
y^\prime.
y′. 隐式依赖于
θ
s
\theta_s
θs
然而,标准的自训练和我们的实现都使用标签锐化,使得
y
′
y^{\prime}
y′ 不可微分因此,我们遵循 vanilla 自训练并且不考虑
θ
^
t
(
ϕ
)
\hat{\theta } _t( \phi )
θ^t(ϕ) w.r.t.
y
′
y^\prime
y′ 的梯度
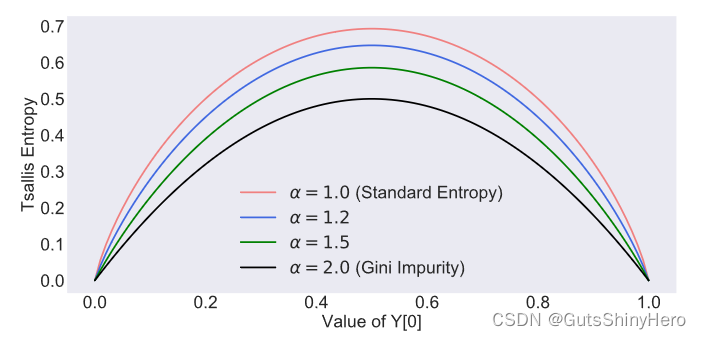
Tsallis 熵最小化
Gibbs 熵被现有的半监督学习方法广泛使用,以规范模型输出并最小化对未标记数据的预测的不确定性。在本文中中,我们将信息论中的 Gibbs 熵推广为 Tsallis 熵。
假设
y
∈
R
K
y\in\mathbb{R}^{K}
y∈RK是模型的softmax输出,将
α
−
Tsallis
\alpha-\text{Tsallis}
α−Tsallis熵定义为:
S
α
(
y
)
=
1
α
−
1
(
1
−
∑
y
[
i
]
α
)
S_\alpha(y)=\frac1{\alpha-1}\left(1-\sum y_{[i]}^\alpha\right)
Sα(y)=α−11(1−∑y[i]α)
其中
α
\alpha
α被称为熵指数。
注意:
lim
α
→
1
S
α
(
y
)
=
∑
i
−
y
[
i
]
l
o
g
(
y
[
i
]
)
\lim_{\alpha\to1}S_{\alpha}(y) = \sum_{i}-y_{[i]}\mathrm{log}(y_{[i]})
limα→1Sα(y)=∑i−y[i]log(y[i])即是Gibbs 熵,若
α
=
2
\alpha=2
α=2,即
1
−
∑
i
y
[
i
]
2
1-\sum_iy_{[i]}^2
1−∑iy[i]2为Gini熵,
如下图:
目标伪标签控制
由此提出了基于 Tsallis 熵最小化来控制目标伪标签的不确定性:
L
Q
^
,
Tsallis
,
α
(
θ
,
ϕ
)
:
=
E
x
∼
Q
^
S
α
(
f
θ
,
ϕ
(
x
)
)
L_{\widehat{Q},\text{Tsallis},\alpha}(\theta,\phi):=\mathbb{E}_{x\sim\widehat{Q}}S_{\alpha}(f_{\theta,\phi}(x))
