






一、线性神经网络
回归是能为一个或多个自变量与因变量之间建模的一类方法。其主要包括线性回归与softmax回归。线性回归的输出往往是预测一个连续值,而softmax回归虽然叫做回归,但其实是一个分类任务,其输出往往是预测一个离散的值。
1:线性回归
线性回归最经典的例子便是预测房价了,根据样本的特征数量,分别给予不同的权重,再加上一个偏置项,来表达我们的预测模型。线性模型的具体形式如下:
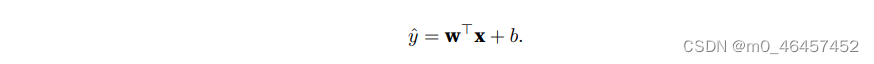
机器学习的任务便是寻找一组最好的模型参数w与b,但为了完成这个任务,我们需要两件工具。一是评估模型的度量方式;二是可以更新模型以提高预测质量的方法。
(1):损失函数
损失函数的任务便是上述第一个工具,它能量化目标的实际值与预测值之间的差距。其形式如下: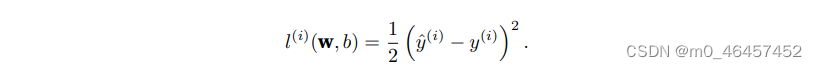
训练模型时,我们希望寻找一组参数w与b能够最小化所有训练样本上的总损失。
(2):最小化损失函数的解法
求解方式有两种方法:正规方程法与梯度下降法。
正规方程法对问题的限制很严格,无法广泛应用于深度学习中,更常用的是梯度下降法。值得一提的是,梯度下降法恰恰便是上述的第二个工具,它可以更新参数。
2:softmax回归
在现实生活中,我们往往还会面对这一类问题,对于给定的输入,例如不同的图像,我们只想知道图像属于哪一类,这便是softmax回归。与线性回归不同,我们的任务是给与它一个标签。
为了在数学形式上表示我们的分类问题,统计学家给出了一种表示分类数据的简单方法:独热编码。
对于一个小批量的样本X,其中特征维度为的d,批量大小为n。其矢量计算表达式为: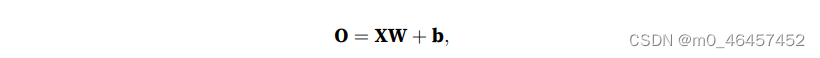
可是,在这个形式下,我们的输出会是一个个无法与概率联系起来的值。因此我们需要一种变换方式 ,将输出变为概率。它得保证任何数据上的输出都非负,且总和为1。这一变换方法便是softmax运算。

因此,我们的模型变为:
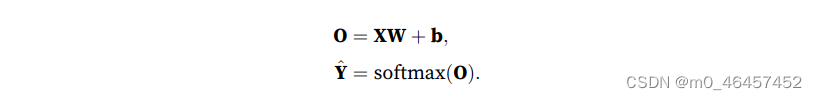
(1):损失函数
与线性回归一样,我们需要一个损失函数来度量模型的好坏。在softmax回归任务中,它的形式为:
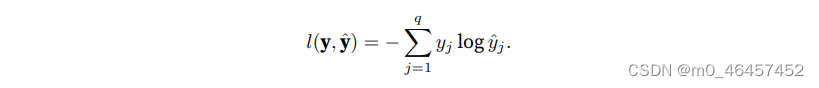
它也通常被称为交叉熵损失。
求解最小化损失函数的方法依然是梯度下降法。
二、多层感知机
最简单的深度网络就叫做多层感知机。以softmax回归作为对比,它是一个单层的神经网络。输入层直接连接到输出层。
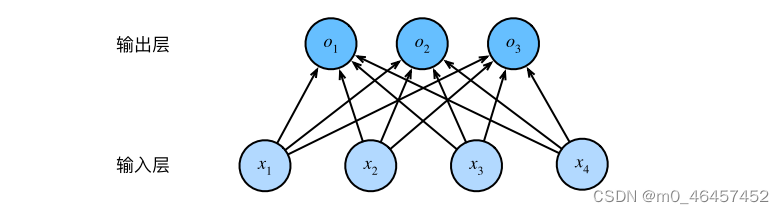
而多层感知机与之不同的地方在于,它加入了隐藏层。对于加入隐藏层的原因我们不做深入探讨,但加入隐藏层后的影响与变化我们需要仔细研究。
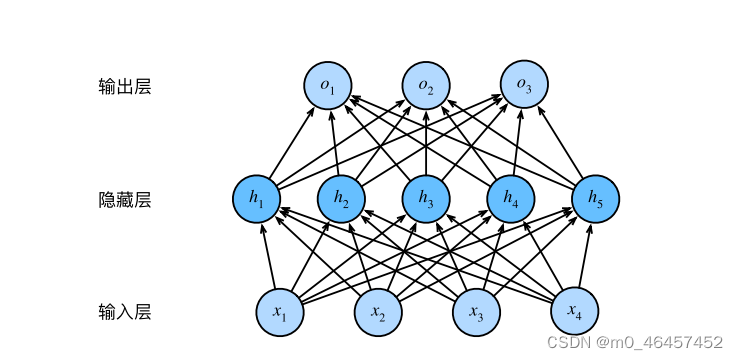
若是只单纯的添加隐藏层,新的模型似乎对我们没有任何好处,因为它不仅为我们带来了更多的参数,而且只需要合并隐藏层,他便可以等价于一个单层网络!为了发挥它的价值,我们需要在每一次仿射变换后添加一个激活函数。有了他的存在,多层感知机便不能退化成线性模型了。
常用的激活函数是ReLU函数,它被称作修正线性单元。
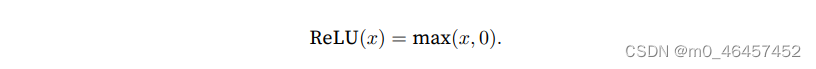
它的函数图像长这样:
使用ReLU的一个重要原因是,它的求导表现特别好,这减轻了神经网络的梯度消失问题。
未完待续。。。
注:本文所有图片均来自于此书《动手学深度学习》















 973
973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









