









资料下载
论文下载:DropBlock: A regularization method for convolutional networks
一、简介
DropBlock是一种正则化技术,用于防止深度神经网络的过拟合。它通过在训练过程中随机丢弃网络中的一部分特征图,来增加模型的泛化能力。
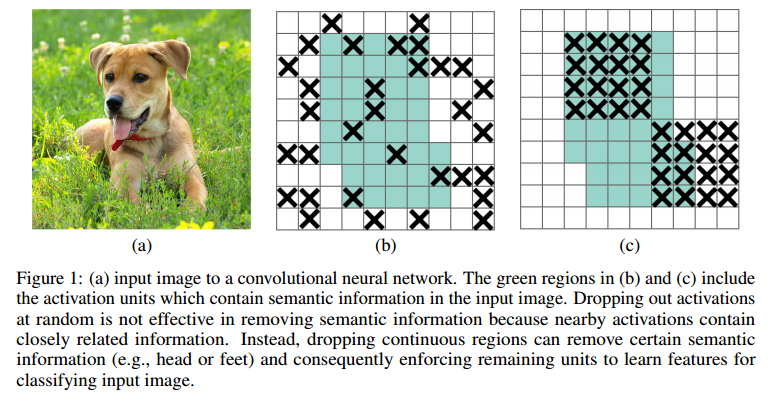
文章中分析了传统的dropout在conv上效果不好的原因:conv具有空间相关性,所以即使对一些单元随机进行dropout,仍然可以有信息流向后面的网络,导致dropout不彻底。
针对这个问题,作者提出了DropBolck这一方法,思想很简单:从名字就可以看出来,既然随机丢弃独立的单元可能导致丢弃不彻底,那不如一次丢弃一个block,该block内的单元在空间上是相关的。
研究发现除了在conv层中使用Dropblock外,在skip connections中应用可以提高精度。
二、原理
DropBlock的工作原理是在训练过程中,以一定的概率随机地将特征图中的某些区域置为零,从而减少这些区域对模型输出的贡献。这种随机性使得模型在训练过程中不会总是依赖相同的特征区域,从而提高模型的泛化能力。
DropBlock有两个主要的参数:block_size和γ。
block_size参数控制被丢弃的特征区域的大小,
γ参数控制被丢弃的特征区域的比例。
在实现上,DropBlock通常在卷积层之后、全连接层之前使用,以保持对输入特征图的依赖性。

三、DropBlock与DropOut的区别
1. DropBlock和DropOut之间的主要区别在于它们处理过拟合的方式。
DropOut是一种在训练期间随机地“关闭”网络中的一部分神经元的技术,通过减少神经元的数量来防止过拟合。相比之下,DropBlock的工作方式略有不同,DropBlock并不是简单地将整个神经元丢弃,而是随机地丢弃特征图中的一部分区域(Block)。这种局部丢弃的方式可以更好地保留输入数据的结构信息,从而在某些任务上取得更好的性能。
2. DropBlock从某层的feature map中删除相邻区域,而不是随机独立地删除单元。这意味着DropBlock会随机地选择并丢弃特征图中的连续区域,而不是单独的神经元。这种方法能够更好地保留输入数据的结构信息,因为它不会破坏特征图中的相邻关系。
总的来说,DropBlock和DropOut都是有效的正则化技术,能够帮助防止神经网络的过拟合,提高模型的泛化能力。然而,它们的处理方式和应用场景略有不同,DropOut侧重于独立地“关闭”神经元,而DropBlock则更侧重于处理特征图的区域。在实际应用中,根据具体的任务和数据集选择合适的方法可能更为关键。
四、代码实现DropBlock
import torch
import torch.nn as nn
import torch.nn.functional as F
class DropBlock(nn.Module):
def init(self, block_size, drop_ratio):
super(DropBlock, self).init()
self.block_size = block_size
self.drop_ratio = drop_ratio
def forward(self, x):
if self.training:
batch_size, channels, height, width = x.size()
mask = torch.ones(batch_size, channels, height, width).cuda()
for i in range(self.block_size):
mask[:, :, i::self.block_size, i::self.block_size] = 0
mask = mask.view(batch_size, channels, -1)
mask = mask[:, :, self.block_size // 2:]
mask = mask[:, :, ::-1]
mask = mask.view(batch_size, channels, height, width)
prob = self.drop_ratio / (self.block_size ** 2)
x = x * mask * prob + (1 - mask) * x
return x在上面的代码中,定义了一个DropBlock类,它包含一个初始化函数和前向传播函数。在初始化函数中,定义了块大小和丢弃率。
在向前传播函数中,首先检查模型是否处于训练模式。如果是,则生成一个与输入张量大小相同的掩码张量,其中块区域被设置为零。
然后,将掩码张量重塑为二维张量,并仅保留中间的块区域。
接下来,将掩码张量转置并重新将其重塑为原始形状。
最后,将概率计算为丢弃率除以块大小的平方,并使用掩码将输入张量的相应部分替换为零或原始值。最终输出为使用掩码和概率缩放后的输入张量。
















 6992
6992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