LQ
,Tsallis,α(θ,ϕ):=Ex∼Q
Sα(fθ,ϕ(x))
Tsallis 熵相对于 Gibbs 熵的一个重要改进是,它可以为不同的系统选择合适的不确定性度量,以避免因过度惩罚不确定的伪标签而导致的过度置信度。为了自动找到合适的
α
\alpha
α,我们采用了与第 3.1 节类似的策略。直觉是,如果我们使用合适的熵索引
α
\alpha
α 来训练源分类器
θ
s
,
α
\theta_{s,\alpha}
θs,α,则由
θ
s
,
α
\theta_s,\alpha
θs,α 生成的目标伪标签将包含源数据集的理想知识,例如,用这些伪标签训练的目标分类器
θ
t
,
α
\theta_{t,\alpha}
θt,α 在源域上表现良好 因此,我们半监督训练分类器
θ
^
s
~
,
α
\hat{\theta}_{\tilde{s},\alpha}
θ^s~,α 在源域上,目标域上的
α
\alpha
α-Tsallis 熵正则化
L
Q
^
,Tsallis,
α
L_{\widehat{Q},\text{Tsallis},\alpha}
LQ
,Tsallis,α 为:
θ
^
s
,
α
=
arg
min
θ
L
P
^
(
θ
,
ϕ
)
L
Q
^
,Tsallis,
α
(
θ
,
ϕ
)
\hat{\theta}_{s,\alpha}=\arg\min_{\theta}L_{\widehat{P}}(\theta,\phi) L_{\widehat{Q},\text{Tsallis},\alpha}(\theta,\phi)
θ^s,α=argθminLP
(θ,ϕ)LQ
,Tsallis,α(θ,ϕ),我们从中得到目标伪标签。然后我们用目标伪标签训练另一个头
θ
^
t
,
α
\hat{\theta}_{t,\alpha}
θ^t,α 我们通过最小化源数据上
θ
^
t
,
α
\hat{\theta}_{t,\alpha}
θ^t,α 的损失来自动找到
α
\alpha
α:
α
^
=
arg
min
α
∈
[
1
,
2
]
L
P
^
(
θ
^
t
,
α
,
ϕ
)
\hat{\alpha}=\arg\min_{\alpha\in[1,2]}L_{\widehat{P}}(\hat{\theta}_{t,\alpha},\phi)
α^=argα∈[1,2]minLP
(θ^t,α,ϕ)
将熵正则化加入后,可以得到最终目标:
min
θ
s
,
ϕ
ize
L
Cycle
(
θ
s
,
ϕ
)
+
L
Q
^
,
Tsallis
,
α
^
(
θ
s
,
ϕ
)
\min_{\theta_s,\phi}\text{ize}L_\text{Cycle}(\theta_s,\phi)+L_{\widehat{Q},\text{Tsallis},\hat{\alpha}}(\theta_s,\phi)
θs,ϕminizeLCycle(θs,ϕ)+LQ
,Tsallis,α^(θs,ϕ)
确定这个目标之后,可以得出最终算法:

实验结果(Evaluation)
实验设置
数据集
在视觉对象识别和语言情感分类任务上进行实验:
- Office-Home 有 65 个类别,来自四种领域差距较大的环境:艺术 (Ar)、剪贴画 (Cl)、产品 (Pr) 和真实 -世界(Rw);
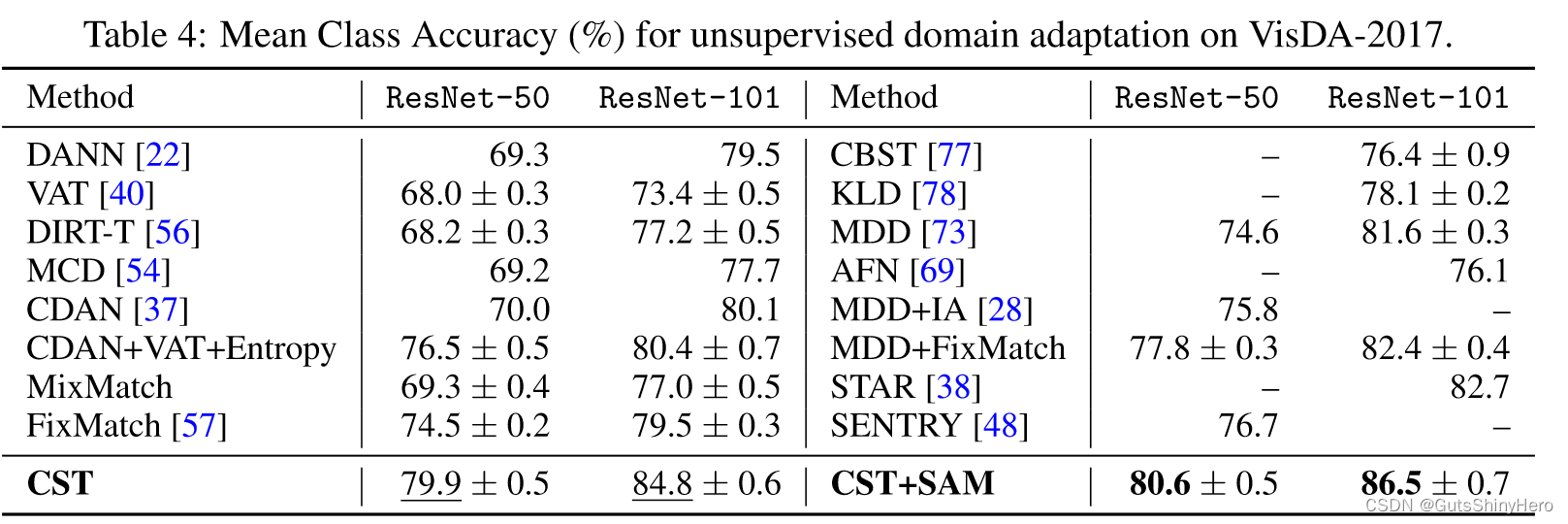
- VisDA-2017 是一个大型 UDA 数据集,具有两个名为 Synthetic 和 Real 的域。数据集包含来自 12 类物体的超过 20 万张图像; Amazon Review [10] 是四种产品的产品评论的语言情感分类数据集:书籍 (B)、DVD (D)、电子产品 (E) 和厨房 (K)。
实现
- 使用 ResNet-50 (在 ImageNet [53] 上预训练)作为视觉任务的特征提取器,并使用 BERT作为语言任务。
- 在 VisDA-2017 上,我们还提供了 ResNet101 的结果以包含更多基线。我们使用交叉熵损失在源域上进行分类。当训练目标头 θ ^ t \hat{\theta}_{t} θ^t 并用 CST 更新特征提取器时,我们使用平方损失直接获得 θ ^ t \hat{\theta}_{t} θ^t 的解析解,避免像元学习一样计算二阶导数 。我们采用初始学习率 η 0 = 2 e − 3 \eta_0=2e-3 η0=2e−3 的 SGD 进行图像分类,采用 η 0 = 5 e − 4 \eta_0=5e-4 η0=5e−4 进行情感分类。
- 遵循标准协议,我们每 50 个epochs将学习率衰减 0.1,直到 150 个epochs。
- 运行所有任务 3 次,并报告 top-1 准确度的平均值和偏差。
对于 VisDA-2017,展示平均类别准确度。
根据定理 2,我们还通过锐度感知正则化 (CST+SAM) 增强 CST,这有助于规范函数类的 Lipschitzness。
Baselines
比较领域适应中的两条工作:特征适应和自我训练
Feature Adaptation
DANN 、MCD、CDAN(通过伪标签条件改善 DANN)、MDD (通过边缘理论改善先前的域适应)、隐式对齐(IA)(改进了 MDD 来处理标签偏移)
Self-Training
我们在半监督学习文献中将 VAT 、MixMatch和 FixMatch作为自我训练方法。我们还与 UDA 的自训练方法进行比较:CBST ,它考虑标准自训练中的类不平衡,以及 KLD,它通过标签正则化改进 CBST。然而,这些方法涉及为卷积网络指定的技巧。因此,在我们使用 BERT 主干的情感分类任务中,我们与其他一致性正则化基线进行比较:VAT、VAT+熵最小化。
Feature Adaptation + Self-Training
DIRT-T [56] 结合了 DANN、VAT 和熵最小化。我们还创建了更强大的基线:CDAN+VAT+Entropy 和 MDD+Fixmatch
Other SOTA
AFN 通过大范数提高了可转移性。 STAR 将域与随机分类器对齐。 SENTRY通过随机增强委员会选择可信示例。
结果
表 2 显示了 12 对 Office-Home 任务的结果。当域转移较大时,VAT 和 FixMatch 等标准自训练方法会遭受伪标签质量下降的影响。 CST 在 12 项任务中的 9 项中显着优于特征适应和自我训练方法。请注意,CST 不涉及手动设置置信度阈值或重新加权。
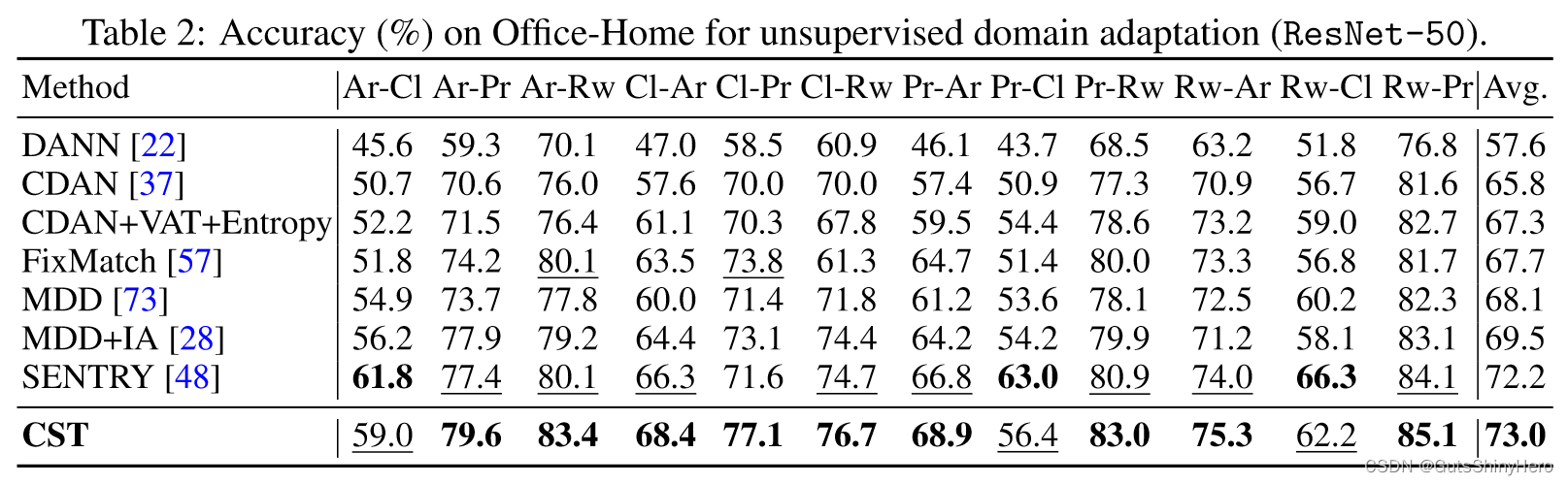
表 4 显示了 VisDA-2017 上的结果。 CST 凭借 ResNet-50 和 ResNet101 主干网络超越了最先进的技术。我们还结合了特征适应和自训练(DIRT-T、CDAN+VAT+熵和MDD+FixMatch)来测试特征适应是否减轻了标准自训练中域转移的负面影响。结果表明,CST 是比简单组合更好的解决方案。虽然大多数传统的自训练方法包括为 ConvNet 指定的技术,例如 Mixup [72],但 CST 是一种通用方法,只需替换 BERT [16] 的头部和训练目标即可直接进行情感分类。
在表 3 中,大多数特征适应基线仅比源代码略有改善,但 CST 在大多数任务上显着优于所有基线
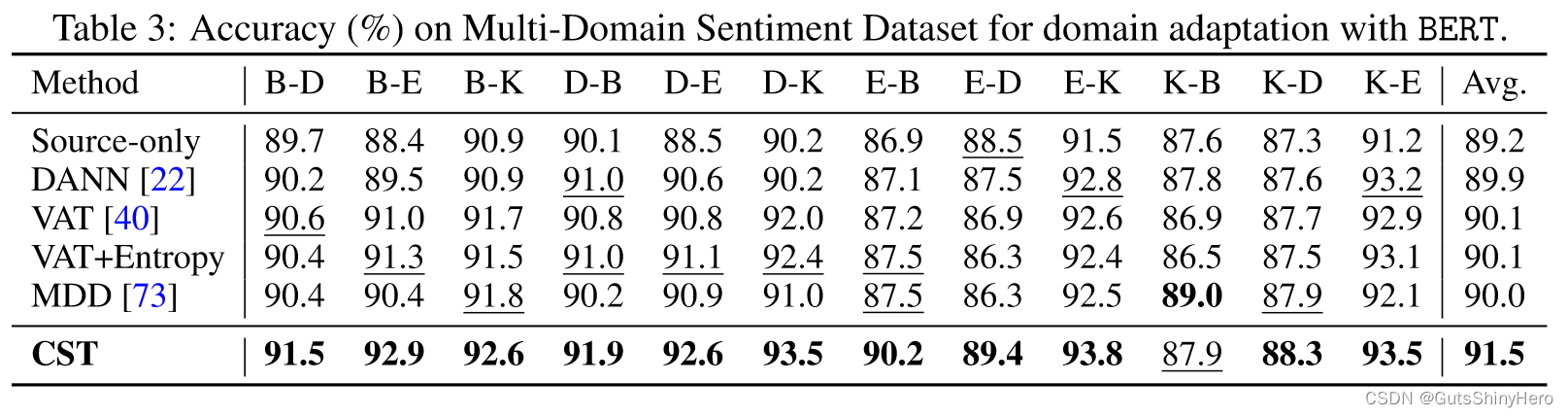
数据分析
-
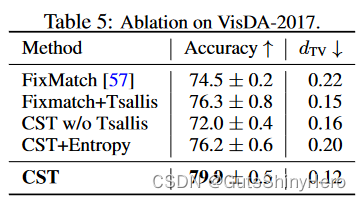
消融实验
观察结果如表 5 所示。CST+熵的表现比 CST 差 3.7%,这表明 Tsallis 熵是比标准熵更好的伪标签正则化。 CST 的性能比 FixMatch 好 5.4%,这表明 CST 比标准自训练更好地适应域转移。虽然 FixMatch+Tsallis 优于 FixMatch,但仍落后 CST 3.6%,伪标签和真实值之间的总变异距离 d T V d_{TV} dTV 更大,表明 CST 使伪标签在域转移下比标准自训练更可靠.
CST w/o Tsallis 删除了 Tsallis 。 CST+Entropy 将 Tsallis 熵替换为标准熵.
-
伪标签的质量
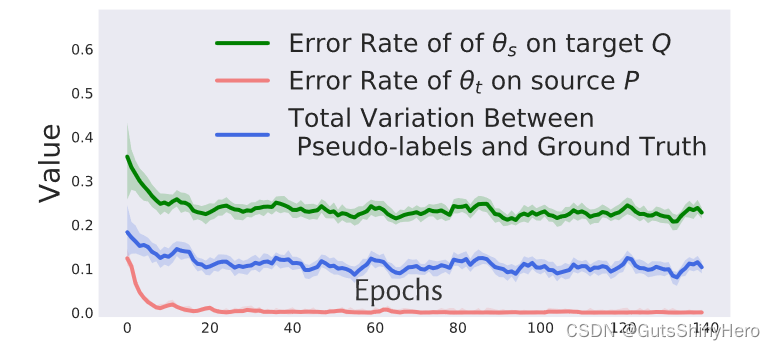
图中显示的是VisDA-2017 训练期间伪标签的错误。当伪标签的误差和伪标签与真实标签之间的总变异(
d
T
V
d_{TV}
dTV)距离继续减小时,源域上的目标分类器的误差在训练中迅速减小衰减,表明 CST 逐渐细化伪标签。
3. Gibbs熵和 Tsallis 熵的比较。
将 Ar->Cl 上的标准 Gibbs 熵和 Tsallis 熵学习到的伪标签与 ResNet-50 在 epoch 40 上进行比较。我们计算每个目标示例的最大和第二大 softmax 分数之间的差异,并绘制直方图如下:![[Pasted image 20240516211350.png]]Gibbs熵使得最大的softmax输出接近1,表明过度自信。在这种情况下,如果预测错误,则很难使用自我训练来纠正它。相比之下,Tsallis 熵允许最大和第二大分数相似。


















 1703
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









